金曜日の夕方ぐらいから全身倦怠感と頭痛がはじまり、微熱(37度台)に。熱は土曜日中ぐらいで下がったが頭痛は治らず、今(月曜日)でもまだ痛い。
体調不良
![]()
![]()
![]()
金曜日の夕方ぐらいから全身倦怠感と頭痛がはじまり、微熱(37度台)に。熱は土曜日中ぐらいで下がったが頭痛は治らず、今(月曜日)でもまだ痛い。
![]()
![]()
![]()
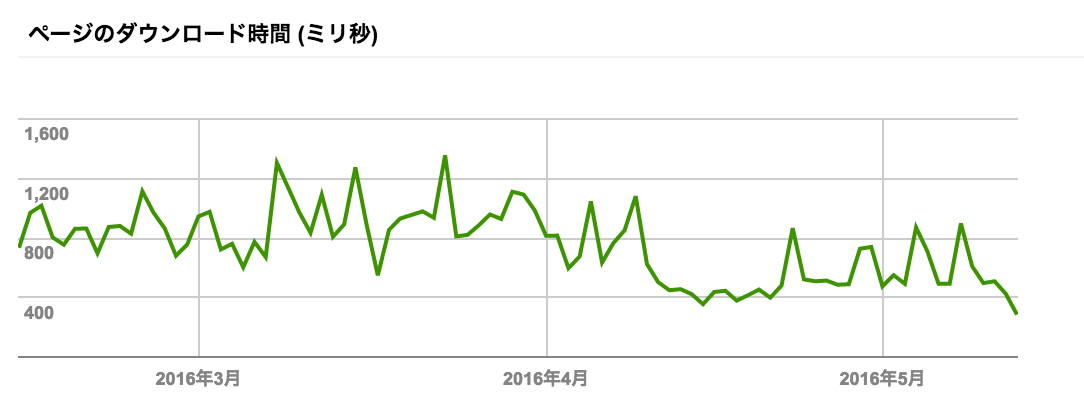
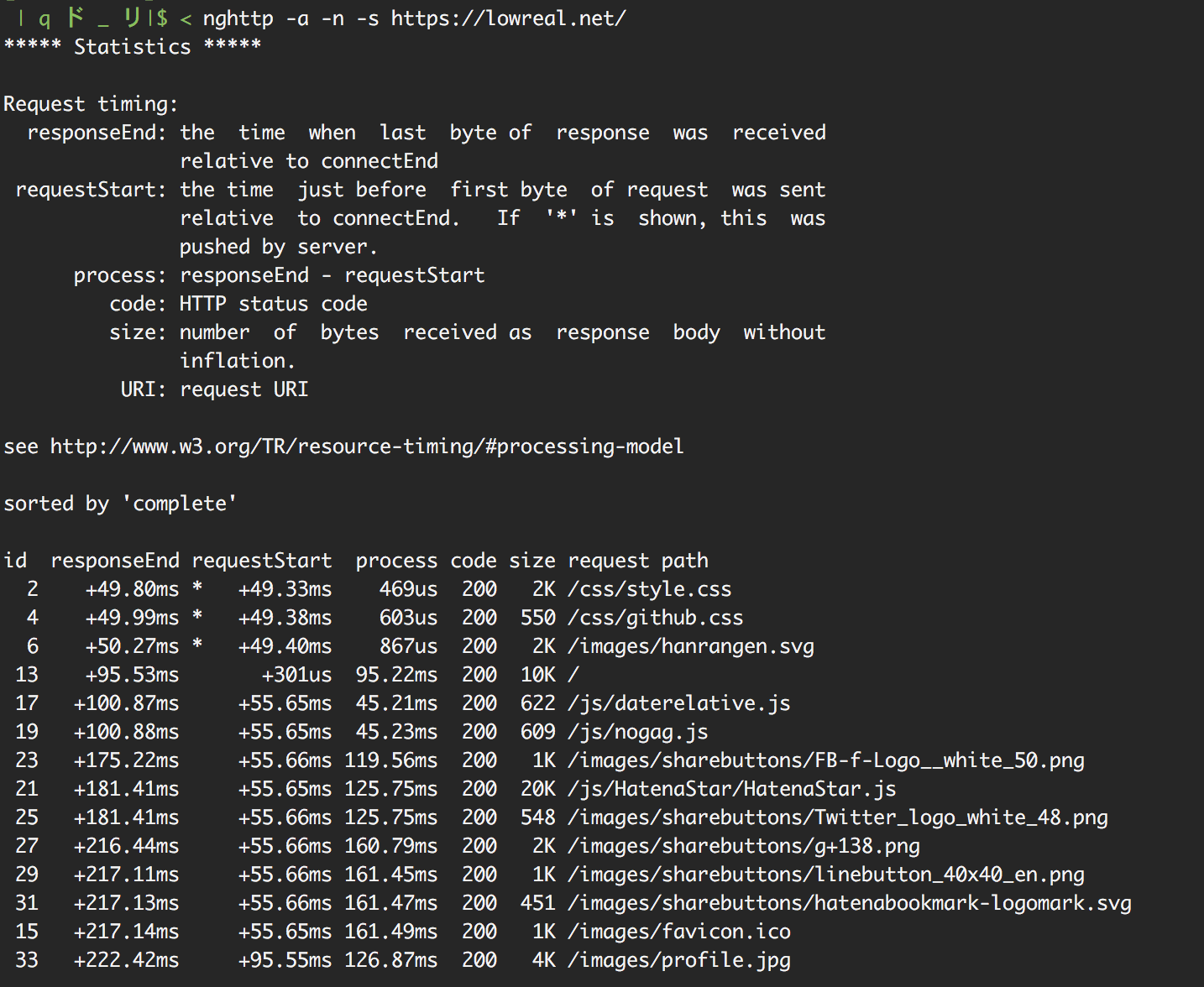
sitemap.xml を送信した翌日ぐらいに Googlebot からの連続したアクセスがくるようになる。Googlebot は HTTP/1.1 で Keep-Alive が有効なため、普段にパラパラくるアクセスよりも、このときのように連続してアクセスされる場合、多くの場合でコネクション時間がなくなるために高速にレスポンスを返せる。
連続したアクセスの場合、2分ぐらい Keep-Alive している。
これは結果として Search Console の「クロールの統計情報」に表示されている「ページのダウンロード時間 」のグラフにも反映されているような感じで、sitemap.xml を追加した次の日あたりで平均ダウンロード時間がかなり少なく表示される。
![]()
![]()
![]()
Server::Starter は hot deploy 用の汎用スーパーデーモンで、Perl で書かれています。h2o の起動にも使われているのでみなさんおなじみでしょう!
Server::Starter がやってることは、Server::Starter 側で listen したソケットの fd を環境変数につっこんで子プロセスを起動というものです。子プロセス側では渡ってきた環境変数を読んで、fd について accept すれば良いことになります。
これを node.js でやるには以下のようにすれば良いようです。
//#!/usr/bin/env node
"use strict";
const http = require('http');
const server_starter_port = process.env['SERVER_STARTER_PORT'];
if (!server_starter_port) {
console.log('SERVER_STARTER_PORT is not set');
process.exit(1);
}
const fds = server_starter_port.split(/;/).map( (i) => i.split(/=/) );
const server = http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World\n');
});
process.on('SIGTERM', () => {
console.log('server exiting');
server.close();
});
for (let fd of fds) {
console.log('listen', fd);
server.listen({ fd: +fd[1] });
} 起動はたとえば以下のように
start_server --port=5001 -- node server.js
http.Server の listen() のドキュメントには fd を渡せるバージョンが書いてありませんが、net.Server の listen() がサポートしているので、同様に渡せるようです。
これだけで node.js のプロセスの hot deploy が簡単にできます。
node.js には cluster というのがあります。これは node.js を複数プロセスで動かすための仕組みなんですが、これの woker プロセス側の listen() は master プロセスと ipc してうまいことやるみたいな感じのようです。
![]()
![]()
![]()
このサーバはVPS 1台で動いていて、メモリは1GBしかありません。常時メモリ上限まで使いきっており、スワップファイルもそこそこあります。そういうわけで、できるだけメモリ消費をケチりたいのです。
このサーバ上で動いているサービスがいくつかあるのですが、実際のところどれも殆どアクセスはありません。一番アクセスされていてこの日記システムぐらいです。
それらのサービスをそれぞれ別プロセスで起動させておくと、たいへん無駄なので、できるだけプロセス自体を同居させています。
Plack::Builder が提供している mount() を使うと、vhost を実現できます。
builder {
mount 'http://lowreal.net' => do {
my $guard = cwd_guard("lowreal.net/");
Plack::Util::load_psgi("script/app.psgi")
};
mount 'http://env.lowreal.net' => do {
my $guard = cwd_guard("env.lowreal.net/");
Plack::Util::load_psgi("script/app.psgi")
};
}; このようにすると、Host ヘッダに応じて、ディスパッチするアプリケーションを変えることができます。
これを利用して、複数の psgi アプリケーションを1つの psgi アプリケーションにまとめて起動しています。
ただし、起動時 (load_psgi時) にだけ cwd を設定しているため、cwd 依存のコードがあるとうまく動きません。
単にプロセス数も減らせますが、それぞれのアプリケーションで共通で使うモジュールがかなり多いので、それらを fork 前にロードして共有しておくことで、プライベートメモリ使用量を削減しようという意図もあります。
上記のまとめた psgi アプリケーションを start_server と plackup 経由で起動しています。
start_server 用には以下のような環境変数を設定しています
export KILL_OLD_DELAY=15
export ENABLE_AUTO_RESTART=1
export AUTO_RESTART_INTERVAL=3600
exec setuidgid cho45 \
$PERL/bin/start_server --path=/tmp/backend.sock --port=5001 -- $PERL/bin/plackup -p 5001 -s Starlet\
--max-workers=5 \
--max-reqs-per-child=500 \
-a backend.psgi ENABLE_AUTO_RESTART によって、時間経過で自動的にプロセス全体を再起動しています。再起動間隔は AUTO_RESTART_INTERVAL に決まり、この場合1時間ごとになっています。
KILL_OLD_DELAY には新プロセスが起動して、リクエストが受けつけられるようになるまでにかかる時間を余裕をもって指定します。これを指定しないと、プロセス再起動がかかるたびに、モジュールなどのロードが終わるまでの数秒アクセス不能時間ができるので、特に ENABLE_AUTO_RESTART する場合は必須そうです。
これで、もしメモリリークしていても1時間以内に綺麗になることが保証されるとともに、fork した worker プロセスが働いて Copy on Write が起こってプライベートメモリ量が増えたとしても、1時間以内に fork しなおしになるため、共有メモリ量が一定より高い状態を保つことができます。
Linux のプロセスが Copy on Write で共有しているメモリのサイズを調べる - naoyaのはてなダイアリー にある shared_memory_size.pl が便利でした。共有メモリの割合を表示してくれるのでわかりやすいです。
Starlet のプロセス名をわかりやすくしたかったのも、このスクリプト実行時に指定しやすくするためでした。
こんな感じで使っています。
shared-memory-size.pl `pgrep -f /srv/www/backend.psgi` PID RSS SHARED 29583 55460 47792 (86%) 29584 55760 44688 (80%) 29585 65224 41396 (63%) 29586 56280 44704 (79%) 29587 55352 44660 (80%) 29588 58908 46748 (79%)
起動してすこし経ったあとの状態です。起動直後は90%以上ですが、プロセスが動くごとに少しずつ共有割合が減っていきます。自分の環境で、観測したうちだと60%ぐらいまで下がるようです。
ps -c で見るメモリ使用量には共有分が考慮されていないので、実際の物理メモリ使用量よりもかなり大きく出ます。仮に1プロセスあたり70MBぐらいメモリを消費していても、うち40MBぐらいが共有であることを考えると、worker プロセス1つあたり30MB、5プロセスで150MB程度の物理メモリ消費量になります。
![]()
![]()
![]()
アクセスログを見ていたら Applebot なるものからのアクセスがあった。
https://support.apple.com/ja-jp/HT204683
ほんとに Apple のウェブクローラらしい。ただ
robots の制御指示で Applebot には言及していなくても Googlebot について指定されている場合、Apple のロボットは Googlebot に対する指示に従います。
と書いてあって、それはどうなんだ、という感じがする。
![]()
![]()
![]()
UAからしてなんか怪しいが、210.160.8.236 からくる BOT で、DNSを逆引きすると target.microad.jp. らしい。マイクロアドを使ってるつもりはないんだけど、Adsense 貼るとくるのかな?
まともなクローラのつもりなら、UA をもうちょっとわかりやすくしといてほしいですね。まともな会社なら自社クローラのUAと目的ぐらい書いとくべきだと思います。
![]()
![]()
![]()
![]()
![]()
![]()
今までのページャは良くある ?page=2 みたいな形式でした。これは内部的には offset / limit を使う SQL になります。
変更したページャは /.page/20160509/3 という形式です。20160509 が表示するページ番号、3 がそのページに表示する最大の数です。ページ番号はトップページからのページの場合、日付になっており、内部的には日付ベースの where 句になります。3 は limit です。
これらによって、サーバ側のエントリ表示数のデフォルト設定によらず、URLによって決まる内容が生成されます。よって
このサイトは「日記」なので、日付単位でエントリがまとめられています。「ブログ」の表示に慣れていると違和感があるかもしれませんが、以下のような違いがあります。
ちょうど、紙に日記を書くときのように、1日の中では連続し、1日単位では独立しているというイメージです。
この挙動は正直初見ではわかりにくいと思うのですが、過去分は1日単位で上から下へ書かれる前提で複数のエントリを構成しているケースがあって、変えるに変えれません。
![]()
![]()
![]()
子供のおもちゃのチョロQを見ていて不思議に思ったことがあって調べたので書いておきます。
チョロQみたいなプルバック式のミニカーは、後退するときにぜんまいを巻き上げることで、前進時に動力にするわけです。なので、くるま全体を床に押し付けたまま前後してもぜんまいは巻き上がらず (後退で巻き上がっても前進させた分巻き戻る)、走らないと思っていました。
自分の遊んだ記憶だと、後退するときだけ押し付けて、一旦持ちあげてもう一度後退させていた覚えがあるのです。
いつこの「プルバックの走らせかた」を学んだのか全く覚えていませんが、当然そういうものという認識でいました。そしてそもそも「後退時に巻いたぜんまいで動く」以上の仕組みを知りませんでした。
子供は「プルバックの走らせかた」を知らず、適当に前後させたらなんかうごくことだけ学習しています。
子供が遊んでるときの挙動を見てるいると、ただ床に押し付けてゴリゴリと前後するだけでもぜんまいが巻き上がり、しかもどう見ても巻いた以上に長い時間回転することに気付きました。
Wikipedia の「プルバック式」の項を見ると
ゼンマイを使うプルバック式動力では、後退の時のみギア比の大きい状態になるよう、内部の歯車が浮き上がるようになっており、ゼンマイの力で前進する時だけタイヤを高速回転させるような構造を持つものも多い。
と書いてあって、ギア比が前進と後退で変わるような仕掛けがあるようでした。
「プルバック ギア」とかで検索すると、もうすこし詳しいページも見つかります。構成するギアのうち2つのギアの軸は方向によってずれることで、いずれか一方が噛み合うように調整されているようです。
もしかすると常識なのかもしれないですが、こういう面白い仕掛けがしてあるとは考えていなかったので、びっくりしました。
![]()
![]()
![]()
結局ガルパンは5回ぐらい見てしまった。劇場版がみたい。
![]()
![]()
![]()
ボトルガムを買うと、だいたい2日ぐらいでなくなってしまって金がもったいないという感じになってしまう。
職場にいると無限にストレスが溜まってるので、手の届くところにガムとか食べものを置いておくと無限に食べてしまう。もったいないので、できるだけ買わないで水をガブ飲みしてるけど、口が寂しい。
![]()
![]()
![]()
そういえば、ものすごくイライラしているときは掃除すると多少気が紛れる (やる気になった場合だけだけど)。すこし前にイライラしたときは、ひたすらトイレ掃除をしていた。
掃除には良い点がいくつかあって
一定の「満足感」は手に入ることがほぼ保証される。そんなものは他にあるか? ネトゲとかは瞬間的な満足感はあるが社会的には虚しい。掃除は同居家族がいるなら社会的な利益もある。
しかし、どういった種類のことでも「やらされている」と思った時点ですべての利点は失われる。他人のために働くということをすると、自分で満足するということがなくなる。成果評価の裁量を他人に奪われた時点で生きてる実感はなくなる。
![]()
![]()
![]()
少しでもストレスが解消されることがら
大きくストレスが溜まることがら
他人の道徳観に関するストレス (路上喫煙も同じ) は「こんなやつが社会でうまく生きてるのに、なぜおれは社会でこんなに否定されているのか」という感情に基いている。
![]()
![]()
![]()
![]()
![]()
![]()
ps とかで表示されるプロセス名をわかりやすくしたいという話です。
Starman だと $0 に適当な値を入れてくれて、master なのか worker なのかとか、どの psgi が動いているかとかがわかるのですが、Starlet ではそういうことをやってくれないので、1つのサーバで複数インスタンス動かしていると、plackup のプロセスだらけで、どれがどれだかわからなくなります。
app.psgi で $0 設定したらとりあえずいいだろ、と思ってやってみましたが、どうも上手くいきません。app.psgi 内で $0 を warn してみるとそもそも plackup になってもいません。
調べてみると、Plack::Util::load_psgi で使っている _load_sandbox 内で local $0 をしてから app.psgi を do しており、ロード後に元のプロセス名に戻ってしまうようです。
ということで、単純に app.psgi で $0 を書きかえても plackup を使っている場合書きかわりません
なんかうまい方法がなさそうなので以下のようなクソハックを app.psgi に入れました。
{
### set process name for Starlet
use Parallel::Prefork;
my $name = $0;
my $orig_new = \&Parallel::Prefork::new;
no warnings 'redefine';
*Parallel::Prefork::new = sub {
my ($class, $opts) = @_;
$opts->{before_fork} = sub {
$0 = "$name (worker)"
};
$opts->{after_fork} = sub {
$0 = "$name (master)"
};
$orig_new->($class, $opts);
};
}; Starlet は Parallel::Prefork を使っているので、前もって use して new を書きかえて before_fork / after_fork を設定します。
before_fork / after_fork は Parallel::Prefork の機能でセットできるフックポイントですfork 前に worker プロセス用の $0 を設定して、fork 後に $0 を master 用の値に変えています。なのでタイミングによっては master プロセスも一瞬 worker 表示になります。
app.psgi ロード時のコンテキストでは $0 には .psgi のファイル名が入っています。これは上記の Plack::Util::_load_sandbox で設定されたものです。ということで、ロード時のコンテキストの$0を保存しておいて、後の $0 の設定に使っています。
app.psgi が Starlet 専用みたいになってキモいですが、Parallel::Prefork をロードする以上の害はとりあえずないのと、自分の場合は開発中に Standalone で動かす以外は Starlet を使うことにしているので問題ありません。
これで以下のようになりました。
cho45 4699 0.0 0.5 185432 5332 ? S May11 0:00 /home/cho45/project/COQSO/script/app.psgi (master) cho45 4700 0.0 2.4 296604 25168 ? S May11 0:09 /home/cho45/project/COQSO/script/app.psgi (worker) cho45 4701 0.0 2.5 296820 26468 ? S May11 0:11 /home/cho45/project/COQSO/script/app.psgi (worker) cho45 4702 0.0 1.8 302304 19136 ? S May11 0:11 /home/cho45/project/COQSO/script/app.psgi (worker)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
トラックバックを実装しました
といってもサイト内のエントリ間の言及を表示するだけです。いわゆる古代のオープンなトラックバックではありません。
古いエントリに新しいエントリへのリンクがないのは不便だなと思い、とりあえずさくっと LIKE 検索で機能を足してみていたのですが、良さそうなので、ちゃんとリレーションテーブルをこしらえたりしました。
しかし、全体的にページキャッシュ機能を入れているので、単に機能を足すだけでも考えることが増えてしまいます。イメージではトラックバックが送られたページに更新がかかるというだけですが…
キャッシュ処理も見直して、全体的にテストも書いたりしました。キャッシュが入ると複雑性が増す分、独り人力QAには限界があるので、みっちりテストを書くほうがかえって省力化します。
![]()
![]()
![]()

Stokke ストッケ ベビーチェア ハイチェア 本体 トリップトラップ 食卓 赤ちゃん 椅子 ウォールナットブラウン cho45
2歳になって自分でできることが増えてきたり、「みいつけた」で椅子を見ているせいか、椅子が好きになってきたみたいなので、本人だけで座れる椅子を買いました。
ちょっと高いけど、10年ぐらい使えそうなので、そう考えればそこまで高くないかなと思ったのと、こういう大物は買ったり捨てたりするのが面倒なので、ストッケ・トリップトラップというのを買ってみました。色はウォールナットブラウン。
届いて組み立ててる最中から子供はだいぶテンションが高くて、六角レンチでボルトを締めようとしたり(むしろ緩めてたけど)していて面白かった。
ちゃんと独りで座ることもできるし、安定しているので良さそう。ただ子供は「新しいものは様子を見ながら使う」というのがわかってないので、ドンドコドンドコやっててハラハラする。
ところで最初組み立て図を見ても、座面とかにはボルトがなくて、どうやって固定されるかがよくわからなかった。組み立ててる途中でようやくわかったが、これの座面は左右の支えの窪みに入れた状態で、他の部分のボルトを締めていくことで挟みこんで固定されるようになっている。面で固定されるから直接ボルトで固定するよりもいいのかな。増し締め忘れないようにしないといけなそう。
1週間ぐらい既に使っているけど、表面塗装のせいか汚れても思いのほか拭き取りやすい。あと、倒れないように足の底部に滑る部品(滑り止めではない)がついていて、面白かった。子供がテーブルを蹴って後ろに倒れないように、椅子自体を滑らせるという形のセーフティになっている。ただ、性質上、床面がフローリングでないと機能しない。うちはフローリングにマットを敷いているので残念ながら意味ない。
これを今まで使っていた。まだ使えそうだけど、自分で座ることができなくてちょっと可哀そうになってきた。それに毎回大人が持ちあげる必要があるが、子供も既にそこそこ重い(12kgぐらい)ので結構つらい。
汚れたら風呂場でザーーーと洗って干すという雑な運用をしていたけど、半日ぐらいですぐ乾いてくれるので良かった。値段も安かったし、十分に使えたと思う。
![]()
![]()
![]()

RiZKiZ 子供用絵本ラック 木目調 キッズブックシェルフ マガヒンラック 収納に便利な仕切り棚付き (3段タイプ/ダークブラウン) cho45
今までの本棚に不満があったのでこれを買ってみました。本体がかなり重くてしっかりしてます。
子供は特に何の反応もなく本棚と認識して使っていて、あっけない感じだった。絵本渡して「ないないして」というとちゃんと入れてくれる。よかった。

森井紙器 すまいるキッズ 絵本ラック レッド cho45
買ったときはあんまり本もないからいいかと思ったけど、急激に増えてしまって納まりきらなくなった。
この商品はダンボールでできていて軽いんだけど、おかげで子供が中の本を全部出して、本棚を振り回して遊んでることが多々あった。さすがに最近はそんなことしないけど、軽くて小さいというのも考えものだなあと思った。あとダンボールなので、乱暴に扱うとかなりヨレてしまう。
結果的にはこれを買ったのは失敗だった。最初からそこそこのものを買ったほうが良かった (どうせ必要だから)。
![]()
![]()
![]()
今までは Cache::FileCache によるファイルシステムキャッシュにしていたけど、いくつか問題があって SQLite にかえた
Redis とかを立てるのが機能的には便利そうだけど、リソース的にあんまりサーバプロセスを増やしたくはないので、SQLite とした。
CREATE TABLE cache (
`cache_key` TEXT NOT NULL PRIMARY KEY,
`content` BLOB NOT NULL
);
CREATE TABLE cache_relation (
`id` INTEGER PRIMARY KEY,
`cache_key` TEXT NOT NULL,
`source_id` TEXT NOT NULL
);
CREATE INDEX cache_relation_index_cache_key ON cache_relation (`cache_key`);
CREATE INDEX cache_relation_index_source_id ON cache_relation (`source_id`);
CREATE TRIGGER on_cache_deleted AFTER DELETE ON cache BEGIN
DELETE FROM cache_relation WHERE cache_key = old.cache_key;
END;
CREATE TRIGGER on_cache_related_deleted AFTER DELETE ON cache_relation BEGIN
DELETE FROM cache WHERE cache_key = old.cache_key;
END; こんな感じでキャッシュ本体 (cacheテーブル)と、そのキャッシュを生成するのに使ったもののid(文字列)のリスト(cache_relationテーブル)を持って、お互いにトリガーで消しあうようにしておく。
こうしておくと、通常のキャッシュキーによる追加・削除だけではなくて、生成元が更新された時に関連するキャッシュをまとめて消せる。
なお、キャッシュ用のDBファイルは元データと分けた。というのも、元データのDBは毎日バックアップとしてGmailに送りつけているので、キャッシュを含めたくなかったから。
![]()
![]()
![]()
1週間前ぐらいまで毎日いろいろと資料を読んでコード書きまくったりしていたけど、例によって急激にやる気が失われてほとんど何もしていない。
という感じで進行した。やる気があるときは「ゲームとかやってる暇全くないし、ゲームとか完全に無駄な時間を過ごすだけ。酒飲んで頭回らない時間をつくるのも無駄」みたいな意識の高さがあるが、そうでないときはとにかく頭を一切使いたくないという感じになる。
ハードウェアまわりは明確にやりたいことはあるけど、途中でやる気がなくなったのでそれ以来全くすすめていない。
ディアブロ3を久しぶりにちょっとやってるけど、目が疲れる。
どっか散歩したいけれど、忌中なので神社には行けない。つつじヶ丘あたりを地図なしで歩いたりしてみたりしたけど気分は晴れず。ストレスは溜まるがやはり解消方法がない。
![]()
![]()
![]()
二重の意味で(出勤も保育園も)はぁ嫌だなあと思いながら保育園に行ったら、保育園が開いていなかった。意味がわからなかったけどとにかく開いていなくて、どうしようもないので帰ってきた。
自分はこういう予期していないトラブルに滅法弱くて、普段に数倍に嫌な気持ちが増幅されるんだけど、そうはいっても現実として「誰が子供の面倒見るの?」という問題を解決しないといけないので、会社を休んだ。
結局なんだったかといえば保育園は諸事情 (特に複雑な事情ではなくて、年間行事表には書いてあった) によって休みだった。昨年は土曜日にあたっていたようで意識しなかったし、休みになるという認識がなかった 。そして今年は直前に子供の発熱があったせいか特別休みの予告がなかったので、誰も休みを認識してなかった。
来年同じことがないようにカレンダーにリピートを入れた。
別に保育園が悪いわけではないけど、ほんと保育園関係は嫌な気持ちになることが多い。暦通りじゃない休みがこんなにアナウンスされないものなのか。
準備して、子供が寝てるとこを起こして(朝食をとったあと、たまに寝ることがある)、だっこして、門まで連れていって、開いてない。平日だから当然出勤するつもりでいる。出勤する人の流れが見えるから平日なのは間違いない。寝ボケていて時間を間違えたのか。開いてないから帰るしかない。おやつやら昼食やらをどうするか考えないといけない。夕方までの間のすごしかたを考えないといけない。スワップアウトされてるもろもろを頭の中のワーキングメモリにロードしなおさないといけない。
![]()
![]()
![]()
自分のイライラするシチュエーションを考えみると「ワーキングメモリに大きなデータをロードする必要がある」ことと「予期してない」ことが大きく関係しているような気がしている。
自分は頭の中のワーキングメモリに、何らかの仕事(プログラム全体の設計とか)をロードするのにとても時間がかかる。このロードされたイメージが何らかの出来事(外部割込み由来)で無駄になるときにイライラする。
保育園なんかで、1円にもならない仕事をやらされたりする。全体としてたいしたことじゃなくても、その仕事をロードするたびに、趣味にしろ仕事にしろ、頭の中のイメージにリセットがかかる。そして再度元の仕事をロードする必要がある。
予期できることもあるけど、そもそもストレスかかる仕事が多いのでコンテキストスイッチが発生するだけで不愉快。
しばしばあるのが、些細な仕様変更・追加で、これにより根本的に直す必要がありそうだというケース。
そういうことが起こらないように、将来的にどんな仕様の追加がありそうかということをエスパーして、予期されるそれらへの変更耐性を設計に組み込んだりするする。そういうのも含めて、ピースをうまく噛み合せて全体的に「これでうまくいきそうだな」というイメージを構築するまで、まずとても時間がかかる。
しかしいろいろ考えたとしても、考慮外の仕様が出現したりする。この「考慮外の追加仕様」はイライラする。というのも
それほど複雑ではない場合は部分的な再構築ですむのでそれほど最悪な気分にはならないが、全体を再構築する必要がありそうな場合は、頭の中を全部一旦空にするので再度全体の設計をロードしなおすまで時間がかかる。その間ずっとイライラしている。
頭の中にロードする時間自体を短縮するのは難しそうなので、イメージのサイズを小さくするとか、予期できそうなことは予期しておくしかない? しかし予期できそうなことを予期しておくというのをやるとイメージのサイズが大きくなる。
そもそも何故頭の中のイメージが初期化されることでイライラするのか。
![]()
![]()
![]()
前提知識:レスポンシブ広告といっても、既定の広告サイズからコンテナサイズによって選ばれて表示されるだけで、広告そのもののサイズは固定です。
そのまま使うと、広告がロードされた時にページの高さの再計算が入って、コンテンツがガタガタと動いて大層鬱陶しいです。とりあえず便利そうだから貼ってみると、この挙動でギョギョっとします。
しかし、レスポンシブ広告はCSSで設定する width/height によって正確に対応する広告サイズを入れることができ、この場合は高さが固定になるのでガタガタしません。CSSなのでメディアクエリでサイズを変えられ、レスポンシブサイトと大変相性が良いです。
公式のドキュメントに詳細な設定方法が書いてあります。といっても width/height をコンテナに設定しているだけです。
既にサイトがメディアクエリによってレスポンシブになっているなら、レスポンシブ広告にした場合、広告サイズもCSSで指定するだけでよくなってます。
「広告コードには一切の変更が認められない」みたいなことが過去に書いてあったような記憶があるんですが (記憶違いかも)、現状では上記の通り、改変が認められるケースがあり、悪意をもってやるようなことじゃなければだいたい大丈夫そうな雰囲気があります。
![]()
![]()
![]()

ティファール ケトル 1.2L ジャスティンプラス サーブル たっぷり 空焚き防止 自動電源OFF 湯沸かし KO340177 cho45
これの古いモデルをずっと(7年ぐらい)つかっていたが、底のステンレス部分が緑色に錆びのようなものができていて、さすがにどうかと思ったので買い替えた。
緑色の何かの正体はよくわからず。こすっても落ちないし使用頻度が高いのでカビではないと思うが、クエン酸を入れて沸かしてもとれなかった。

ティファール ケトル 電気ケトル 0.8L アプレシアプラス メタリックノワール コンパクト 空焚き防止 自動電源OFF 湯沸かし ステンレスボディ BI805D70 cho45
これにした。沸かせる量が減ったが、1.2L 沸かすことがまずなかったように思えるので小さいモデルに。外装がプラスチックのものは嫌だったのでステンレスのものにした。燃費を上げるためか全体を金属にしたものはないみたいだった。
メーカーのページを見てみると、同じメーカーのほぼ同じモデルでも微妙に電気料金が違く書かれている。
例えば、アプレシアプラス(プラスチックモデル)では約0.44円/カップ1杯と書いてあるが、アプレシアプラスメタリックでは約0.50円/カップ1杯となっている。といっても、この差だと365回沸かしてようやく約22円程度の差なので誤差ではありそう。
なお、このメーカーの場合だとスペック上で最も燃費が悪いもので約0.56円/カップ1杯、最も良いもので約0.44円/カップ1杯と、0.12円の差がある。
![]()
![]()
![]()



