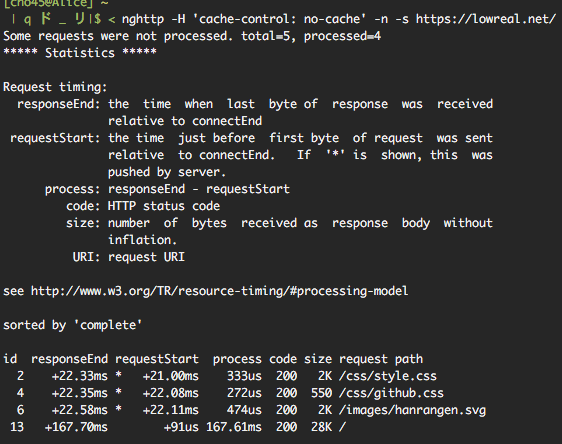
ほとんどのブラウザで、通常リロードは Cache-Control: max-age=0、スーパーリロードで Cache-Control: no-cache がリクエストヘッダとして送られてくるみたいなのですが、実際の挙動はともかく意味の違いがよくわかりませんでした。
RFC7234 によると max-age は
The "max-age" request directive indicates that the client is unwilling to accept a response whose age is greater than the specified number of seconds. Unless the max-stale request directive is also present, the client is not willing to accept a stale response.
no-cache は
The "no-cache" request directive indicates that a cache MUST NOT use a stored response to satisfy the request without successful validation on the origin server.
となっています。読んでも違いがよくわかりません。検索するとWhat's the difference between Cache-Control: max-age=0 and no-cache? あたりがヒットして、古いほうのRFC HTTP/1.1: Caching in HTTPが示されています。
max-age=0 は validate した結果最新とわかったならキャッシュを返すことを許しているが、no-cache はそもそも cache を使うことを許していない、という違いがあるようです。
もっというと、max-age=0 のときは validate して最新なら 304 を返してくれてもいいが、no-cache のときは validate すらせず全て 200 で転送しなおせという意味のようです。
余談:レスポンス時の Cache-Control: no-cache
レスポンス時の Cache-Control: no-cache が語感に反してキャッシュの利用を許可しているというのは良く知られている(?)と思いますが (キャッシュの利用を許可しないのは no-store)、これも max-age=0 との違いがよくわかってませんでした。
これについても上記の stackoverflow でわかりやすい解説があって、Cache-Control: no-cache は実質 Cache-Control: max-age=0, must-revalidate 相当だろうとのことでした。単純な max-age=0 はクライアント側が validate できなければ期限切れのキャッシュ利用を許しているという違いがあるようです。