モールス(時系列データ)の機械学習

機械に機械学習のモデルを設計してもらう(何もわからない)の続きで、モールスの機械学習をちまちま諦めずにやってる。
PCEN (Per-Channel Energy Normalization)
音声データは非常にダイナミックレンジが広いので、なんらかの方法でノーマライズしないと、いざ実世界の、スケール 40dBぐらい違うデータを推論しようとしてもうまくいかない。
PCEN はなんかそういう圧縮してスケールする正規化をモデルの中に組込むというやつ。ちゃんと実装できているかはわかなないが挙動からするとできているのだろう……
もう少し実践的なデモ
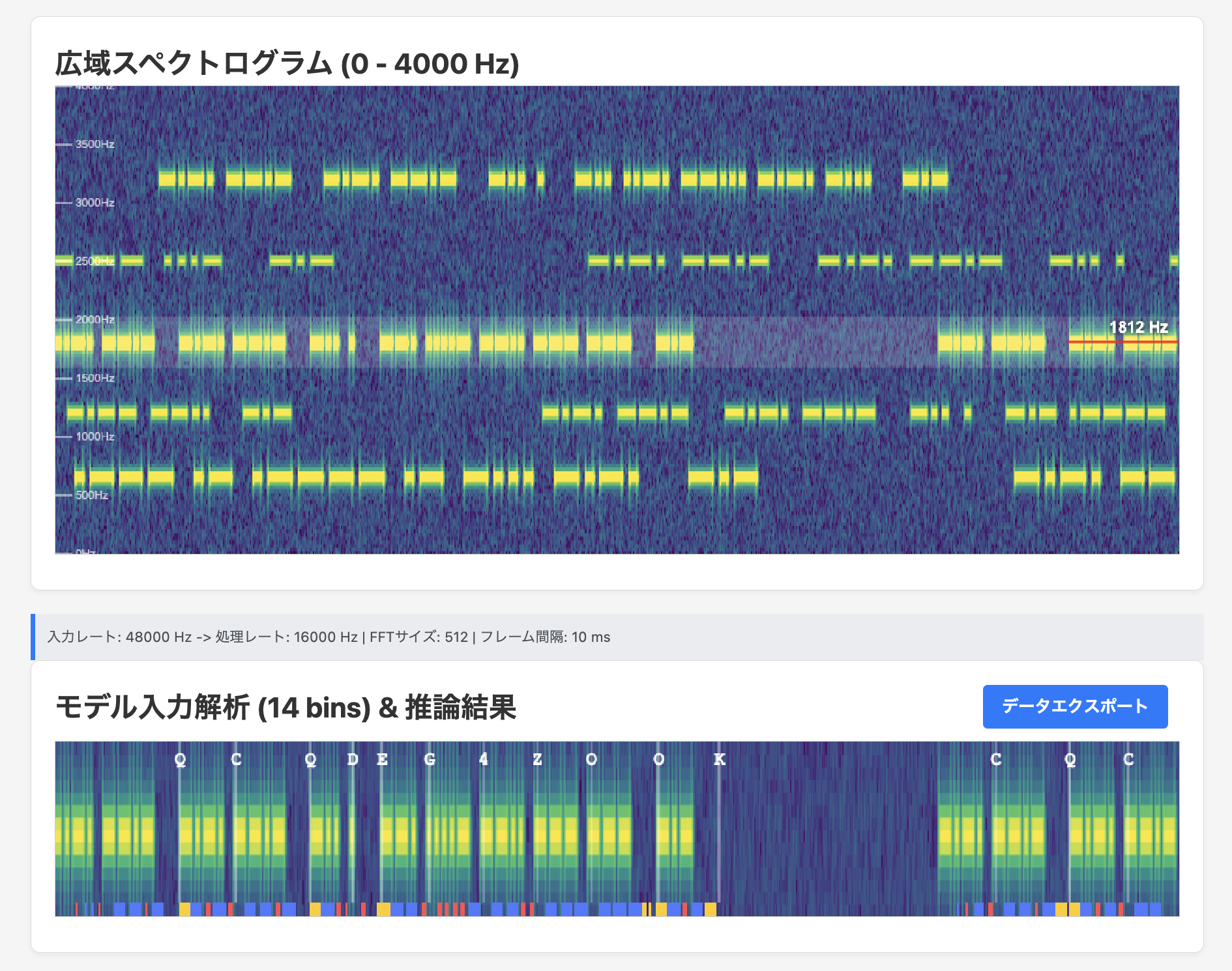
実際にオーディオストリームから広域をFFTしつつ、一部をクロップして連続推論するというデモをつくった (マイク入力に対応)。
「しばらく動かすと推論がエラーで止まる」という現象が発生してこまった。onnx のエラーが出るのだけど、WASM のポインタアドレスが throw されてくるのでまるで情報がない。
Python 側では起きないので、ずっとJS側の実装でメモリ管理がおかしいことを疑っていたが、結局 Claude Opus 君が「モデルのマスク管理がおかしいです!」ということに気付いてくれてなおすことができた。ひさびさに Claude に感動したわ。Python 側で再現しなかったのは長時間連続のストリーム推論することがないからだった。
先読みの実装
当初から「先読み」を実装していたつもりだったのに、この期に及んで、まったく先読みできていなかったことが発覚。わたくし衝撃です。先読みせずにそこそこ精度が出てたのはすごいが…… 一応文字が確定するタイミングでCTC発火するように調整していたので、非因果的なのは長点・短点・単語間空白などを予測するヘッドだけだったはずではある。機械学習、こういう間違った実装されてても、ある程度はなんとかなっちゃうことがあるので本当に怖い。
ということで、時系列データの場合とにかく因果性というのが問題になって、常に頭を悩ませる。こんがらがってくる。ラベル自体をオフセットするのか? アテンションに未来を見せるのか? そして、コーディングエージェントは時系列というものが苦手なので、人間がちゃんと理解してテストを書かせてないとダメなのだ…… 普通につらい。
前回も言ったけどコーディングエージェントはとにかくテストを書きたがらない。いくら言ってもダメ。AGENTS で指定しても意味あるのは初回ぐらい。テストで動作を保証する発想が一切ない。ゴミスクリプトをチョチョッっと作って実行してはゴミ掃除もせず放置する。
関連エントリー
- RNN (時系列) AutoEncoder で遊んでいる keras を使ってみたらすんなりモデルを書けたので、少し遊んでいる。入出力の shape の意味を理解できれば、詳しいアルゴリズムまで知る...
- 機械に機械学習のモデルを設計してもらう(何もわからない) 主に Gemini を使って、LLM主体でモデルの設計と学習をなるべくさせてみるということに数日とりくんでた。 自分が知らないことをLLMに...
- 39歳 2006年から開発のバイトはじめてるから20年ぐらい仕事としてプログラム書いたことになるっぽい。あんまり誕生日に日記書いてないので、単に遡る...
- RNN/LSTM/GRU の入力と stateful 化 (keras) 入力データ (batch_size, timesteps, features) が入力になる。batch_size はこのバッチ(学習・予測...
- Chemr (Chemrtron) を再実装 Electron の非互換変更で大幅なアーキテクチャ変更を余儀無くされた時点でやる気がなくなってしまい、10年ぐらい前から触ってなかった C...