
✖
![]()
![]()
![]()
![]()
![]()
![]()
Perl には Test::TCP というのがあって、テスト中、空いてるポートで何かしらのサーバーを起動して使うということができます。Ruby においては Glint というライブラリがあって、同じことができます。
node.js の場合、node-test-tcp というのがあって、node の net.Server で動くサーバに関しては簡単に同じことができます。が、memcached とか外部プロセスを起動させようとするとちょっと困るのと、done() を呼ばないと終了しないので、何かいい方法はないかなと思ったので書いてみました。
test-tcp だとカブるので glint のほうの名前を仮りています。
glint(
function (port) {
// ここは外部プロセスで実行される
// ただし文字列化して関数が渡されるので外のスコープの変数は使えない。
// node.js の exec, execFile はいわゆる exec ではないので1つプロセスが余分にできる。我慢するしかない。
console.log('starting memcached with port: ' + port);
require('child_process').execFile('memcached', ['-p', port]);
},
function (error, server) {
if (error) throw error;
// server は起動が確認済み
// server.port でポート番号がとれる。
// server.kill() でこのプロセスだけ殺せる
console.log(server);
var s = net.connect(server.port, function () {
s.write("version\r\n");
});
s.on('data', function (data) {
console.log(data.toString('UTF-8'));
s.end();
});
// この関数を抜けても exit されるまで server は (明示的にkillしない限り) kill されない
}
); 他のモジュールとやってることは一緒なのですが、node.js だと面倒な点がいくつかあります
node の fork / exec (execFile) は *nix の fork / exec とは全く違うので、細かいプロセスの制御ができません。特に exec 単体相当はないので、現在のプロセス自体を置き換えるということができません。そんなわけで1つ別プロセスを経由している関係で、無駄に1プロセスを消費しています。
オブジェクトのファイナライザがないので、node-glint では process.on('exit') で起動したサーバを終了しています。ただし、普通に外部プロセスを起動すると、そのプロセスの終了を待つ挙動になり、exit されません。が、spawn() のオプションに detach: true を指定した上で、unref() を呼んであげることで、外部プロセスの終了に関わらず起動元の node プロセスを exit させることができます。
一応形にはなりましたが、細かい挙動の検証がめんどうなので npm にあげてません。特に現在の実装はシグナルまわりのハンドリングがいい加減です。node マスターの皆様におかれましては、よりよい方法をご教示頂ければと思う所存です。
![]()
![]()
![]()
とりあえず、2種類のテストがあり、どちらも十分なサポートがされている。
基本的にangular-seedというのを元に作ればいいんだけど、e2e (end to end) テストについては protractor というのを使うのが新しいようなので、今からはじめるならそちらを使ったほうが良い。
node で完結する、ロジックの単体テスト。主に controller とか filter をテストする。controller で DOM を直でいじっていると実行できない。
サーバサイドとかとの通信とかは全てモックにしなければならない。Angular の DI の仕組みで、モックオブジェクトを外部から注入して単体テストを完結させる。
いろいろ面倒くさいけど、これを書くようにすることで controller / directive の使いわけとかを意識せざるを得なくなるので良い気がする。
selenium を使った結合テスト。
protractor は Angular JS 用の e2e テストライブラリ。簡単に selenium-standalone をセットアップするところから、テスト用のユーティリティまでのセット。ドキュメント の通りにやれば OS X では全く苦もなく selenium 環境を作りテストを開始できる。
どこが「Angular JS用」なのかというと、ページロードとか、イベント発火とかで、いちいち自分で wait() を書く必要がなく、Angular 準拠の部分は自動で処理待ちをするので、かなり楽をできる。
ので、パターンを網羅したロジックは書きたいなら karma で完結するように書いたほうがいい。
![]()
![]()
![]()
protractor (webdriver) を使った場合、外から executeAsyncScript を使うと文字列でページ側で実行できる。
けど、文字列で渡すとか、シンタックスチェックもかからないし、ありえないので、定義自体は普通に書きたい。ので以下のような関数を定義する。
var PageObject = function () {
this.exec = function (func) {
var args = Array.prototype.slice.call(arguments, 0);
args[0] = '('+ (func.toString()) + ').apply(null, arguments);';
browser.executeAsyncScript.apply(browser, args);
};
this.createEntry = function (data) {
this.exec(function (data, callback) {
angular.injector(['myApp']).invoke(function (Entry) {
var entry = new Entry();
for (var key in data) if (data.hasOwnProperty(key)) entry[key] = data[key];
entry.$save(callback);
});
}, data);
return data;
};
}; この例では、定義した exec 関数を使って、ページ側の ngResource で定義したクラスを使い、テスト用のデータを生成する createEntry メソッドを定義している。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()

12月10日に受験して、12月24日の合格発表と同時に申請を出し、免許日は1月9日で、それから2日後には不在票 (書留にしたので) が入ってた。思ったより早かった。営業日的には7日ぐらいかな。
今まで持っていたやつはラミネート加工されたやつだったけど、新しい形式になっていわゆるカードサイズになったのと、英語表記が併記されるようになった (電波の性質上、国際的に使われうる免許だからかな) のと、ホログラム (富士山と桜?) っぽいものが全面に入るようになったみたい。

![]()
![]()
![]()
![NEC Aterm WR9500N[HPモデル] PA-WR9500N-HP - NEC](https://m.media-amazon.com/images/I/511gs8lfhgL._SL500_.jpg)
評判の良いこれを買った。セットアップはあまり迷うところもなく終わった。
ただ、USB ディスク共有だけなんかおかしくて、smb://192.168.0.1/Hitachi-1 みたいな感じで、全部指定して接続をかけないと失敗する (Mac OS X)
![]()
![]()
![]()
初回はうまくいったけど、時間が経ってからもう一度やろうとしたらうまくいかなくなった。Mac の smb 接続が不安定になったりとかいろいろした結果、以下のような状態っぽいことがわかった (推測)
なので、小さいスパースバンドルにするかなんとかしたらうまくいくかもしれないけど、もう諦めた…… 時間の無駄だった。
初回うまくいったのはよくわからない。Mac 側になんらかの形でエントリのキャッシュがあったのかもしれない。なんでもいいけど…
買ってから気付いたけど、USB ポートがついていて、USB HDD を繋いで SMB 共有ができるようになっていた。
せっかくなので、今まで有線USBでバックアップしていたのを、無線経由でバックアップするように変えた。
まず既存 Time Machine を OFF にする。
HDDを新しく買ってくるならこんなことしなくていいんだけど、買いたくないので、一旦現状のバックアップディスクを、別にディスクに .dmg としてバックアップした。
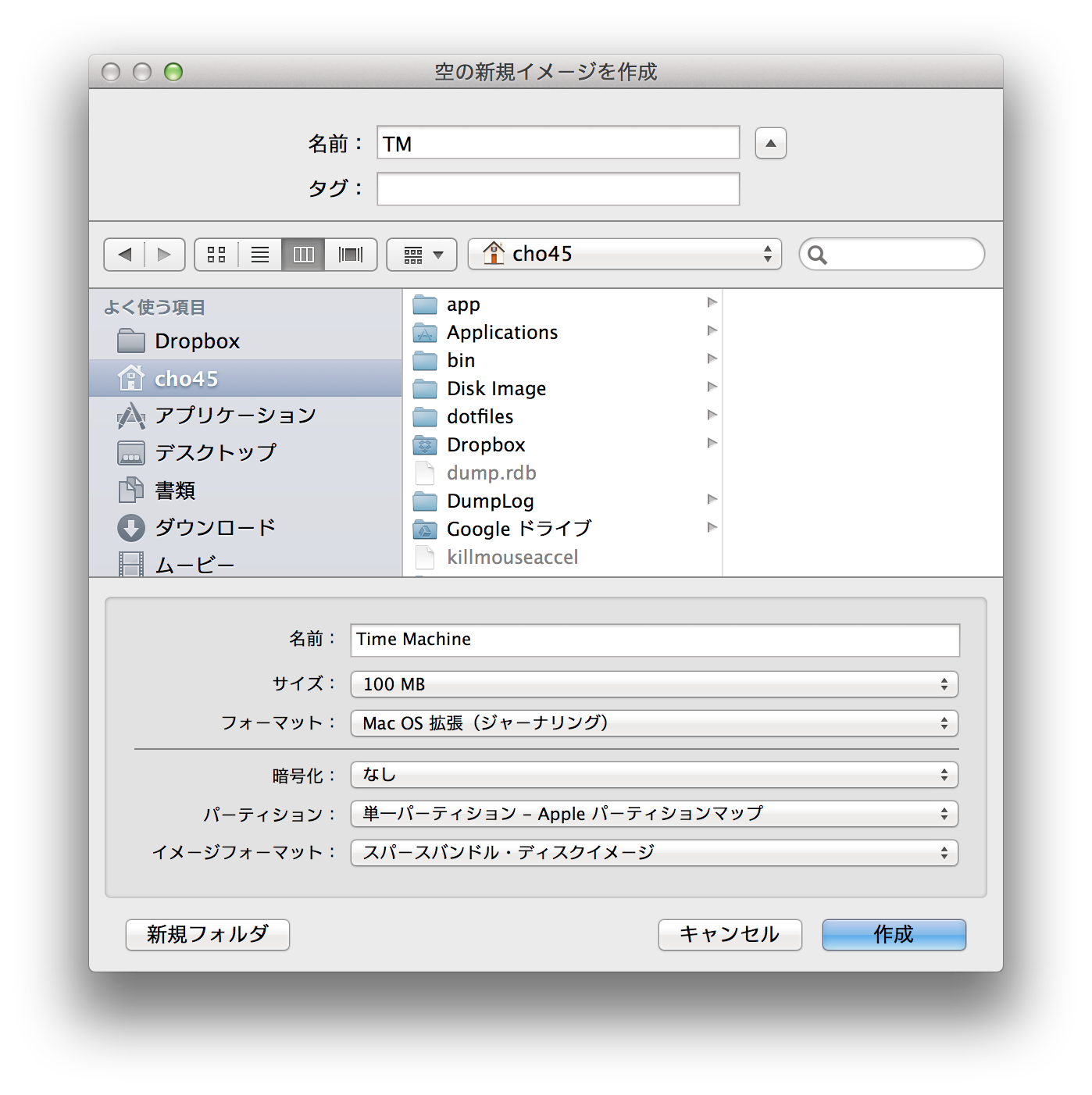
ディスクユーティリティでスパースバンドルファイルをつくる
作成したらアンマウントして、NASに繋げるディスクにコピーする。最初のバックアップまでは USB で直接繋いで作業する。
コピーしてからもう一度そのイメージをディスクユーティリティで開いて、「イメージのサイズを変更」を行い、2TB ほど容量を確保する。
スパースバンドルファイルに対して、既存のバックアップの dmg を復元する。死ぬほど時間がかる。
ディスクをNASに繋げ、共有フォルダを開き、イメージをマウントする。
イメージをマウントして、マウント済みディレクトリに対し、以下のコマンドを実行。GUI を使わないので強制的に設定できる。
sudo tmutil setdestination /Volumes/Time\ Machine
これでバックアップを再開するとネットワーク経由でバックアップが開始される。履歴も引き継がれ、差分バックアップになる。
![]()
![]()
![]()
追記:最近別のアダプタに変えました 500 Can't connect to lowreal.net:443 (certificate verify failed)
アダプタは WLI-UC-GNM というやつをつけているんだけれど、ping が平均 100ms ぐらい (1ms〜250ms ばらつきがある) で、速度も 300kB/sec (2.4Mbps) ぐらいしかでない状態だった。
SSH して作業をしているので、ちょいちょいひっかかってストレスがかかるのと、奇妙な感じなので直したくていろいろ調べていたけど、ようやく解決したので記録しておく。
先に解決方法を書くと、/etc/network/interfaces に以下を書けばいいだけだった。
wireless-power off
いろいろググってみると、ドライバに対してオプションをわたしたりとかしている例がでてくるけど、別のチップの話なのでそのまま適用できない感じだった。ただ、パワーマネジメントまわりでよくないことが起こることがある、みたいなのはこの時点で頭に入った。
iwconfig の出力を眺めると、以下のように Power Management:on になっていた。なので、iwconfig 側から Power Management を off にできないか調べたら解決方法にあるようなオプションがあることがわかった。
$ iwconfig
wlan0 IEEE 802.11bgn ESSID:"SNEG"
Mode:Managed Frequency:2.462 GHz Access Point: XX:XX:XX:XX:AE:CE
Bit Rate=43.3 Mb/s Tx-Power=20 dBm
Retry long limit:7 RTS thr:off Fragment thr:off
Power Management:on
Link Quality=63/70 Signal level=-47 dBm
Rx invalid nwid:0 Rx invalid crypt:0 Rx invalid frag:0
Tx excessive retries:0 Invalid misc:41 Missed beacon:0
lo no wireless extensions.
eth0 no wireless extensions. オプションを適用させると、Power Management:off になり、ping は平均36ms程度まで、速度は 3MB/sec (24Mbps) まで改善した。数msぐらいまで短かくてもいいと思うけど、だいぶ改善してストレスが減ったのでとりあえずよしとする。
![]()
![]()
![]()

Raspberry Pi の実測電流値が気になったので安定化電源に繋いで適当に計ってみた。
アナログで読んだのでだいたい。USB Wi-Fi は指したまま起動。ほかのイーサネットポートやHDMIポートには何も指していない。
自分で接続した周辺機器をオン (AVR + RS232ドライバ + 気圧計 + I2C文字液晶) にすると、約650mA だけど、ほぼLEDだと思う。
スペック上、このモデルは 700mA 使うことになってるけど、意外と少なかった。CPU 全力 + HDMI + イーサネットポートとかだと 700mA になるのかな?
700mA (3.5W) で1年起動させっぱなしで、電気料金が高くとも 30円/kWh だとすると、(3.5 * 24 * 265) / 1000 * 25 ≒ 668円ぐらい。
![]()
![]()
![]()
GPIO ピンからとれる電源は普通に電源回路直結なので、Raspberry Pi 自体が起動していようがしていまいが、電源ケーブルさえ接続されていれば供給されています。まぁこれはいいんですが、Raspberry Pi 本体が起動していないとき、もっというとそれらを扱うデーモンが起動していないときに電源供給されてもエコじゃないので、なんとかしました。
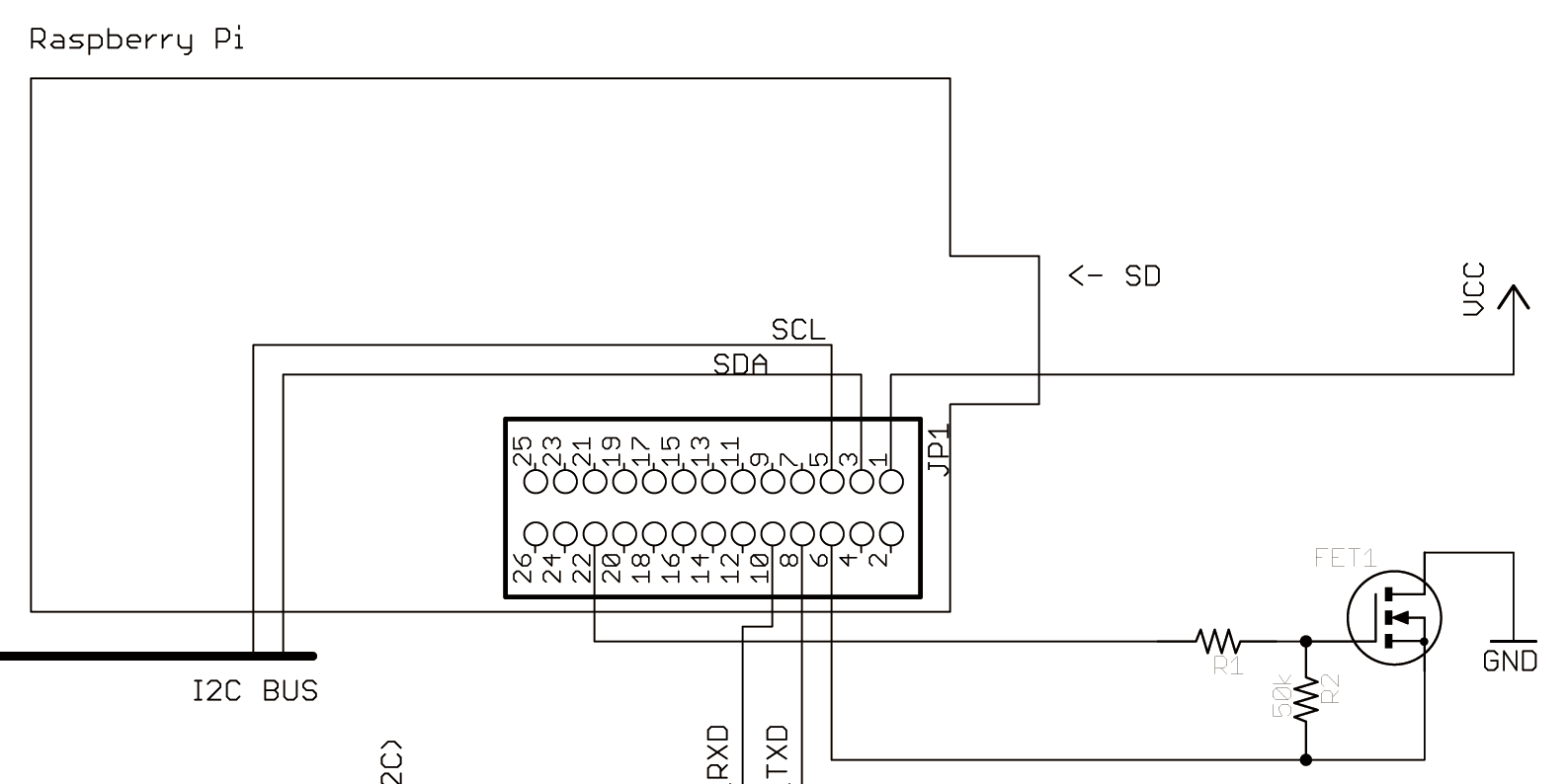
ちょっと余計な線がありますが、キモは FET だけです。伸びてる GND と VCC を周辺回路に繋ぐと、GPIO 25 (22pinから出てる) の論理によってオン・オフします。
手元では 2SK2796L を使ってます (3.3V で直接駆動できるので)
単に GPIO 25 ピンのハイ・ローを切り替えるだけです。Ruby の場合以下のように
#!/usr/bin/env ruby
# coding: utf-8
module GPIO
def self.export(pin)
File.open("/sys/class/gpio/export", "w") do |f|
f.write(pin)
end
end
def self.unexport(pin)
File.open("/sys/class/gpio/unexport", "w") do |f|
f.write(pin)
end
end
def self.direction(pin, direction)
[:in, :out].include?(direction) or raise "direction must be :in or :out"
File.open("/sys/class/gpio/gpio#{pin}/direction", "w") do |f|
f.write(direction)
end
end
def self.read(pin)
File.open("/sys/class/gpio/gpio#{pin}/value", "r") do |f|
f.read.to_i
end
end
def self.write(pin, val)
File.open("/sys/class/gpio/gpio#{pin}/value", "w") do |f|
f.write(val ? "1" : "0")
end
end
end
GPIO.export(25)
GPIO.direction(25, :out)
GPIO.write(25, true)
at_exit do
GPIO.write(25, false)
end
sleep 3 # 周辺機器が安定するまで適当な時間
... at_exit でローにするようにしてるだけです。
回路図だとわかりにくい感じだけど、これは GND 側のスイッチ (ローサイドスイッチ) で、VCC は繋がりっぱなしなので、Raspberry Pi 以外の他の電源を回路に接続するとよくないかもしれないです。
ぜんぜんよくわからないんですが、こういう回路はハイサイドにしたほうが安全なのかな。応答速度はあまり必要ではないし……
![]()
![]()
![]()
AngularJS には ngResource という拡張があって、サーバに対する API 経由の CRUD 的操作を JavaScript のオブジェクトとしてラッピングできる。具体的には例えば
var Entry = $resource('/entry/:id');
var entry = Entry.get({ id : 0 }, function () {
entry.title = "yuno";
entry.$save(); // XHR (async)
}); とかできる。ちょっとかっこいいけど、既存APIで使おうとすると、些細なフォーマットの違いで案の定使えなかったりする。どうしても使ってみたいけど、サーバサイドAPIの仕様まで変えたくない場合、若干無理矢理な方法である程度なら対応させることができる。
前提として以下のような仕様だとする
エントリリスト取得
GET /api/entries
# Response
{
"ok" : true,
"has_more" : true,
"entries" : [ ... ]
} データの新規作成
POST /api/entries
Content-Type: application/x-www-form-urlencoded
title=xxx&body=yyy
# Response
{
"ok": true
"entry" : { ... }
} データの編集
PUT /api/entries?id=0
Content-Type: application/x-www-form-urlencoded
title=xxx&body=yyy
# Response
{
"ok": true
"entry" : { ... }
} いくつかハマりポイントがある
いろいろやってみると以下のようになった。
var Entry = $resource('/api/entries', { id : '@id' }, {
'query': {
method:'GET',
isArray: true,
transformResponse : function (data, headers) {
data = angular.fromJson(data);
if (!data.ok) throw "API failed";
Entry.hasMore = data.has_more;
return data.entries;
}
},
'save': {
method:'POST',
transformResponse : function (data, headers) {
data = angular.fromJson(data);
if (!data.ok) throw "API failed";
return data.entry;
},
transformRequest: function (data, headers) {
var ret = '';
for (var key in data) if (data.hasOwnProperty(key)) {
var val = data[key];
ret += '&' + encodeURIComponent(key) + '=' + encodeURIComponent(val);
}
return ret;
},
headers : {
'Content-Type' : 'application/x-www-form-urlencoded'
}
},
'update' : {
method: 'PUT',
transformResponse : function (data, headers) {
data = angular.fromJson(data);
if (!data.ok) throw "API failed";
return data.entry;
},
transformRequest: function (data, headers) {
var ret = '';
for (var key in data) if (data.hasOwnProperty(key)) {
var val = data[key];
ret += '&' + encodeURIComponent(key) + '=' + encodeURIComponent(val);
}
return ret;
},
headers : {
'Content-Type' : 'application/x-www-form-urlencoded'
}
}
}); これを使う場合、
var entries = Entry.query(function () {
$scope.hasMore = Entry.hasMore;
});
...
var entry = entries[0];
entry.title = "FooBar";
entry.$update(); みたいになる。だいぶアホっぽいし、この部分のコードがカオスになるけど、一応使えるようにはなる。
もっといい方法があったら教えてください……
![]()
![]()
![]()
そこそこ使いやすい感じなのを学習しながら書いてみた。
割込みを利用はしてますが、APIとしてはブロックする同期なものしか用意してません。
uint8_t data[7];
uint8_t ret;
i2c_set_bitrate(100);
// Set target slave address
i2c_master_init(0x60);
ret = i2c_master_write((uint8_t*)"\x04", 1);
if (ret) goto error;
ret = i2c_master_read(data, 8);
if (ret) goto error;
i2c_master_stop();
error:
i2c_master_stop(); スレーブの場合、特定のメモリ領域を登録すると、そこに対して read も write もできる、という感じの設計になっています。
// Slave memory map (must be smaller than 254 (0xfe) bytes) uint8_t data[9]; // Enter to slave receive mode with data and size. // After this operation, data will be changed automatically by TWI interrupt. i2c_slave_init(0x65, data, 10); // Access (set or get) to I2C data block data[0] = 0x10;
// Or more readable code with struct
struct {
uint8_t foo_flag1;
uint8_t foo_flag2;
uint16_t bar_value1;
uint16_t bar_value2;
uint16_t bar_value3;
uint16_t bar_value4;
} data;
i2c_slave_init(0x65, &data, 10); 割込みでいつのまにかデータが変化する感じなので、マルチバイトデータの読み書きではデータが化ける可能性があります。
マルチバイトデータの読み書きを行う場合、
が必要だと思います。通信中のデータはコピーして別で持っておけばいいんですが、もったいないし、そんなに問題にならなそうだしお手軽なのでこんな感じです。
I2C は仕様書の日本語訳で公開されている。本家?はi2c-bus.org かな。
ポイントとしては
マルチマスターまわりとゼネラルコール(マルチキャスト)まわりはいまいち理解できてない (今のところ必要性を感じてない)。
I2C 自体は任意長のバイトの送受信しか定義してない (言及はあるけど) ので「特定のアドレスのデータを読みだしたい」みたいな場合は、その上にプロトコルを乗せる必要がある。デファクトスタンダードっぽいのは
というもののようだ。ステートフルなので、読み出される側は読まれようとしているアドレスを記憶しておく必要があり、1バイト読まれるごとにインクリメントする必要がある。送信と受信は別々にアドレスを指定する必要があるので、この場合2度アドレス送信が行われる。
ポイントは
基本がわかればあとはそんなに難しくなく、試行錯誤したらできる感じだった。ただ、割込みの中で余計なことをすると、うまく次の割込みが入らなくなるということがあったりするので、動作を観測するのが難しい。LED チカらせてデバッグするしかないことがある。
Linux の I2C まわりを調べていて出てくる SMBus とかいうのはPCの電源管理とかで使われるプロトコルで、基礎プロトコルとしてI2Cを利用している。I2C レイヤーの上に SMBus というレイヤーがあるイメージ。
![]()
![]()
![]()
ソフトウェア開発って、他人が過去に作ったものに対する発見を重ねるみたいなところがあって、人工的に作られた過去の遺物を発見してうまく解釈するという、なんかよくSFモノにある、失なわれた技術を発掘していくみたいな、そういう感じ。
ソフトウェアは書いた通りにしか動かない。ソフトウェアのどこかの部品が壊れて(バグって)いたら必ず、なにかしら観測可能な状態に落としこめるような環境が整っている。
![]()
![]()
![]()
ハードウェア部分は、人間が工夫して設計しているとはいえ、基本は物理現象(電子の動き)を利用していて、それが自分には不思議で面白い。ソフトウェアレイヤーをいじっている限りでは物理現象を利用しているという感覚は一切なく「他人がどういう意図で設計したか?」という、物理というよりは精神なことを考えていることが多い。
ハードウェア、回路レベルの設計は全体的にパズル的で、動いているのが不思議な感じがする。ソフトウェアでこういうパズル的なことをやろうとしたらテストを書かないと殺されると思うけど、頑張ってだいたいうまく動いてる感じで感心すると同時に、こんなので大丈夫なのかと心配になる。
しかし実際には精度良くハードウェアは動くように設計されていて、そういう頑張ってる感じのパズル的に動くロジックの大量の組合せでCPUが構成されて、その上で機械語が実行されていて、機械語を生成するための言語があって、Cから機械語を生成するためのツールチェインがあって、それらを利用してさらに抽象化されたレイヤーで書けるLLがあって、なんだか考えていると、LLでコードを書くのはジェンガの上のほうでコードを書いている感じに思えてくる。
![]()
![]()
![]()
GPIO の操作はいろいろやる方法があるみたいだけど、LL からだと sysfs への IO を行うのが一番簡単っぽい。以下のような感じでかなり簡単に書ける。この程度だとライブラリを使う必要はない。
pin の数値は、RPi Low-level peripherals で書いてあるような GPIO n の n の部分を指定する。(物理的なピンの並びとは関係ない)
この例だと GPIO 25 (22pin) で指定時間ごとに論理が反転する。
#!/usr/bin/env ruby
# coding: utf-8
module GPIO
def self.export(pin)
File.open("/sys/class/gpio/export", "w") do |f|
f.write(pin)
end
end
def self.unexport(pin)
File.open("/sys/class/gpio/unexport", "w") do |f|
f.write(pin)
end
end
def self.direction(pin, direction)
[:in, :out].include?(direction) or raise "direction must be :in or :out"
File.open("/sys/class/gpio/gpio#{pin}/direction", "w") do |f|
f.write(direction)
end
end
def self.read(pin)
File.open("/sys/class/gpio/gpio#{pin}/value", "r") do |f|
f.read.to_i
end
end
def self.write(pin, val)
File.open("/sys/class/gpio/gpio#{pin}/value", "w") do |f|
f.write(val && val.nonzero? ? "1" : "0")
end
end
end
GPIO.export(25)
GPIO.direction(25, :out)
led = true
loop do
GPIO.write(25, led)
led = !led
sleep 0.5
end
![]()
![]()
![]()
無線のPCモールスUSBインターフェイスって結構高価なのが多いんだけど、Raspberry Pi だと GPIO 経由で普通にキーイングできるし、単体で HDMI やコンポジットビデオ出力できるから、これで十分すぎる感じがする。
![]()
![]()
![]()
GPIO に UART があるけど、デフォルトではシリアルコンソールとして使うことが想定されていて、カーネルメッセージとかが流れる。これを無効にして、普通のシリアルポートとして使う。
/etc/inittab を書きかえる。ttyAMA0 の行をコメントアウトする
#Spawn a getty on Raspberry Pi serial line T0:23:respawn:/sbin/getty -L ttyAMA0 115200 vt100
/boot/cmdline.txt を書きかえる。デフォルトだと以下のようになっているので
dwc_otg.lpm_enable=0 console=ttyAMA0,115200 kgdboc=ttyAMA0,115200 console=tty1 root=/dev/mmcblk0p2 rootfstype=ext4 elevator=deadline rootwait
して以下のように
dwc_otg.lpm_enable=0 console=tty1 root=/dev/mmcblk0p2 rootfstype=ext4 elevator=deadline rootwait
で reboot すると普通にユーザレベルで自由に使えるようになる。
3.3V なので、RS-232C レベルにするなら 3.3V でも使えるドライバICを使う必要がある。ICL3232 だと100円ぐらい。
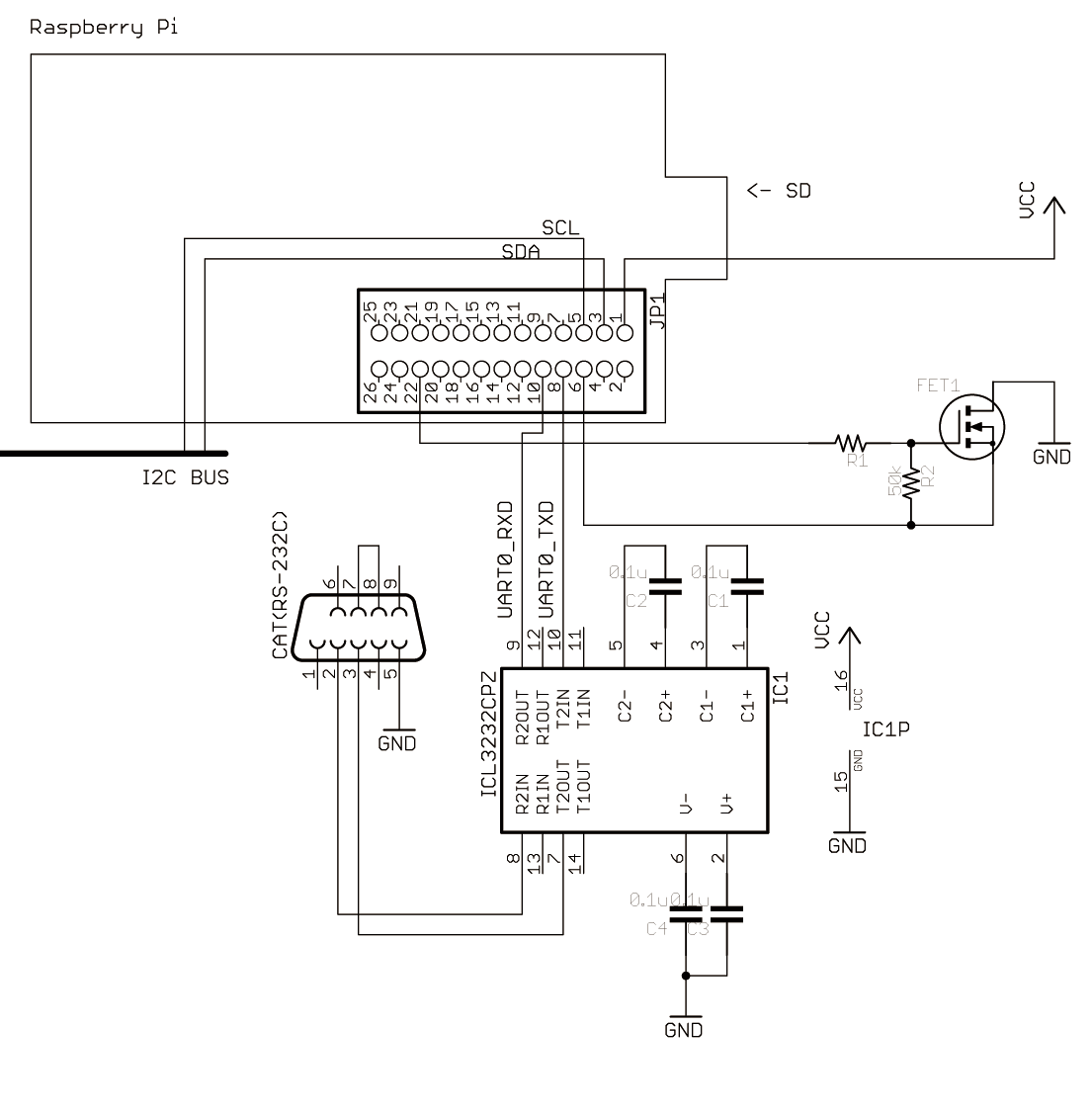
FET らへんは GPIO 25 (22pin) をオンにしているときだけスイッチを入れるための仕組みなので RS-232C のためには必須ではない (GND を普通に繋ぐだけ)
![]()
![]()
![]()

なんとなく i2c-dev.h とかで定義されているAPIを呼ばないと使えないのかなあと思っていたけど、デバイスファイルの読み書きと ioctl だけで普通に使うことができた。
I2C 的には START -> SLAVE + W -> DATA送信 -> STOP が行われる。
I2C 的には START -> SLAVE + W -> DATA送信 -> ReSTART -> SLAVE + R -> DATA受信 -> STOP が行われる。
たぶん一度 write/read するたびに Repeated Start が送られるのかな。
Ruby でやる場合以下のような感じでいけた。デバイスによってはうまくいかないかもしれない。
class I2CDevice
# ioctl command
# Ref. https://www.kernel.org/pub/linux/kernel/people/marcelo/linux-2.4/include/linux/i2c.h
I2C_SLAVE = 0x0703
attr_accessor :address
def initialize(address)
@address = address
end
def i2cget(address)
i2c = File.open("/dev/i2c-1", "r+")
i2c.ioctl(I2C_SLAVE, @address)
i2c.write(address.chr)
ret = i2c.read(1).ord
i2c.close
ret
end
def i2cset(*data)
i2c = File.open("/dev/i2c-1", "r+")
i2c.ioctl(I2C_SLAVE, @address)
i2c.write(data.pack("C*"))
i2c.close
end
end
![]()
![]()
![]()
RFC (rfc:1945) は1996年 (HTTP 1.0と同じRFCで説明されてる)
最初の HTTP。GET メソッドしかなかった。レスポンスヘッダもない (ボディーだけ)。
RFC (rfc:1945) は1996年
RFC (rfc:2068 → rfc2616) は1997年
HTTP 1.0 に Keep Alive とかを追加したやつ。
RFC (rfc:2817, rfc:2818) は2000年
HTTP 1.0 または 1.1 を TLS (暗号化層) にのっけたもの (暗号化通信)
(SSL は TLS の元になったプロトコルの名前)
RFC (rfc:6455) は2011年。HTTP を拡張したもの、と言っていいか微妙だけど、HTTP でセッションを初期化して 101 Switching Protocols で専用プロトコルに切り替わる関連技術的なもの。
Google が作ったプロトコル。現在は SPDY Protocol - Draft 3.1 が最新。
SPDY を元に提唱されてる新しい HTTP のバージョン。SPDY を HTTP 2.0 として標準化しよう、って感じかな。現状では SPDY と一緒。
Google が作ってるあたらしいプロトコル。上記までのような HTTP の互換レイヤーの話ではなく、その下のレイヤーのプロトコル。
技術の発展とともに TCP がネックになることが増えてきたので、UDP を使って TCP+TLS レイヤーを実装しなおすという感じ。
未来における WebSocket の立ち位置がよくわからない。HTTP 2.0 になったとして (SPDY 実装はすすんでいるし、たぶんなるだろう)、WebSocket はどうなるだろう。HTTP 2.0 上で WebSocket を使うのか、あるいは HTTP 2.0 のセッションを JS からコントロールできるような API が整備されるのか。
![]()
![]()
![]()