モールスデコーダの続き
波形ではなくSFFTの結果を認識させる
モールスで必要なのはキャリア周波数の周辺帯域だけ。モールスは通信速度があまり早くなく、帯域幅も100Hz程度のため、周波数分解能と時間分解能にトレードオフのあるSFFTでも、十分解析可能なはずだと思った。
訓練データ
例によってここは node.js で作った。web-audio-engine を使って実際にモールスの信号をつくり、それを AnalyserNode で連続で FFT して画像をつくった。
ラベルデータは考えられるだけでいくつか作りかたがある
- 符号のon/off の正解データ (binary)
- どこからどこまでが、どの符号かのID (categorical)
- その符号を人間が認識できる最短の位置での符号 ID (categorical)
画像として処理するなら、どこからどこまでが符号でその符号が何かがわかればいいが、連続信号として処理したいなら、人間が認識できる最短の位置にラベル付けするのが正しそう、と考えた。
一応どの正解データも作れるのようにデータ生成コードを書いた。
符号のon/offはその後なんらかのアルゴリズムでさらにデコードする必要があるが、モールスの場合はクロックが固定ではないので割と面倒くさい。
ということで早々に符号列のパターンを直接認識させる方法をとることにした。認識させるのはあくまで符号列 (トツーやツートトト) であって、(A や B という文字ではない)
単語単位で認識させることができればもっと精度が上げられそうだけど、コールサイン (パターンはあるがほぼランダム) をとれないと意味がないので、ランダム精度を重視している。
備考
モールスは、人間の場合、速度によってやや異る方法で認識している。
- 10wpm〜15wpm (低速) 「符号」をまとまって捉えられないので「長」「短」の組合せでデコードしている。符号表さえ覚えていればデコード可能。
- 15〜30wpm (標準) ひとつの「符号」をまとめて捉えて直接文字で認識する (トツーときたら「A」と学習している) 音素の認識と似てる。聴覚受信の回路がある程度脳内でできていないと難しい。
- 25〜40wpm (高速) ひとつの「単語」をまとめて捉えて文字列として認識する(ツー ト トトト ツー / TEST や ES / ト トトト) 。特に「E」は「ト」でとても短い符号なので、符号単位に認識していると間に合わない。
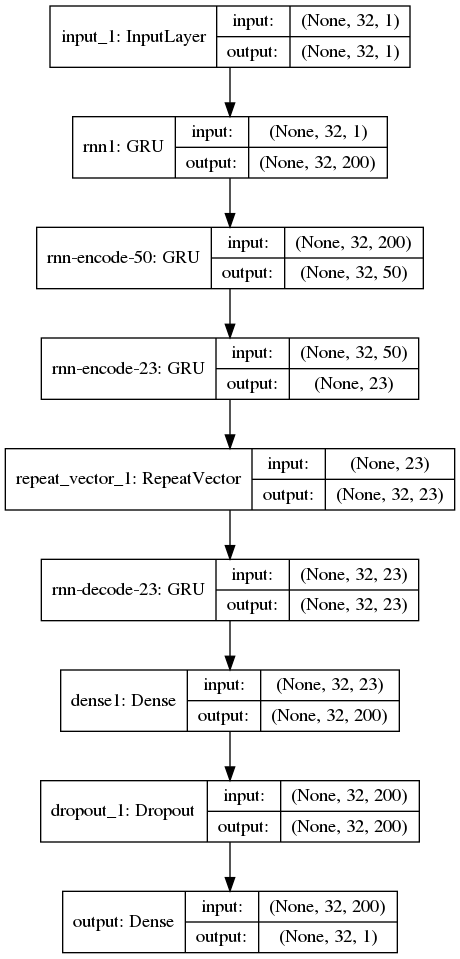
モデル
入力はタイムシリーズ型式 (None, timestep, features) timestep は 72、features はデコード対象周波数を中心とした magnitude。
出力はどのモールスの符号か?を表わす64次元のone-hotベクトル。
いろいろなモデルをつくっては壊して試した。
が、どうもこれではうまくいかなそうだという気がしてきた。2dB (ノイズ帯域500Hz) 程度のSNRでもほぼ認識できない。
関連エントリー
- RNN モールスデコーダの試作 メモ書き。試行錯誤の途中でコードが消えさったりしていてよくないので、やったことだけ書いておく モールスの特徴 信号周波数が固定されており正弦...
- CW の信号帯域とコンスタレーション CW の最小単位である短点の長さ t は以下で求められる。w は符号速度、単位 wpm (通常は 10〜40wpm) 。 5 (トトトトト ...
- トンプソンにもどる ポピュラー曲の左手がさっぱり弾けなすぎるので、諦めてトンプソンの続きに戻った。譜面が簡単なやつでもリズムとるのがとにかく難しい。60bpm ...
- HackRF One で遊ぶ HackRF という SDR 用の無線フロントエンドがある。オープンソースハードウェア。この手のものは他に LimeSDR (高い) や R...
- HS2234 レーザータコメータ (回転数計) HS2234 という名前のレーザー式タコメーターをAliexpressで買った (1300円弱)。2.5rpm〜99999rpm まで測れる...
.png)
.png)
.png)
.png)
![KURE [ 呉工業 ] シリコンスプレ- (420ml) [ For Mechanical Maintenance ] 潤滑・離系剤 [ KURE ] [ 品番 ] 1046 - KURE(呉工業)](https://m.media-amazon.com/images/I/41O9TBUrjZL._SL500_.jpg)
