CW の信号帯域とコンスタレーション
CW の最小単位である短点の長さ t は以下で求められる。w は符号速度、単位 wpm (通常は 10〜40wpm) 。
5 (トトトトト 短点5つ)や訂正信号 <HH> (トトトトトトトト 短点8つ) を送信しているときに最大の帯域幅になる。短点の長さ t の on/off の繰り返しであるので、波長 2t の矩形波となる。24wpm では t = 50ms なので波長100ms、すなわち 10Hz の矩形波。
これを搬送波に乗せると (AM変調なので) 両側波帯に帯域が広がるため最低でも 20Hz の帯域幅になる。矩波形なので奇数次数の高調波も発生し、5倍まで考慮するだけで100Hzになる。
なお10wpm で 4Hz、50wpm で 21Hz の矩形波。
コンスタレーション(信号空間ダイヤグラム)
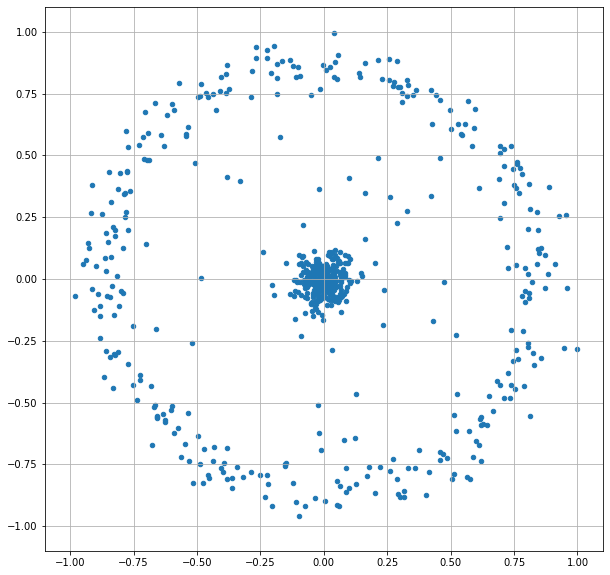
普通CWのコンスタレーションを気にすることはないと思うが、一応確認しておくと、BPSK などと比べるときに想像しやすい (なぜ BPSK が CW/OOK と比べて 3dB 有利かとか)
上の図のように中央部 (off) と周辺部 (on)にわかれる。
これがたとえば BPSK の場合は、中央ではなく、左端と右端になる。すなわち信号空間的には距離はCWの2倍になる。2倍=3dBよくなるということはこういうこと
関連エントリー
- スペアナでスプリアス測定してみる3 KX3 FMの測定 測定方法について 以下を根拠に測定する 特性試験の試験方法 別表第一 スプリアス発射又は不要発射の強度の測定方法 一 スプリアス領域における...
- スペアナでスプリアス測定してみる (KX3 CW) 手元にある Elecraft KX3 の測定をしてみる。 (ちなみに当局の KX3 は「平成17年12月以降にアマチュア局の保証を受けて免許...
- モールスデコーダの続き RNN モールスデコーダの試作 | tech - 氾濫原 波形ではなくSFFTの結果を認識させる モールスで必要なのはキャリア周波数の周辺帯...
- スペアナでスプリアス測定してみる2 KX3 SSB の測定 スペアナでスプリアス測定してみる (KX3 CW) | tech - 氾濫原 というのを書いた。SSB でさらに測定してみる。途中で「帯域外...
- RNN モールスデコーダの試作 メモ書き。試行錯誤の途中でコードが消えさったりしていてよくないので、やったことだけ書いておく モールスの特徴 信号周波数が固定されており正弦...
.png)
.png)
.png)
.png)
![KURE [ 呉工業 ] シリコンスプレ- (420ml) [ For Mechanical Maintenance ] 潤滑・離系剤 [ KURE ] [ 品番 ] 1046 - KURE(呉工業)](https://m.media-amazon.com/images/I/41O9TBUrjZL._SL500_.jpg)
