類似画像検索をOKLCH色空間で再実装
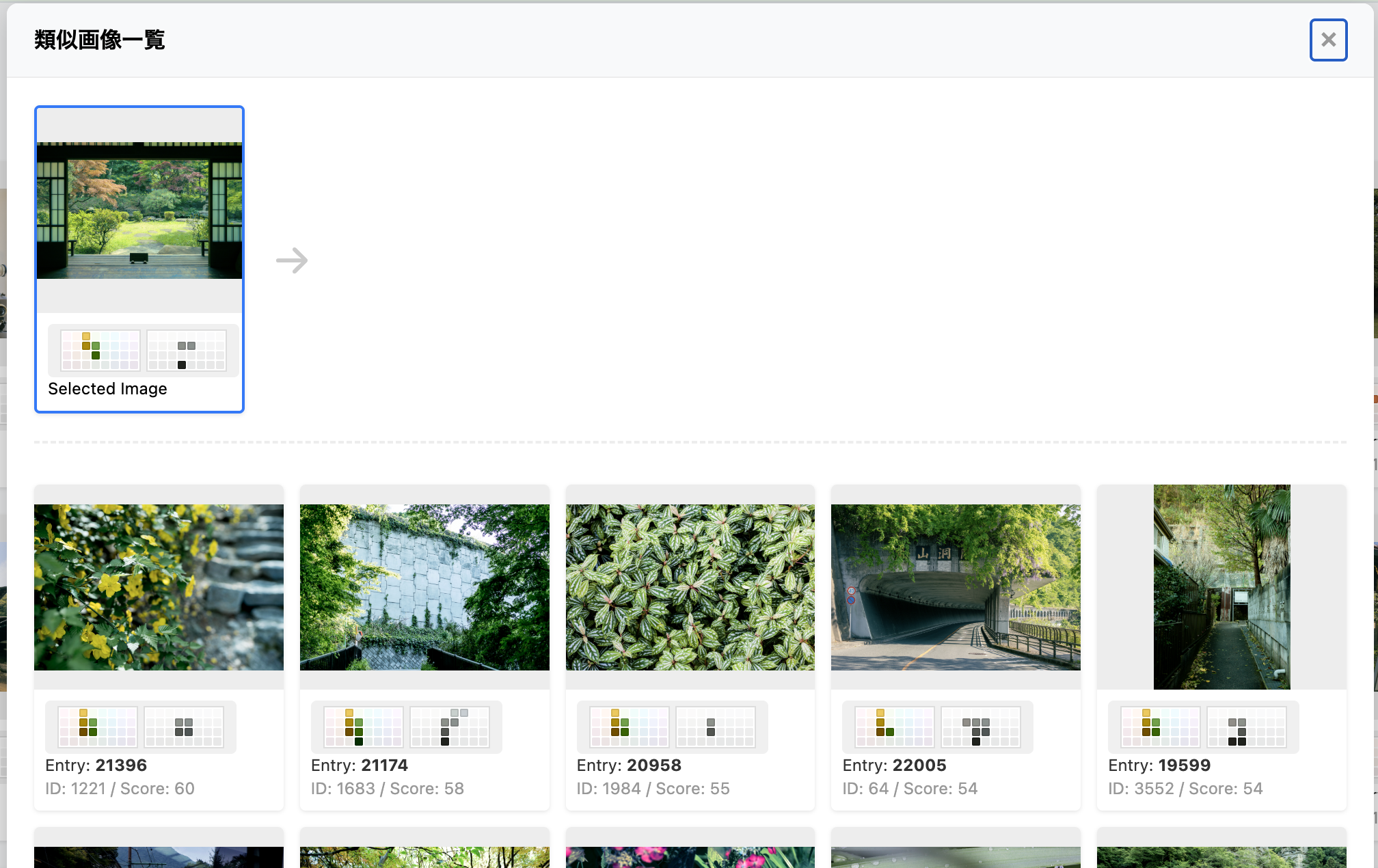
類似画像検索まわりをだいぶいじった。Perl の実装では Libpuzzle を適当に使ったやつだったが、独自実装に変えてみた。↑ の画像は管理画面
3次元のヒストグラム
「類似」をどうするかをこの日記においては色の傾向が似ている (形は無視する) としてみる。意図としては「雰囲気が似ている」画像を出すというのを目標にするもの。
つまりヒストグラムの比較で類似性を判断する。
人間の色認知は3次元の色空間で表現されるので、この3次元空間をそれぞれの次元で均等に区切り (バケツに比喩される)、各ピクセルをそれぞれ、その空間(バケツ)に放りこむ。
使う色空間を OKLCH に
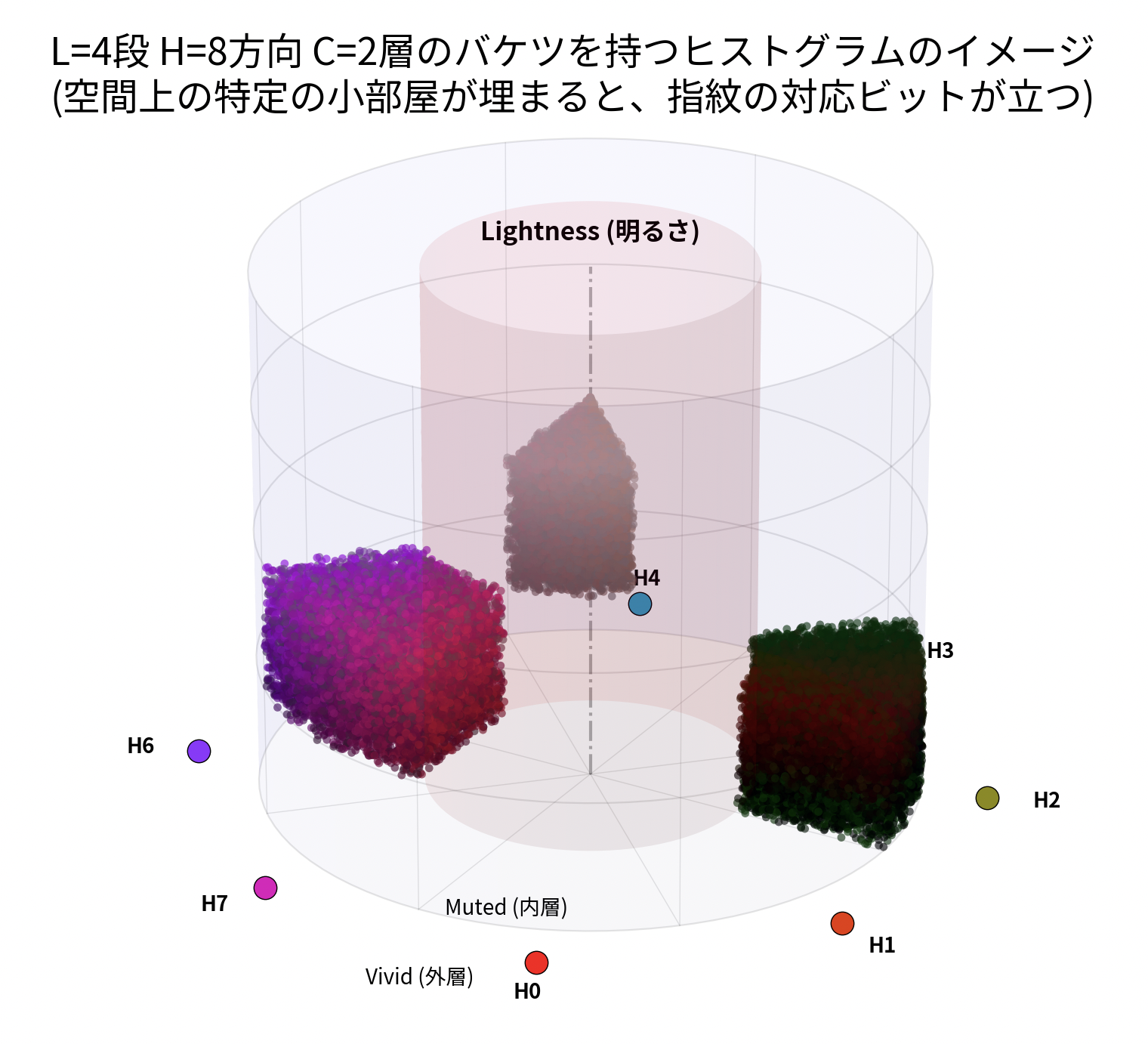
RGB の3次元でもヒストグラムは作れるけど、距離が知覚と一定ではない問題があるので、ビットごとに知覚的な空間との間に乖離がある。ちょうどいい色空間として、人間の知覚的に均等な距離を持つ OKLCH 空間があるのでこれを使ってみることにした。
こうすることで知覚とバケツのサイズを一致させ、1ビットの価値を均等にできる。
ヒストグラムのエンコーディング (64bitのビットマスク化)
集計したヒストグラムをそのまま保存するとデータ量が大きいため、各バケツのピクセル数(頻度)を保存するのではなく、「その色が画像の中に一定以上(例えば面積の3%以上)存在するかどうか」という 0 か 1 かのフラグに変換して保存する。
これを 64個のバケツすべてで行うと、画像は 64ビットの1つの整数(シグネチャ) として表現できる。これが画像の「色の指紋」となる。
OKLCH を使うと書いたけど、L(明るさ)、C(彩度)、H(色相)を、それぞれビット位置として L:2bit (4段階) C:1bit (2段階) H:3bit (8方向) と配分した。Lab ではなく LCH を使うことで H に多くのビットを割くということができる。
これでバケツごとに1bit(有無)に情報圧縮される。バケツは「こんな感じの色」という単位なので、「こんな感じの色が含まれている」という集合の状態になる。同時にこれは画像全体のサイズによって正規化されている。
類似度の計算(Jaccard 係数)
最終的に画像同士のシグネチャ、実体としては色の集合のビットマスクを比べる際は Jaccard(ジャカード)係数 を使う。これは「共通して持っている色の数」を「両方の画像のどちらかに存在する色の総数」で割ったものであり、パレット(色の品揃え)がどれだけ重なっているかとして評価できる。
ただこれを全画像に毎回やるのは大変なので SQL で検索可能にするための工夫をする。
検索の高速化 (ngram)
似ているビットマスクを検索する手段として、ビットをいくつかに分割してngramにして保存しておくという方法が使われる。別に任意のビットマスクでよく使わる方法で特別な方法ではない。
ここでは1ビットごとにずらした12bitをそのパターンのオフセット位置を共に、52個のワードとして保存する。つまり1つの画像は64bitのシグネチャにされたあと、この64bitをスライディングウィンドウで12bitずつ切り出して保存し、これにインデックスを貼る。
そして類似画像の検索時は、このインデックスを利用して、部分マッチするものを先に足切りしてとってくる。SQL レベルで「同じ明るさ・色相の場所に、同じ色の塊を持っている画像」をピンポイントで引き抜くことができる。
空間充填曲線(Z-order)による ngram の高密度化
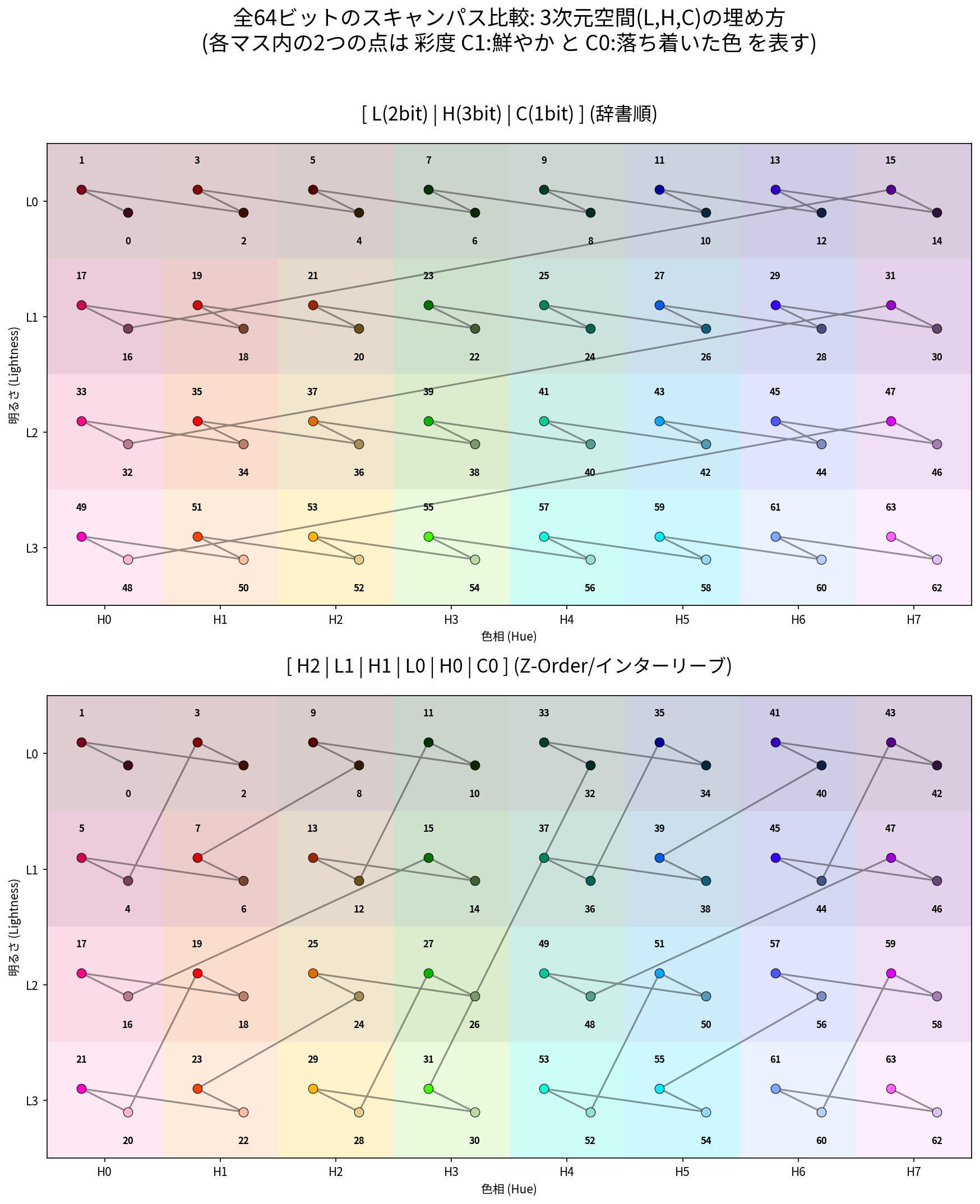
さらに、この検索用の12ビットの窓にも、より多くの「関連する色」を詰め込むため、Z-order (Morton order) を採用してビットのアドレスを決定する。
これにより、1次元のビット列上でも3次元的な色の近接性が保たれ、1つの ngram が「色空間上の意味のある局所的なボリューム」を指紋として表現できるようになる
具体的には図の上ように、単にLCHをそれぞれ L=2bit, C=1bit, H=3bit としてビットを構築すしたままだと、ところどころ色が離れた場所にジャンプしてしまう。これを下のようにビットインターリーブ(z-order化)することで、12bitの情報を均等にできる。
関連エントリー
- Stable Diffusion 日記 #26 なんかどっかで見たことあるけど画像検索しても類似画像としては上がってこないのでモヤっとする感じの
- ✖ redeveloped タグをつけてる写真は過去の写真を演出… | Thu, Jul 13. 2017 - 氾濫原 をやろうと思って、画像ハ...
- ✖ redeveloped タグをつけてる写真は過去の写真を演出を変えて再現像したものになってる。 なので、過去のエントリがあるならリンクを貼り...
- MySQL で SET 型の UPDATE 以下のようなテーブルのとき CREATE TABLE foo ( aset set('aaa', 'bbb', 'ccc') ); 空文字列...
- 12bit DAC 2つで 24bit DAC? MCP4922 などの使用例に書いてあるやつを考えてみる。http://akizukidenshi.com/download/MCP4922...