RNN (時系列) AutoEncoder で遊んでいる
.png)
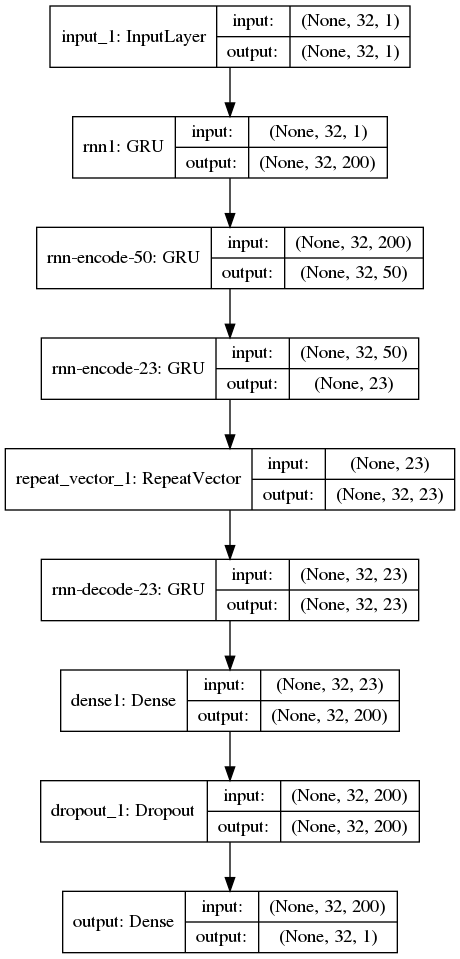
keras を使ってみたらすんなりモデルを書けたので、少し遊んでいる。入出力の shape の意味を理解できれば、詳しいアルゴリズムまで知ることなく遊べるぐらいまで簡単になっていた (だからといって最適なモデルが作れるわけではないけど)
過去の信号列から現在の信号状態を学習した結果、出力として各時点での再構築された信号列が出るわけだけど、これを並べていくと、ネットワークがどういう特徴を学んでいるか伺い知れるところがある。
関連エントリー
- RNN モールスデコーダの試作 メモ書き。試行錯誤の途中でコードが消えさったりしていてよくないので、やったことだけ書いておく モールスの特徴 信号周波数が固定されており正弦...
- 3.5mm ジャック・グラウンドアイソレータ Aliexpress で300円ぐらい。ステレオのグラウンドアイソレータ。結構小さくていい感じ。内部的には(開けてないけど)トランスが2つ入...
- 中古の安定化電源を買った (メトロニクス 524B) LM1972 デジタルボリューム | tech - 氾濫原 に書いたが、正負電源を簡単に用意できない環境だったのが一因で事故が起きたので、も...
- WebAudio でブラウザで動く SDR をつくる 概要 無線機の出す I/Q 信号をサンプリングして 2ch (ステレオ) としてコンピュータに入力し、これを直接 WebAudio から扱っ...
- Notepad-8FX の運用方法メモ そんなに複雑なことをしたいわけではないつもりだが、結果的に若干複雑なので記録しておく。 Notepad-8FX のわかりにくいところ このミ...
.png)
.png)
.png)