
✖
![]()
![]()
![]()
![]()
![]()
![]()
最近の Android 端末だと RAW 撮影に対応していることがある。あまり対応アプリケーションがないのだが Lightroom Mobile を使うと DNG (Adobe が策定した RAW 画像形式) 撮影して、そのまま現像もすることができる。
DNG 撮影すれば、たとえスマフォ撮影でも後処理はしやすくなる。通常ユースでは全くいらないかもしれないが突発的に時間ができて手元にスマフォしかないみたいな場合でも救えるケースがでてくるかもしれない。
スマフォでも一昔前のコンデジぐらいの画質はあることが多いので、RAW で撮影すればそこそこ見れる写真になることが期待できる。
端末が DNG 対応しているかどうか調べられないか? と思ったら、Lightroom Mobile だとちゃんと DNG 対応しているかどうかを表示するところがあった。まぁもちろん実際の撮影設定で DNG に設定できるなら対応ということなんだけど。

DNG 対応してない場合は以下の通り

API Level 21 (5.0 Lolipop) から ImageFormat.RAW_SENSOR や DngCreator というのが入っていたらしい。
現実的には CameraDevice が RAW をサポートしているかどうかで実際に出力できるか変わりそうだが、いまいち市場での対応状況はわからない。スペックに RAW 撮影対応かどうか書いてあるのを見たことがない。
手元の ZenFone 3 だと Lightroom Mobile で DNG が生成できることは確認できた。ただ、 ZenFone 3 はそもそもカメラの性能がいまいちなのでそれほどテンションあがるわけではない。
![]()
![]()
![]()
![]()
![]()
![]()

やりたいのは 1文字だけの改行の拒否 - Hail2u のようなことの延長です。長めの見出しがブラウザによって改行されると、どうもバランスが悪くなったり可読性が微妙になることが多い。これをなんとかする。
元の高さから変わらないことというのは行数を変えないということです。これを制約にしてページ全体の高さに影響を与えないようにすることで、非同期的に行数を調整しても閲覧に支障がないようにという意図があります。
「各行のバランス」はできるだけ行ごとの幅を揃えるという意味でいっています。基本的に幅が揃うことはないので、あくまでできるだけです。また、揃わない場合には一番下の行が一番長くなるようにします。これはデザイン上、重心が下になるほうが安定して見えるからです。
また、このサイトにも適用済みです。
いわゆる形態素解析での単語単位の「わかち書き」だと分割されすぎてしまいます。基本的に文節単位で改行するのが適切ではないかと思うので、文節単位のわかち書き機みたいなのが欲しくなります。
そこで TinySegmenterMaker を使ってみました。TinySegmenter を任意の学習データから生成できる優れものです。TinySegmenter 自身は言語非依存のアルゴリズムのため、一般的な形態素解析の分割位置とは違う分割でも学習さえさせれば動いてくれそうです。
適当なコーパスを用意できなかったため、とりあえず自分で書いた日記 (これ) の過去ログを全て MeCab で解析し、副詞などを結合する処理を加えたあとにスペース区切りで出力し、TinySegmenterMaker の入力としました。学習データ的に汎用性は落ちますが、そもそも自分のサイト用なのでまぁいい気もします。
そんなに元データは多くありませんが結構時間がかかりました。
なお分割時の MeCab 辞書に mecab-ipadic-neologd も入れてます。不必要な分割が減ることを期待しています。
1行に収まっている場合は処理しません。
場合によって全く改行位置を調整できないケースも生じます。つまり各行に文字がいっぱいっぱいに詰まっている場合、調整できません。この場合も諦めてブラウザにまかせます。ただ、最後のセグメントには改行禁止ゼロスペース文字を入れることで1文字だけ残るというのは可能な限り避けます。
文字幅の計算には canvas の measureText を使っています。カーニングやリガチャなどが適切に反映されない可能性がありますが、現時点だとこれ以上良い方法がない気がします。
Webフォントを使う場合、ロードされていることを実行前に保証する必要があります。document.fonts.ready がちゃんと使えればいいんですが、Safari の挙動がおかしいので使えませんでした。
そこで以下のようにしてWebフォントのロードを判定しています。
function webfontReady (font, opts) {
if (!opts) opts = {};
return new Promise(function (resolve, reject) {
var canvas = document.createElement('canvas');
var ctx = canvas.getContext('2d');
var TEST_TEXT = "test.@01N日本語";
var TEST_SIZE = "100px";
var timeout = Date.now() + (opts.timeout || 3000);
(function me () {
ctx.font = TEST_SIZE + " '" + font + "', sans-serif";
var w1 = ctx.measureText(TEST_TEXT).width;
ctx.font = TEST_SIZE + " '" + font + "', serif";
var w2 = ctx.measureText(TEST_TEXT).width;
ctx.font = TEST_SIZE + " '" + font + "', monospace";
var w3 = ctx.measureText(TEST_TEXT).width;
console.log(w1, w2, w3);
if (w1 === w2 && w1 === w3) {
resolve();
} else {
if (Date.now() < timeout) {
setTimeout(me, 100);
} else {
reject('timeout');
}
}
})();
});
} 本当は各形態素境界ごとにスコアリングして、読みやすい順に改行を加えるみたいなことができればいいんですが、僕の技術力だとむずかしそうです。クライアント幅によるという性質上、処理はクライアントサイドでやる必要がありますが、そうすると実行ファイルサイズも問題になってきます。
そもそも学習データとして「適切な改行位置」を与えるのが難しい問題があります。Cabocha を使えばもうちょっとマシになるでしょうか?
「下のほうを長くする」という方針がいまいちだと思います。意味的に区切れるところを優先して区切るのが正しいと思われます。
なんかどうも boost_system も必要でした。以下のようにコンパイルしました。
g++ -I/usr/local/include -L/usr/local/lib -DMULTITHREAD -lboost_thread-mt -lboost_system -O3 -o train train.cpp
あと train に引数を与えないとマルチスレッドで処理されませんでした。8スレッドでやるなら -m 8 を加えます。
./extract < /tmp/corpus.txt > features.txt ./train -t 0.001 -n 10000 -m 8 features.txt model ./maker javascript < model
https://github.com/cho45/midashi-kaigyo あまり整理されてません。
ブコメ で教えてもらいましたが、Google がまさに同じことをやってました。
Google の NL APIを使っているみたいです。
文字を変形させるという発想がなかったのですが、編集系の識者のかたから長体かけつつ字送り詰めて押し込んだりします
という意見をいただきました。また、これを実現する方法として CSS transform を使えばいいのではないかという意見もいただきました。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
このエントリの情報は古いです。現行 (2018年11月) のブラウザでは canvas の色の扱いが改善され、すべて sRGB で取り扱われるようになったため、以下のようなハックはできません。(できなくなったことは喜ばしいことです。)
(黒魔術) CSS の色を sRGB にあわせるには | tech - 氾濫原 というエントリを書いてから、ふと「もしかしてユーザー環境の色域 (モニタのプロファイル) を推定することができるのではないか」と思い至ったのでやってみました。
デモ: https://lowreal.net/2017/gamutdetect/
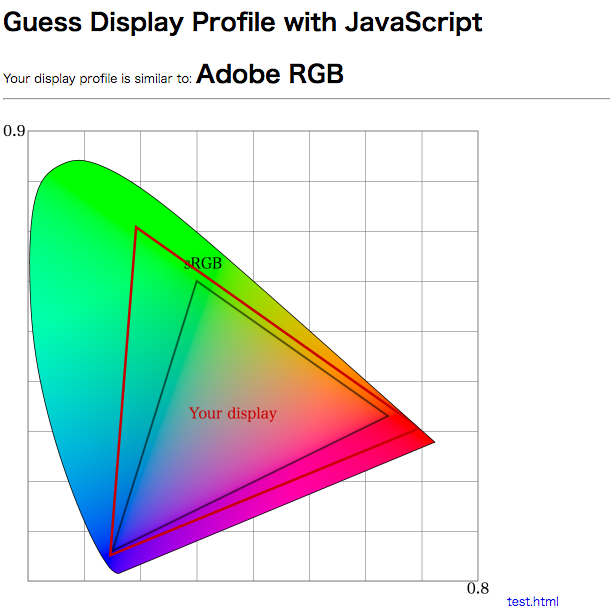
ICC Profile を埋めこんだ画像を canvas に drawImage すると、プロファイル変換されたRGB値が描かれる。getImageData 経由でピクセル値を読むことでプロファイル変換済みのRGB値が得られる。
Chrome と Firefox だけで確認しています。これらのブラウザは上記の前提があてはまるからです。基本的に不具合に近い仕様だと思うので、そのうち動かなくなりそうです。あくまでネタってことです。
Safari と IE は OS レイヤーのカラーマネジメントなのが関係しているのか、putImageData や getImageData も sRGB として扱われていそうです。
プロファイルに影響される値がとれるということは、間接的にプロファイルを推定できるはずです。具体的には sRGB プロファイルで 0,255,0 という画像データがあったとき、これは sRGB の色域で 0,255,0 という色ですが、もしモニタプロファイルが Adobe RGB など広色域であれば、取得できる値は Adobe RGB の色域のためにもっと小さい (飽和していない) 値になると予想できます。
実際にはモニタプロファイルを推定しているので「Adobe RGB の色域だ!」というのはおかしいのですが、近似として Adobe RGB / DCI P3 / sRGB の3種類の計算値の中から、近そうな色域として判定を出しています。
判定方法は sRGB で 0,255,0 (緑) の色が現在のモニタでどういう RGB 値になるかで行っています。255,0,0 (赤) と 0,0,255 (青) を判定にいれるとどうも変なので判定につかってません。もうちょっと考慮の余地がありそうです。
sRGB の 200,55,55 / 55,200,55 / 55,55,200 をレンダリングした結果を読みとり、三元一次連立方程式を3つ解いてXYZへの変換マトリクスを逆算し、あらためてRGB各頂点のXYZ値を求めるという方法でxy色図に色域をプロットするようにしてみました。中途半端な値を使っているのは飽和させないためです。
こうするとやっていることが多少わかりやすいかなという気がします。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
何かを変えるためには習慣を変えるほかないということで、とりあえず毎日1時間ぐらい歩くことをはじめてみてる。
大まかに以下の通り4通りのパターンが考えられる。
しかし通勤時間帯を避けようと思うと、2 は無理。夜歩くと帰宅時間が結構遅くなるので嫌。ということで1になる。
しかし最寄り駅付近は歩いても面白くないという致命的な問題がある。立地の事情により特定ルートを通らざるを得なく続けていると単調になってしまう。
正直いってあんまりない。便通が改善したかもしれない。晴れている日が多くて気持ちいいけど精神的に良くなったりはしてない。
![]()
![]()
![]()
Chrome, Firefox, Safari で調べたところ、
gfx.color_management.mode
によって挙動が変わる。2がデフォルトだが、2の場合は sRGB が適用されない。1の場合は sRGB が適用される。
に影響する。
現状では画像に ICC Profile をつけないようにするのがベスト。色の再現を捨ててあわせにいく感じ。
CSS も含めてあわせるのは無理 (ということにしておくと吉)
Firefox Chrome ともに起動時にディスプレイプロファイルを読みこむので、あとから変えても反映されない。また、プライマリディスプレイのプロファイルしか読みこまないので注意。
実は少し可能なことがわかったので「(黒魔術) CSS の色を sRGB にあわせるには」というのをあとで書く → 書いた https://lowreal.net/2017/02/07/4
![]()
![]()
![]()
Chrome と Firefox では CSS の色にカラーマネジメントが適用されず、sRGB の画像と色をあわせることが基本的に無理です。
で、無理なんですが無理ではなくて、実は頑張れば sRGB にあわせることができることがわかりました。
以下のような感じになっていて、書いてある通りです。Chrome と Firefox だと上3つと下3つの色が異なります。Safari だと全て sRGB 扱いされるので全部同じに見えるはずです。ただしカラーマネジメントが有効かどうかの判定を入れてないので、カラーマネジメントに対応してないシステムでも全部同じになっています。
一番下の色が JS で CSS のルールを書きかえて sRGB にしたものです。

要は使う色をあらかじめ sRGB プロファイルの PNG に描いておき、この画像のレンダリング結果を canvas に drawImage して、getPixelData を行うとディスプレイプロファイルが適用されたRGB値を取得することができるので、これを動的に CSS の色として適用すれば sRGB にできます。
sRGB の画像を canvas に描くってところがポイントです。
が、これは手動でやろうとすると面倒なので、CSSから色を抽出し、動的に sRGB PNG を作ってRGB値を変換してやるというのをやってみました。実用的かというと実用的ではないんですが、できそうですねってところです。
という手順でやります。
document.styleSheets の内容を書きかえているので、要素個別に書かれたスタイルについては対応できてません。
雑に以下のようにしました。当然完璧ではありませんが…
function scanStyleSheetColors (cb) {
for (var i = 0, stylesheet; (stylesheet = document.styleSheets[i]); i++) {
for (var j = 0, rule; (rule = stylesheet.cssRules[j]); j++) {
for (var k = 0, name; (name = rule.style[k]); k++) {
var val = rule.style.getPropertyValue(name);
if (/rgb\((\d+),\s*(\d+),\s*(\d+)\)/.test(val)) {
var r = RegExp.$1;
var g = RegExp.$2;
var b = RegExp.$2;
var ret = cb(r, g, b);
if (ret) {
var newVal = 'rgb(' + ret.join(',') + ')';
console.log(rule, name, val, '->', newVal);
rule.style.setProperty(name, newVal, rule.style.getPropertyPriority(name));
}
}
}
}
}
} // to PNG data URL with sRGB profile
function applyProfile (canvas) {
function pngChunk (type, data) {
var LEN_LENGTH = 4
var LEN_TYPE = 4;
var LEN_CRC = 4;
var buf = new ArrayBuffer(LEN_LENGTH + LEN_TYPE + data.length + LEN_CRC);
var view = new DataView(buf);
var pos = 0;
view.setUint32(0, data.length);
pos += LEN_LENGTH;
for (var i = 0, len = type.length; i < len; i++) {
view.setUint8(pos++, type.charCodeAt(i));
}
for (var i = 0, len = data.length; i < len; i++) {
view.setUint8(pos++, data.charCodeAt(i));
}
var crc = CRC32.bstr(type + data);
view.setUint32(pos, crc);
return String.fromCharCode.apply(null, new Uint8Array(buf));
}
var dataURL = canvas.toDataURL('image/png');
var matched = dataURL.match(/^data:image\/png;base64,(.+)/);
var base64 = matched[1];
var png = atob(base64);
// sRGB with Perceptual (0) rendering intent
png = png.replace(/(....IDAT)/, pngChunk("sRGB", "\x00") + "$1");
return 'data:image/png;base64,' + btoa(png);
} こんなんでできます。やってることは sRGB チャンクを追加してるだけです。PNG は sRGB に関しては ICC プロファイルを埋めこむ必要なく、13バイト追加するだけですみます。
Safari だと drawImage がうまくいかないです。ちゃんと追ってません。Safari はそもそも sRGB なのでやる必要ないです。
![]()
![]()
![]()
そういえば一ヶ月前ぐらい?から、ロードとパースに結構時間がかかっているのが嫌だなと思って HatenaStar.js を読みこむのをやめております。
簡単でポジティブなフィードバック手段がなくなったので寂しい気もしますが、しばらくこれでいこうという感じです。モダンブラウザ向けのミニマムな実装を書く気になったら復活するかもしれないけど、今のところそんな気力はない。
なんか他にもポジティブ評価しかできないフィードバック方法があればいいんですけどね。PVには色気がなく、はてブには善意がない。はてなスターはちょうどいいんだけどなあ。
![]()
![]()
![]()
もっとささやかな目標を少しずつ達成する必要があるのではないか。
例えば社会人になってから箸の持ちかたを改善したが、これは主観的に満足度が高かった。誰の得にもならなくても目標を達成できるのは良いことで、人生を良くすると感じる。
「日々の善行」を目標としてみたいが、正直いって荷が重い気がする。自然に毎日達成できるようなことではないからだ。心掛けはできても目標にはできない。善行チャンスを逃すなという心持ちではいたい。
「昨日よりも今日を良い日にする」はまぁまぁいい気がする。定量的な目標ではなく達成条件が比較的曖昧なのは良い。1週間のうち半分以上で達成できれば、全体としてプラスといえる。しかし曖昧すぎて難しい。「良い日」ってなんだろうか?
![]()
![]()
![]()
認知行動療法のうち認知療法はいまいちうさんくさい (結局性格を楽観的にしろとしか言っていないように感じるから) が、マインドフルネスはメタ認知しろという話なので比較的納得感がある。でも独りでマインドフルネス実践するのは難しいように感じる。
瞑想ってのが難しいポイントで、やりなれていなければできないし、やってみても何が正しい瞑想なのかわからない。「これであってるのか?」という疑問をいだきつつやっても不愉快になってしまうしやる気が起きない。
思考は思考で上書きするほうが簡単なので、自動思考が起きたとき他の思考を強制的に挟みこむように解決できないんだろうか。メタ認知は今起きていることの受容と洞察がキモだと思うけど、瞑想を通すと難しい。
![]()
![]()
![]()
![]()
![]()
![]()
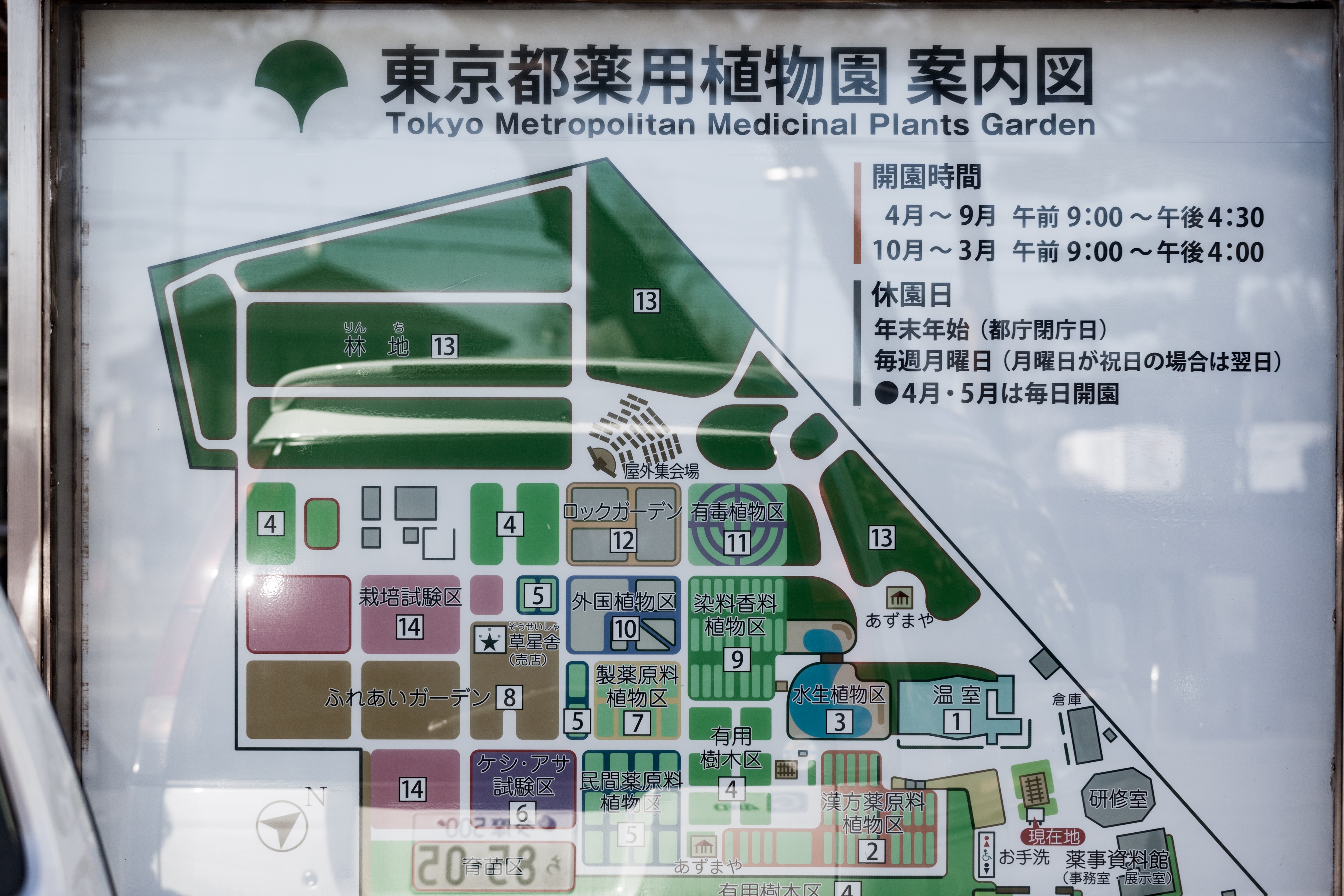
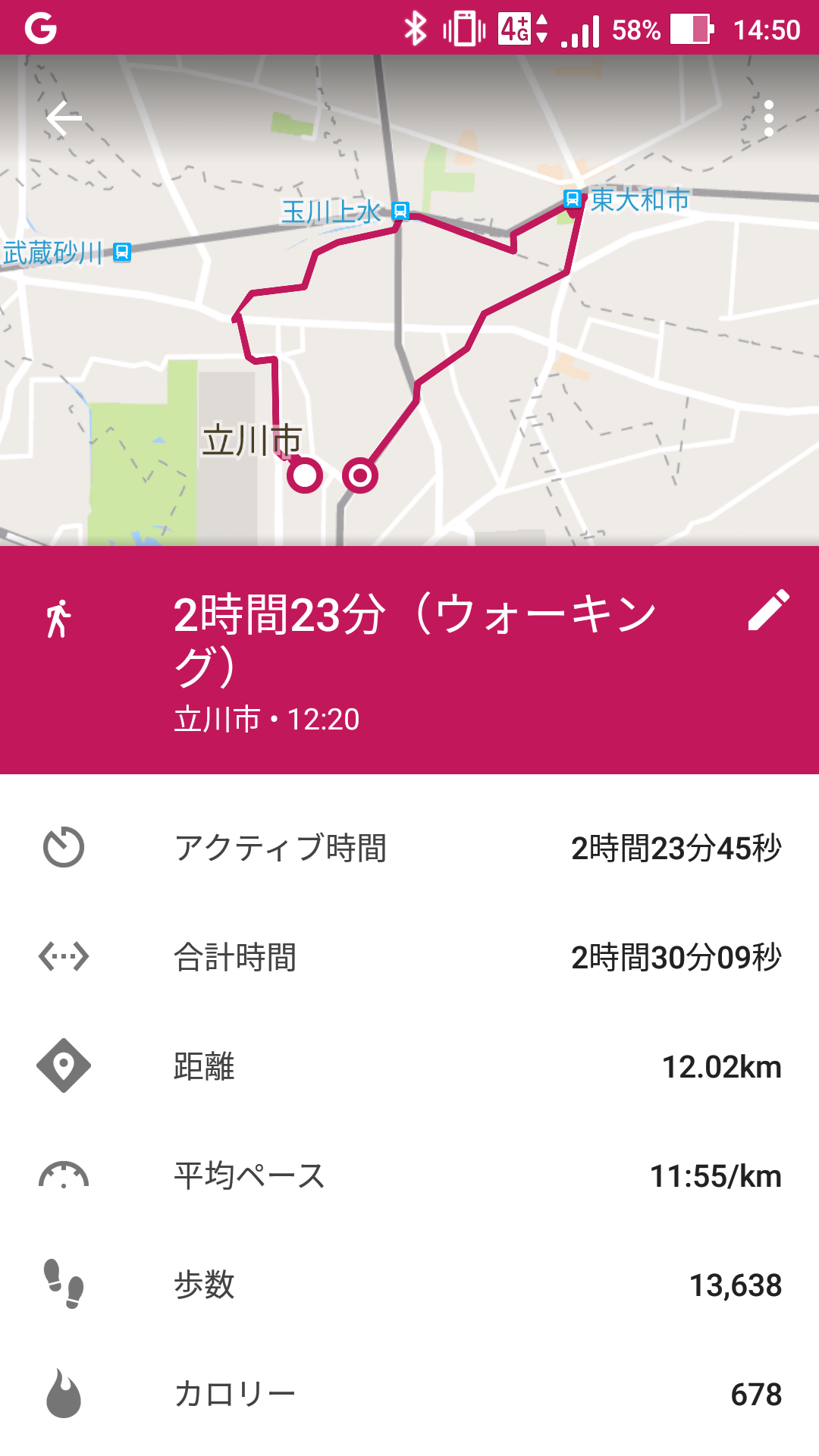
立川 → 阿豆佐味天神社 → 東京都薬用植物園。
途中で南極・北極科学館というのを見かけたのでふらっと入ったけど面白かった。

機械遺産の極点到達雪上車が展示されているんだけど、なんと驚くことに中に入れる。4人分の寝るスペースが一応ある車なんだけど、とても狭い。機材がちょっと残っていてコリンズKWM-2Aという真空管無線機が置いてあった。



阿豆佐味天神社はそれほど面白くなかったので特筆するようなことはなし。

東京都薬用植物園は季節も季節なのであまり見所はなかった。初夏あたりが一番良いのかな? でも混んでなかったのでよかった。




![]()
![]()
![]()







