
メモ書き。試行錯誤の途中でコードが消えさったりしていてよくないので、やったことだけ書いておく
モールスの特徴
- 信号周波数が固定されており正弦波。キャリアの有無で信号を伝える
- 「信号のOFF」と「信号がない」ことは区別できない
- 聴覚受信で必要な SNR は 6 (カジュアル)〜1dB (定型) 程度 https://en.wikipedia.org/wiki/Minimum_detectable_signal http://kf6hi.net/radio/SNR.html
- 定型文が多い
- 符号速度は15wpm〜40wpm ぐらいの範囲。1dot [ms] = 1200 / wpm なので、40wpm=66Hz程度。100Hzの帯域で十分 (無線機のフィルタも100Hzが下限)。
波形の処理でなんとかする
検出したい周波数を中心として0Hzに正規化 (検波)し、振幅を得る。100Hz のローパスフィルタをかけ、ダウンサンプル (200Hz 程度) する。
これを Denoising AutoEncoder のネットワークに順次入力し、デコーダ出力列から信号列を復元する (出力はある程度重なるので、最終的に平均を出す)。
出力は文字データではなく、フェージングや符号ゆらぎなどを解決した符号列とする。つまり入力数と出力数は必ず一致し、実際に文字化する処理は含まない。
入力
.png)
こういうデータ。これはノイズが少ないのでわかりやすい。
モデル
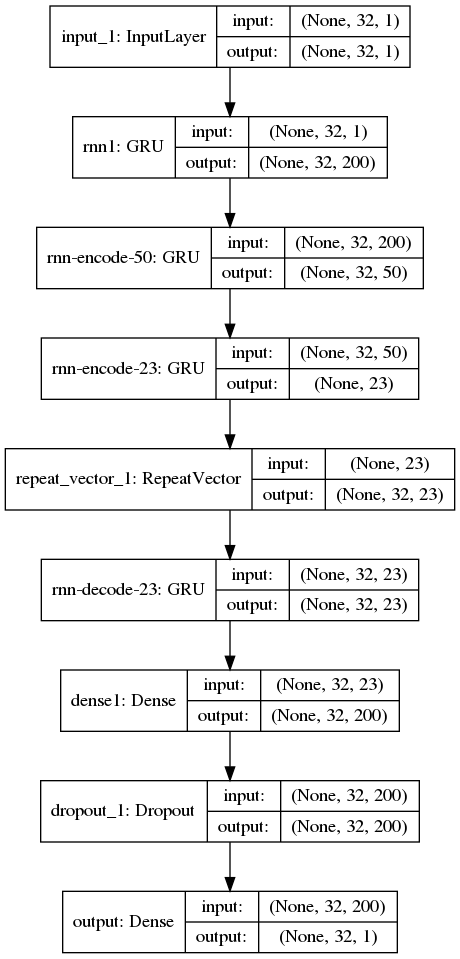
適切なパラメータが一切わからないが試行錯誤してこんな形になった。RNN の場合、入力シェイプがやや難解でググったり他の人のコードを読んだりして理解した。最初は LTSM を使っていたけど時間がかかるのでGRUにしてみた。
実際の入力データは keras.preprocessing.sequence.TimeseriesGenerator を使うのが楽だった。(最初は知らなくて自力でつくっていた)。timestep は 32、つまり過去の信号 32 サンプル分を1サンプルずつずらしながら入力している。
RepeatVector の前まではエンコーダで、その後がデコーダ。
学習
node.js と web-audio-engine を組合せて大量にノイズ+信号のデータと正解データを作って学習させた。
結果
学習はちゃんとできて、認識できるのは認識できる。
.png)
ただ、ノイズがかなり多い信号はやはりどうしようもなかった。聴覚だと聞きとれても、そもそも 0Hz に正規化した時点でノイズに埋もれてしまっていて、学習しようがなさそうだった。
.png)
ということでこの方法ではなく他の方法を考えてみることにした。
備考
とりあえずできるのかな〜ベースでやったため、ちゃんとした評価方法を考えてなかった。SNRなど評価の指標を立てたい。しかしSNRは求めかたが難しくてこまってる。