


✖
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
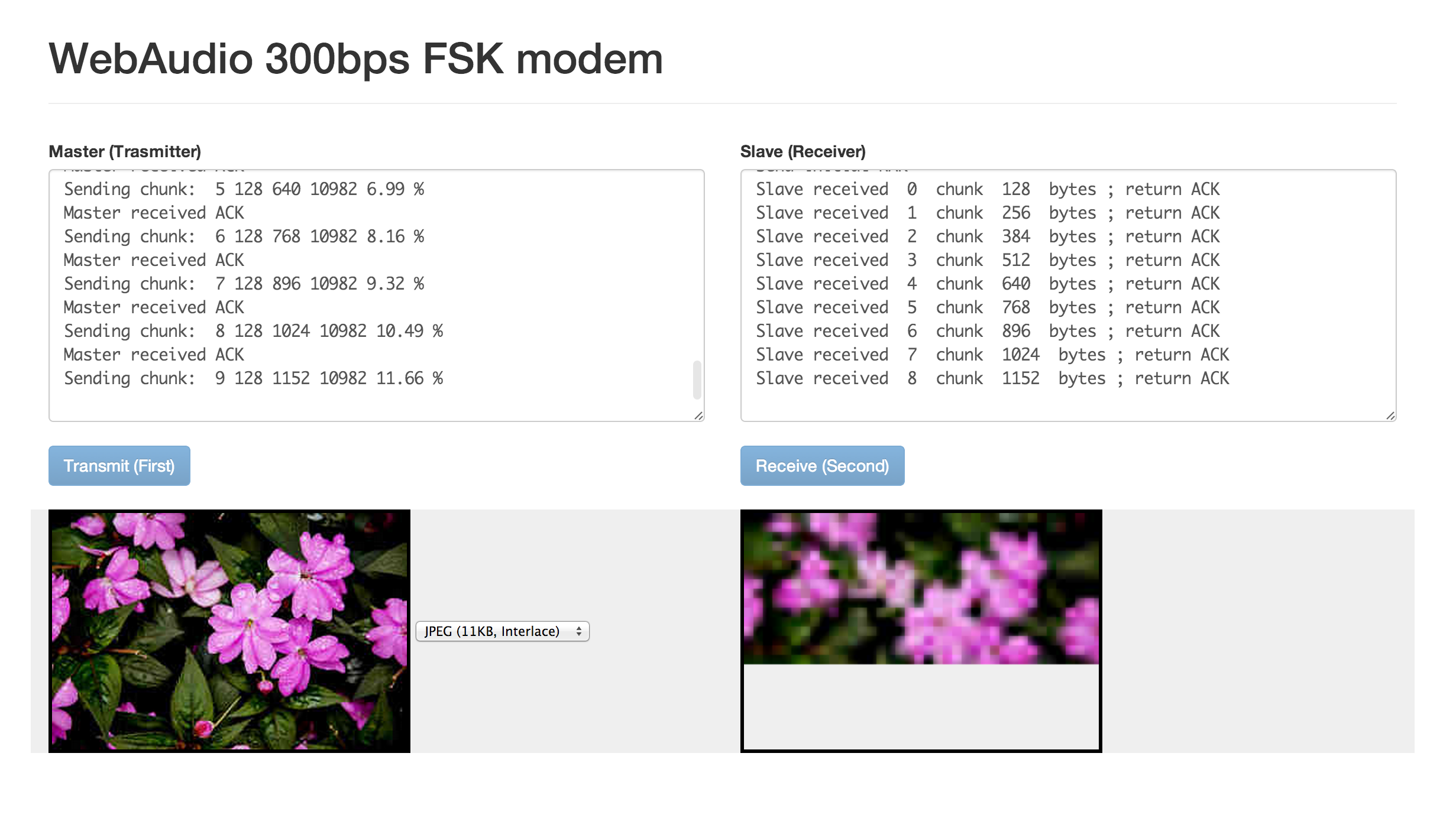
我々は、ブラウザの WebAudio サポートによって、空気をメディアに使う方法を手に入れた。これにより、またひとつクロスドメイン通信の方法が増えたといえよう。
知っている人は少ないと思うが、古代人は空気によって伝送できる程度の周波数を用いてデータ伝送を行っていたという記録が残っている。これは失われた暗黒の技術であって、現在ではもはや ITU という国連の機関によってその存在の記録が残されているのみである。
小さな画像を音声帯域を使って送受信する
実際にマイク入力を使う場合、
マイク入力はやはり難しくて、周囲の環境によって波形が乱れるとうまくいかなかったりする。
ITU-T 勧告 V.21 は全二重 300bps の通信プロトコルで、変調方式は単純な FSK (周波数変移変調) になってる。
FSK (周波数変移変調) は、2つの周波数をそれぞれ 1 と 0 とに割当てて、切替えながら送信することでデータを送信する変調方法。単純でノイズに強いのが特徴。
かなり面倒くさがって WebAudio だけに依存するように書いたので、いちいち全サンプルに対して処理をしていてとても重い。アルゴリズム自体にも、もっと根本的にいい方法がありそうだけれど、知らないので直交信号をそれぞれヘテロダインする方法にしてある。
このへん、ノウハウがなさすぎて精度良く検出するのが僕にはかなり難しかった。
FSK 部分は以下
既設の電話回線をデータ通信に応用する技術なので、可聴帯域の周波数を搬送波に使っており、全二重なのでチャンネルが2つある。つまり使う周波数は4つ。
WebAudio + 空気の場合、別にこの帯域に拘る必要はなくて、可聴域限界ぎりぎりまで周波数をあげてもいいと思う。実際そのようにしても動くし、速度もあがるしモスキート音なのであまり煩くなくなる。今回はそれだとモデムっぽさがなくなってカッコよくないのでやめた。
プロトコルは以下のようにした
でバイト単位のやりとりをする。1バイトにつき10.5bit使うので、最大で 28.6bytes/sec ぐらい。
さらにまとまったデータ送信のプロトコルとして以下のような xmodem ライクな実装を書いた
データ部は「SOH, データブロック番号, ビット反転したデータブロック番号」をヘッダにして、最後に CRC8 を付与している。これらが意図した値でなかった場合 NAK を返し、該当ブロックの再送要求をする。また、途中でバイト単位のやりとり自体が失敗した場合にそなえてタイムアウトによる再送もやってある。
ポエティックでフィクションな前文を書くのを広めたい。
![]()
![]()
![]()
たとえ全く使ったことがない言語であっても、それがスクリプト言語であれば1日もかからない内容をアセンブリ言語で実装するということは、時間リソースを大変富豪的に使うプログラミングである。
あまり仕様が多いとつらいので絞りに絞り以下だけ実装することにした
制限事項など
せっかくなので覚えたことを使おうと以下のようにしてある。大変メモリとシステムコールを富豪的に使う
/*#!as --gstabs+ -o blosxasm.o blosxasm.s && ld -o blosxasm -e _start blosxasm.o && objdump -d -j .text -j .data blosxasm && ./blosxasm
*/
.global _start
.macro sys_exit
mov r7, $0x01 /* set system call number to 1 (exit) */
svc $0x00 /* supervisor call */
.endm
.macro sys_read
mov r7, $0x03
svc $0x00 /* supervisor call */
.endm
.macro sys_write
mov r7, $0x04
svc $0x00 /* supervisor call */
.endm
O_RDONLY = 0x0000
.macro sys_open
mov r7, $0x05
svc $0x00 /* supervisor call */
.endm
.macro sys_close
mov r7, $0x06
svc $0x00 /* supervisor call */
.endm
.macro sys_getdents
mov r7, $0x8d
svc $0x00 /* supervisor call */
.endm
.macro sys_stat
mov r7, $0x6a
svc $0x00 /* supervisor call */
.endm
.macro sys_brk
mov r7, $0x2d
svc $0x00 /* supervisor call */
.endm
PROT_NONE = 0x00
PROT_READ = 0x01
PROT_WRITE = 0x02
PROT_EXEC = 0x04
MAP_ANONYMOUS = 0x20
MAP_PRIVATE = 0x02
.macro sys_mmap
mov r7, $0xc0 /* sys_mmap_pgoff */
svc $0x00 /* supervisor call */
.endm
.macro sys_munmap
mov r7, $0x5b
svc $0x00 /* supervisor call */
.endm
.macro sys_mremap
mov r7, $0xa3
svc $0x00 /* supervisor call */
.endm
.section .data
brk: .word 0
config:
var_title:
.ascii "blosxasm-arm-linux-eabi"
var_title_len = . - var_title
.align 2
var_home:
.ascii "/blosxasm.cgi/"
var_home_len = . - var_home
.align 2
var_data_dir:
.asciz "data/"
.align 2
var_head_path:
.asciz "head.html"
.align 2
var_story_path:
.asciz "story.html"
.align 2
var_foot_path:
.asciz "foot.html"
.align 2
.section .text
_start:
mov lr, #0
/* r0 = argc (not used) */
ldr r0, [sp]
/* r1 = argv (not used) */
add r1, sp, $0x04
/* r2 = argc * 4 (skip argv) */
mov r3, $0x04
mul r2, r0, r3
/* skip null word */
add r2, r2, $0x04
add r2, r1
/* save char** environ */
ldr r0, =environ
str r2, [r0]
bl main
mov r0, $0xff
sys_exit
main:
adr r0, PATH_INFO
bl getenv
cmp r0, $0x00 /* if env is not set */
adreq r0, PATH_INFO_default
mov v5, r0 /* v5 = PATH_INFO */
bl strlen
cmp r0, $0x00 /* if env is set but empty */
adreq v5, PATH_INFO_default
ldr r0, =var_head_path
bl template
/**
* append entry to brk (like dynamic array)
*/
mov r0, $0x00
bl sbrk
mov v1, r0 /* v1 = first brk */
ldr r0, =var_data_dir
ldr r1, =file_callback
bl dentries
/**
* loop each entry
*/
ldr v2, =entries_count
ldr v2, [v2] /* v2 = entry count */
ldr v3, =current_entry /* v3 = pointer to current entry address */
main_entry_loop:
str v1, [v3]
/* findstr(entry.name, path_info+1, strlen(path_info)-1) */
mov r0, v5
bl strlen
sub r2, r0, #1
add r0, v1, #entry_path
add r1, v5, #1
bl findstr
cmp r0, $0x00
ldreq r0, =var_story_path
bleq template
sub v2, v2, $0x01
cmp v2, $0x00
add v1, v1, #entry_buffer_len
bne main_entry_loop
ldr r0, =var_foot_path
bl template
mov r0, $0x00 /* set exit status to 0 */
ldr r1, =buffer
sys_exit
file_callback:
stmfd sp!, {r1-r3, v1-v5, lr}
mov v1, r0 /* v1 = name */
mov v2, r1 /* v2 = name_len */
/* skip . files */
ldrb r0, [v1]
cmp r0, #'.
bleq 1f
mov r0, v1
bl read_entry
1:
ldmfd sp!, {r1-r3, v1-v5, pc}
USER:
.asciz "USER"
.align 2
PATH_INFO:
.asciz "PATH_INFO"
.align 2
PATH_INFO_default:
.asciz "/"
.align 2
error:
cmp r0, $0x00
moveq r0, $0x01
sys_exit
divmod: /* uint numerator, uint devider -> quo, rem */
stmfd sp!, {v1-v5, lr}
mov v1, r0 /* num */
mov v2, r1 /* div */
mov r0, $0x00 /* quo */
mov r1, $0x00 /* rem */
mov r2, #32 /* i */
1:
sub r2, r2, $0x01
/* rem = rem << 1*/
mov r1, r1, LSL #1
/* num >> i */
mov r3, v1, LSR r2
/* num & 1 */
and r3, r3, #1
/* rem[0] = num[i] */
orr r1, r1, r3
/* rem >= div */
cmp r1, v2
subge r1, r1, v2
movge r3, #1
orrge r0, r0, r3, LSL r2
cmp r2, $0x00
bne 1b
ldmfd sp!, {v1-v5, pc}
base10: /* int numerator, char* buffer -> int length */
stmfd sp!, {v1-v5, lr}
mov v1, r1
mov v2, $0x00 /* length */
1:
mov r1, #10
bl divmod
push {r1} /* for getting digit from top */
add v2, v2, $0x01
cmp r0, $0x00
bne 1b
mov r2, v2
2:
sub r2, r2, $0x01
pop {r0}
add r0, r0, $0x30
strb r0, [v1], $0x01
cmp r2, $0x00
bne 2b
mov r0, $0x00
strb r0, [v1]
mov r0, v2
ldmfd sp!, {v1-v5, pc}
base16: /* int numerator, char* buffer -> int length */
stmfd sp!, {v1-v5, lr}
mov v1, r1
mov v2, $0x00 /* length */
1:
and r1, r0, $0x0f
cmp r1, $0x09
addle r1, r1, $0x30
addgt r1, r1, $0x57
push {r1}
add v2, v2, $0x01
mov r0, r0, LSR #4
cmp r0, $0x00
bne 1b
mov r2, v2
2:
sub r2, r2, $0x01
pop {r0}
strb r0, [v1], $0x01
cmp r2, $0x00
bne 2b
mov r0, $0x00
strb r0, [v1]
mov r0, v2
ldmfd sp!, {v1-v5, pc}
strncmp: /* char* s1, char* s2, size_t len -> 1|0 */
stmfd sp!, {v1-v5, lr}
mov r3, $0x00 /* result */
1: cmp r2, $0x00
beq 2f /* if (r2 == 0) goto 2 */
sub r2, r2, $0x01 /* len-- */
ldrb r4, [r0], $0x01
ldrb r5, [r1], $0x01
cmp r4, r5
addne r3, $0x01
beq 1b
2:
mov r0, r3
ldmfd sp!, {v1-v5, pc}
strlen: /* char* str -> uint */
stmfd sp!, {r1-r2, lr}
mov r1, $0x00
/* r2 = *str++ (ldrb = load byte, and r0 increment after) */
1: ldrb r2, [r0], $0x01
cmp r2, $0x00
addne r1, r1, $0x01 /* if (r2 != 0) r1++ */
bne 1b /* if (r2 != 0) goto 1; */
mov r0, r1
ldmfd sp!, {r1-r2, pc}
strcpy: /* char* dest, char* src -> dest */
stmfd sp!, {r0-r2, lr}
1:
ldrb r2, [r1], $0x01
strb r2, [r0], $0x01
cmp r2, $0x00
bne 1b
ldmfd sp!, {r0-r2, pc}
strcat: /* char* dest, char* src -> dest */
stmfd sp!, {r0-r2, v1-v5, lr}
1:
ldrb r2, [r0], $0x01
cmp r2, $0x00
bne 1b
sub r0, r0, $0x01
2:
ldrb r2, [r1], $0x01
strb r2, [r0], $0x01
cmp r2, $0x00
bne 2b
ldmfd sp!, {r0-r2, v1-v5, pc}
findstr: /* char* str, char* search, int len_of_search -> uint */
stmfd sp!, {v1-v5, lr}
mov v1, r0
mov v2, r1
mov v3, r2
mov v4, v1 /* save original address */
cmp v3, $0x00
moveq r0, $0x00
ldmeqfd sp!, {v1-v5, pc}
1:
ldrb r0, [v1]
cmp r0, $0x00
beq 2f
mov r0, v1
mov r1, v2
mov r2, v3
bl strncmp
cmp r0, $0x00
addne v1, $0x01
bne 1b
sub r0, v1, v4
ldmfd sp!, {v1-v5, pc}
2:
mov r0, #-1
ldmfd sp!, {v1-v5, pc}
sbrk: /* uint size -> void* */
push {lr}
ldr r3, =brk /* r3 = prev_brk */
ldr r1, [r3]
cmp r1, $0x00 /* if prev_brk == 0 */
bleq sbrk_init
add r0, r0, r1
sys_brk
cmp r0, r1
blt sbrk_nomem /* curr_brk == prev_brk */
str r0, [r3] /* update heap_start */
mov r0, r1
pop {pc}
sbrk_init:
push {r0}
mov r0, $0x00
sys_brk
mov r1, r0
pop {r0}
mov pc, lr
sbrk_nomem:
mov r0, $0x00
pop {pc}
getenv: /* char* name -> char* */
stmfd sp!, {v1-v5, lr}
/* v1 = name */
mov v1, r0
/* v2 = strlen(r0) */
bl strlen
mov v2, r0
/* v3 = environ char** */
ldr v3, =environ
ldr v3, [v3]
1: /* if (strncmp(name, *environ, len) == 0) { */
mov r0, v1
ldr r1, [v3]
mov r2, v2
bl strncmp
cmp r0, $0x00
/* if (*environ)[len] == '=') { */
ldreq r0, [v3]
ldreqb r0, [r0, v2]
cmpeq r0, #'=
beq 2f
/* } */
/* environ++ */
add v3, $0x04
/* *environ != NULL */
ldr r1, [v3]
cmp r1, $0x00
bne 1b
/* not found return NULL */
mov r0, $0x00
ldmfd sp!, {v1-v5, pc}
2: /* found and return address */
ldreq r0, [v3]
add r0, r0, v2
add r0, r0, $0x01 /* skip '=' */
ldmfd sp!, {v1-v5, pc}
dentries: /* char* path, (void)(callback(name, name_len)) */
stmfd sp!, {r1-r3, v1-v5, lr}
mov ip, r1
/* open */
mov r1, #O_RDONLY
sys_open
cmp r0, $0x00
rsble r0, r0, #0
blle error
mov v1, r0
1:
/* getdents */
mov r0, v1
ldr r1, =dentry_buffer
mov r2, #dentry_buffer_len
sys_getdents
cmp r0, $0x00
beq 2f
mov v2, r0 /* read bytes */
rsblt r0, r0, #0
bllt error
ldr v3, =dentry_buffer
3:
ldrh v5, [v3, #8] /* linux_dirent d_reclen */
add r0, v3, #10
mov r1, v5
sub r1, r1, #12
blx ip /* callback */
sub v2, v2, v5 /* len -= d_reclen */
add v3, v3, v5 /* buffer += d_reclen */
cmp v2, $0x00
bne 3b
b 1b
2:
/* close */
mov r0, v1
sys_close
ldmfd sp!, {r1-r3, v1-v5, pc}
read_stat: /* char* name */
stmfd sp!, {r0-r3, v1-v5, lr}
ldr r1, =stat_buffer
sys_stat
cmp r0, $0x00
rsblt r0, r0, #0
bllt error
ldmfd sp!, {r0-r3, v1-v5, pc}
read_entry: /* char* name, int name_len */
stmfd sp!, {r1-r3, v1-v5, lr}
mov v1, r0
/* expand heap */
mov r0, #entry_buffer_len
bl sbrk
mov v3, r0 /* v3 = entry_address */
/* copy path */
add r0, v3, #entry_path
mov r1, v1
bl strcpy
/* r0 = ["data/" + name] */
ldr r0, =buffer
ldr r1, =var_data_dir
bl strcpy
mov r1, v1
bl strcat
mov v1, r0 /* v1 = path adr */
mov r0, v1
bl read_stat
/* copy mtime */
ldr r0, =st_mtime
ldr r0, [r0]
str r0, [v3, #entry_mtime]
ldr v2, =st_size
ldr v2, [v2] /* v2 = file size */
push {r4, r5}
/* mmap for file contents */
mov r0, #0
mov r1, v2
mov r2, #PROT_READ
orr r2, r2, #PROT_WRITE
mov r3, #MAP_ANONYMOUS
orr r3, r3, #MAP_PRIVATE
mov r4, #-1
mov r5, #0
sys_mmap
cmn r0, #4096
rsbhs r0, r0, #0
blhs error
mov r3, r0 /* r3 = mmapped address */
pop {r4, r5}
str r3, [v3, #entry_title]
/* open */
mov r0, v1
mov r1, #O_RDONLY
sys_open
cmp r0, $0x00
rsble r0, r0, #0
blle error
mov v5, r0 /* v5 = fd */
/* read */
1:
mov r0, v5
mov r1, r3
mov r2, #4096
sys_read
cmp r0, $0x00
rsblt r0, r0, #0
bllt error
add r1, r0
bne 1b
/* close */
mov r0, v5
sys_close
/* find first \n */
mov r0, r3
2:
ldrb r1, [r0], $0x01
cmp r1, $0x0a
cmpne r1, $0x00
bne 2b
/* replace first \n to \0 to splitting title and body */
mov r1, $0x00
strb r1, [r0, #-1]
str r0, [v3, #entry_body]
ldr r0, =entries_count
ldr r1, [r0]
add r1, r1, $0x01
str r1, [r0]
ldmfd sp!, {r1-r3, v1-v5, pc}
template: /* char* name */
stmfd sp!, {r0-r3, v1-v5, lr}
/* open() */
mov r1, #O_RDONLY
sys_open
cmp r0, $0x00
beq error
mov v1, r0 /* v1 = fd */
ldr v2, =buffer /* v2 = buffer */
mov r1, v2
mov r2, #4096
sys_read
mov v3, r0 /* v3 = length */
mov r0, $0x00
strb r0, [v2, v3] /* null terminate */
1:
mov r0, v2
adr r1, open_variable
mov r2, #open_variable_len
bl findstr
/* check found */
cmp r0, #-1
beq 2f
/* output prev chars */
mov r2, r0 /* set output length */
mov r0, $0x01
mov r1, v2
sys_write
/* increment buffer */
add v2, v2, r2
add v2, v2, #open_variable_len
/* find close */
mov r0, v2
adr r1, close_variable
mov r2, #close_variable_len
bl findstr
/* check found */
cmp r0, #-1
beq 2f
mov v5, r0 /* variable name length */
/* replaces */
/* replace title */
mov r0, v2
adr r1, variable_name_blogtitle
mov r2, v5
bl strncmp
cmp r0, $0x00
bleq variable_blogtitle
beq 3f
/* replace home */
mov r0, v2
adr r1, variable_name_home
mov r2, v5
bl strncmp
cmp r0, $0x00
bleq variable_home
beq 3f
/* replace path */
mov r0, v2
adr r1, variable_name_path
mov r2, v5
bl strncmp
cmp r0, $0x00
bleq variable_path
beq 3f
/* replace title */
mov r0, v2
adr r1, variable_name_title
mov r2, v5
bl strncmp
cmp r0, $0x00
bleq variable_title
beq 3f
/* replace body */
mov r0, v2
adr r1, variable_name_body
mov r2, v5
bl strncmp
cmp r0, $0x00
bleq variable_body
beq 3f
/* replace time */
mov r0, v2
adr r1, variable_name_time
mov r2, v5
bl strncmp
cmp r0, $0x00
bleq variable_time
beq 3f
/* replace environ */
mov r0, v2
adr r1, variable_name_environ
mov r2, v5
bl strncmp
cmp r0, $0x00
bleq variable_environ
beq 3f
3:
/* increment buffer */
add v2, v2, v5
add v2, v2, #close_variable_len
ldrb r0, [v2]
cmp r0, $0x00
bne 1b
2:
/* output rest */
ldr r2, =buffer
sub r2, v2, r2
sub r2, v3, r2
mov r0, $0x01
mov r1, v2
sys_write
/* close() */
mov r0, v1
sys_close
ldmfd sp!, {r0-r3, v1-v5, pc}
open_variable:
.ascii "#{"
open_variable_len = . - open_variable
.align 2
close_variable:
.ascii "}"
close_variable_len = . - close_variable
.align 2
variable_name_blogtitle:
.asciz "blogtitle"
.align 2
variable_name_home:
.asciz "home"
.align 2
variable_name_title:
.asciz "title"
.align 2
variable_name_body:
.asciz "body"
.align 2
variable_name_path:
.asciz "path"
.align 2
variable_name_time:
.asciz "time"
.align 2
variable_name_environ:
.asciz "environ"
.align 2
variable_blogtitle:
stmfd sp!, {r0-r3, lr}
mov r0, $0x01
ldr r1, =var_title
mov r2, #var_title_len
sys_write
ldmfd sp!, {r0-r3, pc}
variable_home:
stmfd sp!, {r0-r3, lr}
mov r0, $0x01
ldr r1, =var_home
mov r2, #var_home_len
sys_write
ldmfd sp!, {r0-r3, pc}
variable_path:
stmfd sp!, {r0-r3, v1-v5, lr}
ldr r0, =current_entry
ldr r0, [r0]
add r1, r0, #entry_path
bl strlen
mov r2, r0
mov r0, $0x01
sys_write
ldmfd sp!, {r0-r3, v1-v5, pc}
variable_title:
stmfd sp!, {r0-r3, v1-v5, lr}
ldr r0, =current_entry
ldr r0, [r0]
add r0, r0, #entry_title
ldr r0, [r0]
mov r1, r0
bl strlen
mov r2, r0
mov r0, $0x01
sys_write
ldmfd sp!, {r0-r3, v1-v5, pc}
variable_body:
stmfd sp!, {r0-r3, v1-v5, lr}
ldr r0, =current_entry
ldr r0, [r0]
add r0, r0, #entry_body
ldr r0, [r0]
mov r1, r0
bl strlen
mov r2, r0
mov r0, $0x01
sys_write
ldmfd sp!, {r0-r3, v1-v5, pc}
variable_time:
stmfd sp!, {r0-r3, v1-v5, lr}
ldr r0, =current_entry
ldr r0, [r0]
add r0, r0, #entry_mtime
ldr r0, [r0]
ldr r1, =buffer
bl base10
mov r2, r0
mov r0, $0x01
ldr r1, =buffer
sys_write
ldmfd sp!, {r0-r3, v1-v5, pc}
variable_environ:
stmfd sp!, {r0-r3, v1-v5, lr}
ldr r0, =environ
ldr r0, [r0]
ldr r1, =buffer
bl base16
mov r2, r0
mov r0, $0x01
ldr r1, =buffer
sys_write
ldmfd sp!, {r0-r3, v1-v5, pc}
.section .bss
.align 2
environ: .word 0
buffer: .skip 4096
dentry_buffer:
.skip 4096
dentry_buffer_len = . - dentry_buffer
stat_buffer: /* /usr/include/arm-linux-gnueabihf/asm/stat.h */
st_dev: .skip 4
st_ino: .skip 4
st_mode: .skip 2
st_nlink: .skip 2
st_uid: .skip 2
st_gid: .skip 2
st_rdev: .skip 4
st_size: .skip 4
st_blksize: .skip 4
st_blocks: .skip 4
st_atime: .skip 4
st_atime_nsec: .skip 4
st_mtime: .skip 4
st_mtime_nsec: .skip 4
st_ctime: .skip 4
st_ctime_nsec: .skip 4
.skip 4
.skip 4
.align 2
stat_buffer_len = . - stat_buffer
entry_buffer: /* not used: just calculate offsets */
entry_buffer_path: .skip 256
entry_buffer_mtime: .skip 4
entry_buffer_title: .skip 4
entry_buffer_body: .skip 4
.align 2
entry_buffer_len = . - entry_buffer
entry_path = entry_buffer_path - entry_buffer
entry_mtime = entry_buffer_mtime - entry_buffer
entry_title = entry_buffer_title - entry_buffer
entry_body = entry_buffer_body - entry_buffer
entries_count: .word 0
current_entry: .word 0 エントリポイント、スタックポインタから環境変数のアドレスを計算して初期化する処理だけして main を呼ぶ
全体の流れが書いてあるサブルーチン
設定したディレクトリ以下のファイルを列挙してコールバックを呼ぶサブルーチンになっている。getdents してるだけ
dentries から呼ばれる。ファイル名をうけとって、. から始まるファイルを無視しつつ read_entry サブルーチンを呼ぶ。
構造体を構築してもろもろ書きこむ。
更新日時は stat した結果をとって書きこんでいるだけ
タイトル文字列・本文文字列はちょっとめんどうくさい。stat した結果でファイルサイズはわかっているので、必要な分 mmap して確保して、sys_read で全部読みこんでいる。
blosxom は1行目をタイトルとして扱うという仕様になっているけど、最初の \n を \0 に変えるだけで null ターミネートの文字列にわけられ、あとはコピーする必要がないので、そのままアドレスを計算して構造体に入れている。元のファイルは書き換えたくないので直接マッピングはしてない。
単に #{varname} みたいな形式を置換している。
依存なしで書いているので、基本的なサブルーチンも自分で書く必要があり、かなり面倒だった。
ほかに書いたもの
arm で動いてて外部公開できるサーバがないのでない。VPS で qemu で立ちあげればできるけどどこまでやることでもない。
単に1つになるだけ
低レベルのコードを書く意義は、低レベルのデバッグ方法に慣れることができる点だと思う。コードリーディングするだけではデバッグ能力はつかない。
http://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/tree/include/linux/syscalls.h?id=HEAD
http://strace.git.sourceforge.net/git/gitweb.cgi?p=strace/strace;a=blob;f=linux/arm/syscallent.h;h=132b22ad8aea66c434983e99426c8f6eaed5d114;hb=HEAD
http://linuxjm.sourceforge.jp/html/LDP_man-pages/man2/readdir.2.html
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
asm で動的にメモリ取得をしたいと思っても、malloc は libc の関数であるので、libc 依存しないなら自分で書かねばらない。
ということで、動的なメモリ確保を書いてみる。malloc を書く、というと荷が重すぎるので、単にプロセスが確保するメモリを動的に増やしていく、という大変基礎的な部分だけをやってみる。
まず brk システムコールを試す。brk は program break の意味らしい。program break とはプログラムの data セクションの最後のことで、brk システムコールはこの data セクションの最後の位置を変更するというシステムコールになっている。これにより、プロセスにメモリを割りあてたり、OS に返したりできる。いわゆるヒープ領域というやつ。
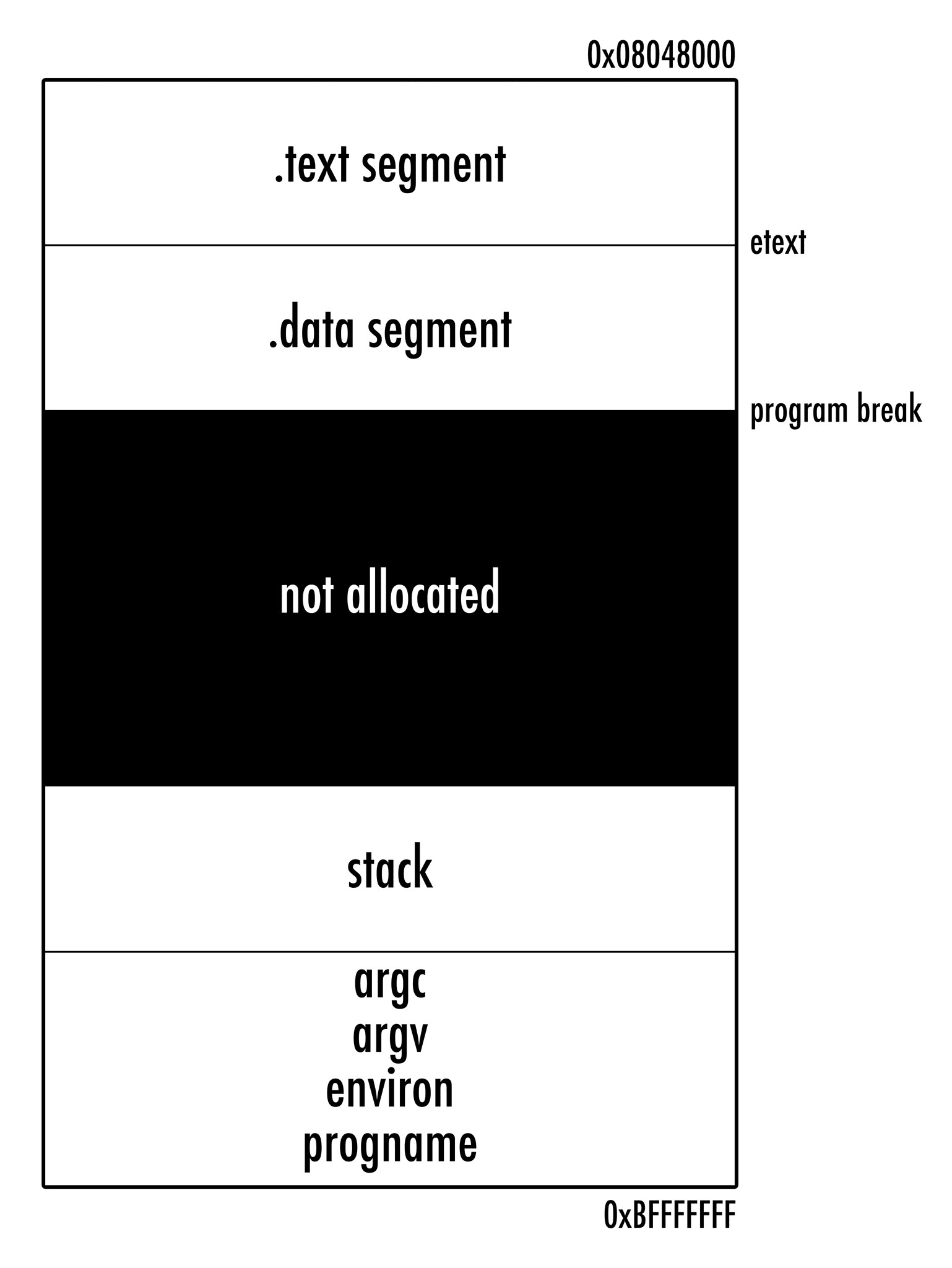
brk システムコールの引数は変更後の program break のアドレスになっている。つまり、初期値をどこかから持ってきて、自分で必要なサイズ分インクリメントして渡さなければならない。
libc レベルでは sbrk という関数も提供されていて、こちらの引数は単に increment (または decrement) する数だけを指定する。要は sbrk 内でアドレス計算をやってくれている。malloc では内部的には直接 brk を使わず sbrk を使ってメモリの取得開放を行っている。
最初この初期値は ld script で定義されている _end (bss セクションの最後を示す) でいいのかなと思い、
brk: .word _end
としてリンク時解決にしてみたけど、gdb でステップ実行しながら brk の返り値を確かめてみると、実際の program break と _end は違うことがわかった。
どこからもってくればいいのかと思ったけど、brk システムコールを 0 で呼んで、現在の brk アドレスを取得すればいいようだ (引数が不正だったり、メモリがない場合 brk は単に現在の break アドレスを返す)。ほんとかと思ったので libc のコードを読んでみたが、libc の sbrk 実装もそのようになっていたので由緒正しい。
機能的には sbrk 相当のものなので sbrk という名前にしてある。r0 に欲しいサイズを入れて bl sbrk すると、要求したバイト数確保して、先頭アドレスを返す。
.macro sys_brk
mov r7, $0x2d
svc $0x00 /* supervisor call */
.endm
sbrk: /* uint size -> void* */
push {lr}
ldr r3, =brk /* r3 = prev_brk */
ldr r1, [r3]
cmp r1, $0x00 /* if prev_brk == 0 */
bleq sbrk_init
add r0, r0, r1
sys_brk
cmp r0, r1
blt sbrk_nomem /* curr_brk == prev_brk */
str r0, [r3] /* update heap_start */
mov r0, r1
pop {pc}
sbrk_init:
push {r0}
mov r0, $0x00
sys_brk
mov r1, r0
pop {r0}
mov pc, lr
sbrk_nomem:
mov r0, $0x00
pop {pc}
.section .data
brk: .word 0 プロセスに動的にメモリを割り当てる方法としては mmap を使う方法もある。mmap の匿名マッピングは単に指定したサイズの連続した領域を確保する。ある程度大きいメモリを確保する場合はこちらのほうが管理が楽みたい。glibc の malloc は 128KB 以上一気に確保しようとすると mmap を使うらしい。
mmap のデメリットはページサイズ単位でしか割当られないことで、1KB だけ欲しい場合でも4KB 程度は割当される。以下の例では 8byte だけリクエストしているが 4096バイトまでは書きこめ、4097バイト目に書こうとすると Segmentation fault になる。
mmap の返り値もエラーの場合は負の数が返るのだけれど、最上位ビットが立っていても有効なメモリアドレスという場合もあるので、単に負かどうかでは判定できない。なんかよくわからないけど、-4096よりも大きい場合だけエラーとして扱いのがセオリーっぽい?
PROT_NONE = 0x00
PROT_READ = 0x01
PROT_WRITE = 0x02
PROT_EXEC = 0x04
MAP_ANONYMOUS = 0x20
MAP_PRIVATE = 0x02
.macro sys_mmap
mov r7, $0xc0 /* sys_mmap_pgoff */
svc $0x00 /* supervisor call */
.endm
.macro sys_munmap
mov r7, $0x5b
svc $0x00 /* supervisor call */
.endm
main:
/* mmap */
mov r0, #0 /* start */
mov r1, #8 /* length */
mov r2, #PROT_READ /* prot */
orr r2, r2, #PROT_WRITE
mov r3, #MAP_ANONYMOUS
orr r3, r3, #MAP_PRIVATE /* flags */
mov r4, #-1 /* fd */
mov r5, #0 /* page offset */
sys_mmap
cmn r0, #4096 /* if (r0 > -4096) */
rsbhs r0, r0, #0
blhs error
mov v1, r0
/* write 4096 bytes (SEGV on 4097) */
mov r2, r0
ldr r3, =4096
1:
mov r0, $0x2e
strb r0, [r2], $0x01
sub r3, r3, #1
cmp r3, #0
bne 1b
mov r0, $0x01
mov r1, v1
mov r2, #4096
sys_write
mov r0, v1 /* start */
mov r1, #8 /* length */
sys_munmap
mov r0, $0x00 /* set exit status to 0 */
sys_exit
error:
cmp r0, $0x00
moveq r0, $0x01
sys_exit malloc はどっちも使っているようだけど、いまいち brk を使うメリットがわからない。
よくわからなかった。
glibc 以外の malloc 実装を軽く調べた感じだと、OpenBSD は mmap しか使わず、jemalloc もオプションで指定しない限り mmap だけを使うようだった。
![]()
![]()
![]()
単に実行したディレクトリのファイル名を表示するだけのプログラムを asm で書いてみる。
普段全くディレクトリエントリの構造を意識しないけど、システムコールを直接呼ぼうと思うと意識せざるを得ない。
使うシステムコールは以下の通り
libc レベルだと opendir/closedir というふうにディレクトリ対象の open 操作は分かれているので、システムコールもそうなのかと思っていたけど、そうではなく普通の open/close で統一されている。ディレクトリ内容を読むには readdir というシステムコールもあるが、getdents が現代版らしいので、最初からこちらを使う。
open/close はともかく、getdents の挙動を理解するのに苦労した。
struct linux_dirent {
unsigned long d_ino; /* Inode number */
unsigned long d_off; /* Offset to next linux_dirent */
unsigned short d_reclen; /* Length of this linux_dirent */
char d_name[]; /* Filename (null-terminated) */
/* length is actually (d_reclen - 2 -
offsetof(struct linux_dirent, d_name)) */
/*
char pad; // Zero padding byte
char d_type; // File type (only since Linux
// 2.6.4); offset is (d_reclen - 1)
*/
} 以上のような構造体を渡したバッファに書きこんでくれるのだけれど、なんで構造体の後ろのほうコメントアウトになってるの?って感じ。よく定義を読んだら d_name[] は文字列へのポインタではなく文字列そのものなので、ここは可変長になっていて、コメントアウトされている分は d_reclen から実際の位置を計算する必要があることがわかる。また、このシステムコールはバッファが許す限りこのエントリを連続で書いてくるので、d_reclen をポインタに足しながら全部読み出す必要がある。
挙動さえ理解できれば難しくないので、とりあえず C レベルで1回書いたほうが早かったかもしれない。
ソートとかしていないので、表示される順番は ls -1f したときと同じになる。
libc レベルだと errno というグローバル変数にエラー番号が入るが、システムコールを直で呼ぶ場合、r0 にエラー番号の符号を反転させた値が返ってくる。
つまり、libc はシステムコールから負の値が返ってくると、符号を反転して errno にセットして、C レベルの関数では -1 を返すという挙動をするみたい。
/*#!as --gstabs+ -o ls.o ls.s && ld -o ls -e _start ls.o && objdump -d -j .text -j .data ls && ./ls
*/
.global _start
.macro sys_exit
mov r7, $0x01 /* set system call number to 1 (exit) */
svc $0x00 /* supervisor call */
.endm
O_RDONLY = 0x0000
.macro sys_open
mov r7, $0x05
svc $0x00 /* supervisor call */
.endm
.macro sys_write
mov r7, $0x04
svc $0x00 /* supervisor call */
.endm
.macro sys_close
mov r7, $0x06
svc $0x00 /* supervisor call */
.endm
.macro sys_getdents
mov r7, $0x8d
svc $0x00 /* supervisor call */
.endm
.section .text
_start:
bl main
/* not reached */
mov r0, $0xff
sys_exit
main:
/* open */
ldr r0, =current_dir
mov r1, #O_RDONLY
sys_open
cmp r0, $0x00
rsble r0, r0, #0
blle error
mov v1, r0
1:
/* getdents */
mov r0, v1
ldr r1, =dentry_buffer
mov r2, #dentry_buffer_len
sys_getdents
cmp r0, $0x00
beq 2f
mov v2, r0 /* read bytes */
rsblt r0, r0, #0
bllt error
ldr v3, =dentry_buffer
3:
ldrh v5, [v3, #8] /* linux_dirent d_reclen */
mov r0, $0x01
add r1, v3, #10
sub r2, v5, #12
sys_write
mov r0, $0x0a
push {r0}
mov r0, $0x01
mov r1, sp
mov r2, #1
sys_write
pop {r0}
sub v2, v2, v5 /* len -= d_reclen */
add v3, v3, v5 /* buffer += d_reclen */
cmp v2, $0x00
bne 3b
b 1b
2:
/* close */
mov r0, v1
sys_close
mov r0, $0x00 /* set exit status to 0 */
sys_exit
current_dir:
.asciz "."
.align 2
error:
cmp r0, $0x00
moveq r0, $0x01
sys_exit
.section .bss
.align 2
buffer: .skip 4096
dentry_buffer:
.skip 4096
dentry_buffer_len = . - dentry_buffer
![]()
![]()
![]()
asm だけで getenv をしてみようとしたらかなり大変で、本当はもっと先の目標があったけど、遥か遠いので、とりあえず getenv しただけで一旦まとめる。
そもそも、Linux のプロセスイメージをちゃんと知っていないといけない。環境変数ってどこからくるんだ? というところからして、全く知らなかった。getenv とかシステムコールになってて呼んだら出てくるのかと思っていた。
このページがわかりやすかった。
結局以下のようにすれば r0, r1, r2 それぞれに argc argv environ が入るようになる。sp にスタック位置が起動時から入っているので、そこを基準にオフセットを計算するみたい。スタックはアドレスが小さくなるほうに伸びるけど、それの逆方向に argc やら何やらが入っている。
_start:
mov lr, #0
/* r0 = argc */
ldr r0, [sp]
/* r1 = argv */
add r1, sp, $0x04
/* r2 = argc * 4 (skip argv) */
mov r3, $0x04
mul r2, r0, r3
/* r2 += 4 (skip null word) */
add r2, r2, $0x04
/* r2 += offset (ok this is environ) */
add r2, r1 gcc で普通にコンパイルすると libc がこのへんうまいことやってくれているんだなあと思って libc の大事さを感じる。
そして getenv を実装するために最低でも strncmp 的なものが必要だし、strlen もないと出力するとき困る。
environ は文字列の配列なので、レジスタに今何がロードされているのか意識するのがこんがらがってつらい。LL とか触っていると、文字列の配列は文字列のリストにしか見えないので、しばしば実際は文字列のアドレスの配列になっていることを忘れてしまう。
ARM の場合さらに、遠いアドレスにあるメモリを直接参照できないので、さらに1段参照が増えていたりしてややこしい。オペランドの = を使うとそのへんあまり意識せずにすむようになって便利 (遠い場合は自動的に近くに値プールをつくってくれるらしい)
ちょっと複雑になってくるともはやデバッガのステップ実行なしではつらい。gdb が使えるのでつかう。as に --gstabs+ オプションをつけてコンパイルしたバイナリを gdb sketch とかで普通に起動してやればよい。レジスタの値は info registers で見ることができる。
$ as --gstabs+ -o sketch.o sketch.s && ld -o sketch -e _start sketch.o $ gdb sketch (gdb) b main Breakpoint 1 at 0x80ac: file sketch.s, line 46. (gdb) r Starting program: /home/pi/sketch/sketch Breakpoint 1, main () at sketch.s:46 46 bl getenv (gdb) info registers r0 0x80c8 32968 r1 0xbefff734 3204446004 r2 0xbefff73c 3204446012 r3 0x101cc 65996 r4 0x0 0 r5 0x0 0 r6 0x0 0 r7 0x0 0 r8 0x0 0 r9 0x0 0 r10 0x0 0 r11 0x0 0 r12 0x0 0 sp 0xbefff730 0xbefff730 lr 0x809c 32924 pc 0x80ac 0x80ac <main+4> cpsr 0x10 16
/*#!as --gstabs+ -o sketch.o sketch.s && ld -o sketch -e _start sketch.o && objdump -d -j .text -j .data sketch && ./sketch
*/
.global _start
.macro sys_exit
mov r7, $0x01 /* set system call number to 1 (exit) */
svc $0x00 /* supervisor call */
.endm
.macro sys_write
mov r7, $0x04
svc $0x00 /* supervisor call */
.endm
_start:
mov lr, #0
/* r0 = argc */
ldr r0, [sp]
/* r1 = argv */
add r1, sp, $0x04
/* r2 = argc * 4 (skip argv) */
mov r3, $0x04
mul r2, r0, r3
/* r2 += 4 (skip null word) */
add r2, r2, $0x04
/* r2 += offset (ok this is environ) */
add r2, r1
/* save char** environ to global variable */
ldr r3, =environ
str r2, [r3]
/* r0 = argc, r1 = argv, r2 = environ */
bl main
/* not reached */
mov r0, $0xff
sys_exit
main:
/* getenv("USER") */
adr r0, USER
bl getenv
/* if "USER" is not in ENV */
cmp r0, $0x00
bleq error
bl puts
mov r0, $0x00 /* set exit status to 0 */
sys_exit
USER:
.asciz "USER"
.align 2
error:
mov r0, $0x01
sys_exit
strncmp: /* char* s1, char* s2, size_t len -> 1|0 */
stmfd sp!, {v1-v5, lr} /* save variable resistors and returning address */
mov r3, $0x00 /* result */
1: cmp r2, $0x00
beq 2f /* if (r2 == 0) goto 2 */
sub r2, r2, $0x01 /* len-- */
ldrb r4, [r0], $0x01 /* r4 = *s1++ */
ldrb r5, [r1], $0x01 /* r5 = *s2++ */
cmp r4, r5
beq 1b /* if (r4 == r5) goto 1 */
add r3, $0x01 /* r3++ (this function always returns 1 when the comparing fails) */
2:
mov r0, r3
ldmfd sp!, {v1-v5, pc} /* restore variable resistors and set pc to returning address */
strlen: /* char* str* -> uint */
mov r1, $0x00 /* r1 = result */
/* r2 = *str++ (ldrb = load byte, and r0 increment after) */
1: ldrb r2, [r0], $0x01
cmp r2, $0x00
addne r1, r1, $0x01 /* if (r2 != 0) r1++ */
bne 1b /* if (r2 != 0) goto 1; */
mov r0, r1
mov pc, lr
getenv: /* char* name -> char* */
stmfd sp!, {v1-v5, lr}
/* v1 = name */
mov v1, r0
/* v2 = strlen(r0) */
bl strlen
mov v2, r0
/* v3 = environ char** */
ldr v3, =environ
ldr v3, [v3]
1: /* if (strncmp(name, *environ, len) == 0) { */
mov r0, v1
ldr r1, [v3]
/* *environ != NULL */
cmp r1, $0x00
beq 2f
mov r2, v2
bl strncmp
cmp r0, $0x00
/* if (*environ)[len] == '=') { */
ldreq r0, [v3]
ldreqb r0, [r0, v2]
cmpeq r0, #'=
beq 3f
/* } */
/* environ++ */
add v3, $0x04
b 1b
2:
/* not found return NULL */
mov r0, $0x00
ldmfd sp!, {v1-v5, pc}
3: /* found and return address */
ldreq r0, [v3]
add r0, r0, v2
add r0, r0, $0x01 /* skip '=' */
ldmfd sp!, {v1-v5, pc}
puts:
stmfd sp!, {v1-v5, lr}
mov v1, r0
bl strlen
mov r2, r0
mov r1, v1
mov r0, $0x01
sys_write
mov r0, $0x01
adr r1, linefeed
mov r2, $0x01
sys_write
ldmfd sp!, {v1-v5, pc}
linefeed:
.byte '\n
.align 2
.section .bss
.align 2
environ: .word 0
![]()
![]()
![]()
いい時代なので、実機がなくても qemu で環境をつくることができる。
brew install qemu
で入る
ここにある debian のイメージを例にすると、適当に必要なファイルをダウンロードするだけ
qemu-system-arm -M versatilepb -kernel vmlinuz-3.2.0-4-versatile -initrd initrd.img-3.2.0-4-versatile -hda debian_wheezy_armel_standard.qcow2 -append "root=/dev/sda1" -m 256 -redir tcp:2200::22
で起動させる。中から外のネットワークには出られるが中に繋ぐ方法がないっぽい?ので -redir tcp:2200::22 でポートフォワード的なことをしている。
ssh -p2200 root@localhost password: root
Debian だと開発ツールがデフォルトで入っていないのがうざいけど、しかたない
ref.
![]()
![]()
![]()
ngResource は単にAPIのラッパーという感じではなくて、JS でサーバ側のモデルとうまく同期するように作られている。
最も簡単な例だと以下のように使うが、Entry.get は XHR が完了する前に、とりあえず空のオブジェクトが返るようになっており、XHR の完了とともに破壊的に書きかえられる。これにより、entry の変更がすぐ全体に伝わるようになっている。
var Entry = $resource('/entry/:id');
$scope.entry = Entry.get({ id : 0 }); デフォルトで定義されている query/get/save/delete だけを見ると単に REST API のラッパーのように見えるが、独自のメソッドを追加するとより理解しやすいコードを書ける。
以下のコードは、デフォルトで下書き状態で生成される Entry オブジェクトを、後から publish 状態に変えるような挙動を想定している。単に $save() とかを使ってもいいが、専用のメソッドを生やすことでやりたいことを明確にできる。
var Entry = $resource('/entry/:id', {}, {
'publish': { method: 'PUT', params : { publish : 1 } }
});
$scope.entry = Entry.get({ id : 0 });
....
$scope.doPublish = function () {
$scope.entry.$publish(function () {
alert('entry published!');
});
} この独自に定義したメソッドの場合も XHR が完了すると、API のレスポンスで元の entry インスタンスは破壊的に変更がかかる。すなわち $scope.entry を改めて自分で更新する必要はない。Angular の場合、オブジェクトの変更がうまいことビューに反映されるようになっているので、これだけでビューの更新までかかるコードになっている。
ngResource とサーバ側 API とうまく協調させることで、自動的にビューの更新までできるようになる。
ngResource の挙動とサーバサイドのAPIのインターフェイスをあわせる方法は前に書いた。ngResource は定義方法がいまいちわかりにくいし、挙動も若干マジカルだが、うまく使えば余計なことを気にせずにかっこよくビューまで一体したコードが書ける。
![]()
![]()
![]()





