✖




asm で動的にメモリ取得をしたいと思っても、malloc は libc の関数であるので、libc 依存しないなら自分で書かねばらない。
ということで、動的なメモリ確保を書いてみる。malloc を書く、というと荷が重すぎるので、単にプロセスが確保するメモリを動的に増やしていく、という大変基礎的な部分だけをやってみる。
まず brk システムコールを試す。brk は program break の意味らしい。program break とはプログラムの data セクションの最後のことで、brk システムコールはこの data セクションの最後の位置を変更するというシステムコールになっている。これにより、プロセスにメモリを割りあてたり、OS に返したりできる。いわゆるヒープ領域というやつ。
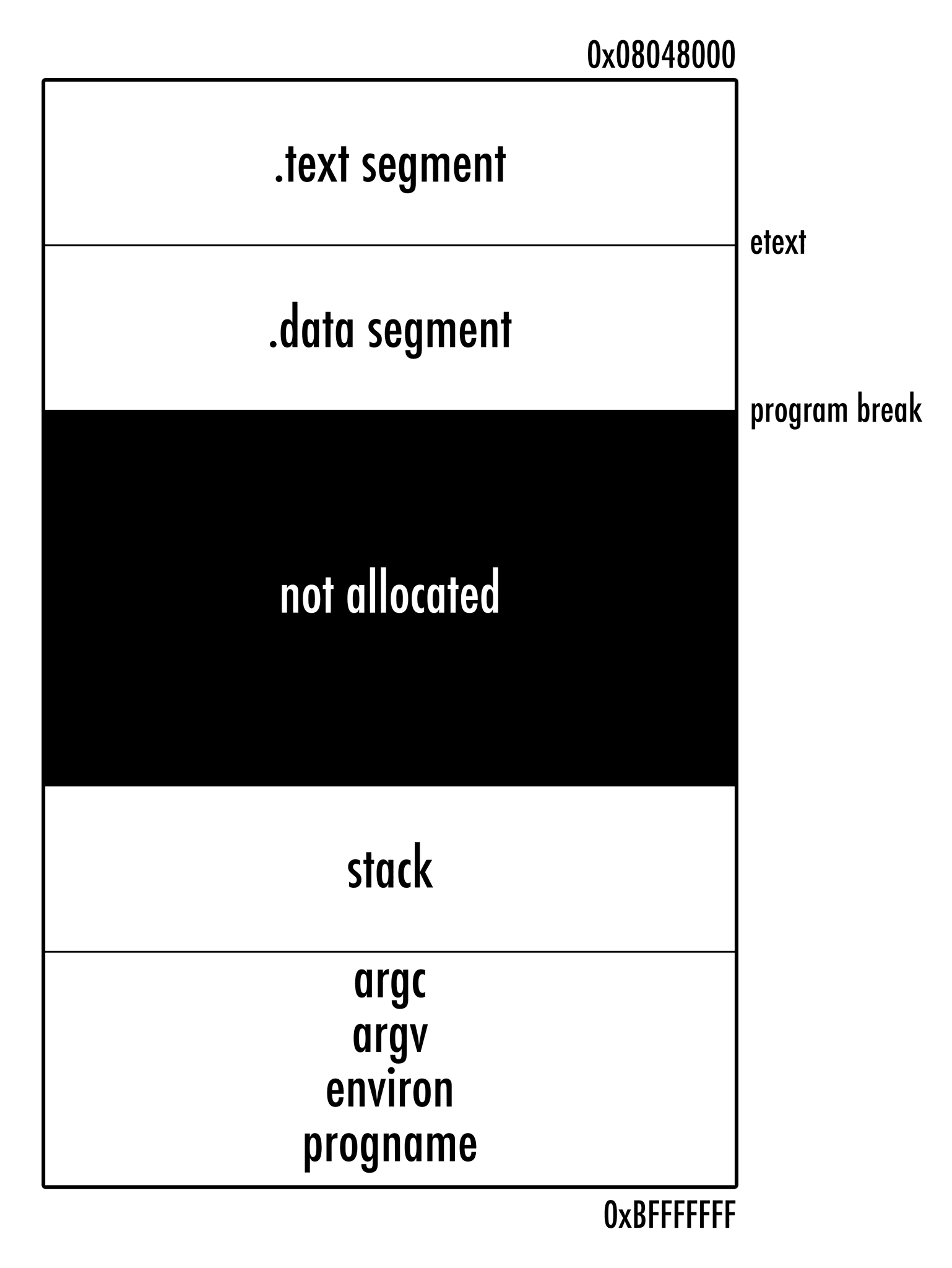
brk システムコールの引数は変更後の program break のアドレスになっている。つまり、初期値をどこかから持ってきて、自分で必要なサイズ分インクリメントして渡さなければならない。
libc レベルでは sbrk という関数も提供されていて、こちらの引数は単に increment (または decrement) する数だけを指定する。要は sbrk 内でアドレス計算をやってくれている。malloc では内部的には直接 brk を使わず sbrk を使ってメモリの取得開放を行っている。
最初この初期値は ld script で定義されている _end (bss セクションの最後を示す) でいいのかなと思い、
brk: .word _end
としてリンク時解決にしてみたけど、gdb でステップ実行しながら brk の返り値を確かめてみると、実際の program break と _end は違うことがわかった。
どこからもってくればいいのかと思ったけど、brk システムコールを 0 で呼んで、現在の brk アドレスを取得すればいいようだ (引数が不正だったり、メモリがない場合 brk は単に現在の break アドレスを返す)。ほんとかと思ったので libc のコードを読んでみたが、libc の sbrk 実装もそのようになっていたので由緒正しい。
機能的には sbrk 相当のものなので sbrk という名前にしてある。r0 に欲しいサイズを入れて bl sbrk すると、要求したバイト数確保して、先頭アドレスを返す。
.macro sys_brk
mov r7, $0x2d
svc $0x00 /* supervisor call */
.endm
sbrk: /* uint size -> void* */
push {lr}
ldr r3, =brk /* r3 = prev_brk */
ldr r1, [r3]
cmp r1, $0x00 /* if prev_brk == 0 */
bleq sbrk_init
add r0, r0, r1
sys_brk
cmp r0, r1
blt sbrk_nomem /* curr_brk == prev_brk */
str r0, [r3] /* update heap_start */
mov r0, r1
pop {pc}
sbrk_init:
push {r0}
mov r0, $0x00
sys_brk
mov r1, r0
pop {r0}
mov pc, lr
sbrk_nomem:
mov r0, $0x00
pop {pc}
.section .data
brk: .word 0 プロセスに動的にメモリを割り当てる方法としては mmap を使う方法もある。mmap の匿名マッピングは単に指定したサイズの連続した領域を確保する。ある程度大きいメモリを確保する場合はこちらのほうが管理が楽みたい。glibc の malloc は 128KB 以上一気に確保しようとすると mmap を使うらしい。
mmap のデメリットはページサイズ単位でしか割当られないことで、1KB だけ欲しい場合でも4KB 程度は割当される。以下の例では 8byte だけリクエストしているが 4096バイトまでは書きこめ、4097バイト目に書こうとすると Segmentation fault になる。
mmap の返り値もエラーの場合は負の数が返るのだけれど、最上位ビットが立っていても有効なメモリアドレスという場合もあるので、単に負かどうかでは判定できない。なんかよくわからないけど、-4096よりも大きい場合だけエラーとして扱いのがセオリーっぽい?
PROT_NONE = 0x00
PROT_READ = 0x01
PROT_WRITE = 0x02
PROT_EXEC = 0x04
MAP_ANONYMOUS = 0x20
MAP_PRIVATE = 0x02
.macro sys_mmap
mov r7, $0xc0 /* sys_mmap_pgoff */
svc $0x00 /* supervisor call */
.endm
.macro sys_munmap
mov r7, $0x5b
svc $0x00 /* supervisor call */
.endm
main:
/* mmap */
mov r0, #0 /* start */
mov r1, #8 /* length */
mov r2, #PROT_READ /* prot */
orr r2, r2, #PROT_WRITE
mov r3, #MAP_ANONYMOUS
orr r3, r3, #MAP_PRIVATE /* flags */
mov r4, #-1 /* fd */
mov r5, #0 /* page offset */
sys_mmap
cmn r0, #4096 /* if (r0 > -4096) */
rsbhs r0, r0, #0
blhs error
mov v1, r0
/* write 4096 bytes (SEGV on 4097) */
mov r2, r0
ldr r3, =4096
1:
mov r0, $0x2e
strb r0, [r2], $0x01
sub r3, r3, #1
cmp r3, #0
bne 1b
mov r0, $0x01
mov r1, v1
mov r2, #4096
sys_write
mov r0, v1 /* start */
mov r1, #8 /* length */
sys_munmap
mov r0, $0x00 /* set exit status to 0 */
sys_exit
error:
cmp r0, $0x00
moveq r0, $0x01
sys_exit malloc はどっちも使っているようだけど、いまいち brk を使うメリットがわからない。
よくわからなかった。
glibc 以外の malloc 実装を軽く調べた感じだと、OpenBSD は mmap しか使わず、jemalloc もオプションで指定しない限り mmap だけを使うようだった。