✖










(batch_size, timesteps, features) が入力になる。batch_size はこのバッチ(学習・予測の1単位)中のサンプル数 (予測するデータの数) で stateless なら None (可変長) にできる、timesteps は与える時系列の長さ、features は特徴量。
features は 例えば1次元の波形データであれば 1 になる。3つのセンサーデータがある場合なら3になる。
timesteps は固定長にもできるし、可変長にもできる。可変長の場合は None を指定する。可変長といっても、単一バッチ中の timesteps の数は揃える必要がある。
timesteps を変えても RNN レイヤーのパラメータ数は変化しない。パラメータ数は features のサイズとRNNのユニット数に依存する。
stateless RNN の場合、RNN の内部状態はバッチごとにリセットされる。
1つのサンプルの出力は、与えた timesteps の数からしか影響されない。また、バッチ内の各サンプルは独立している。
例えば以下のような (3, 5, 1) なバッチを与えた場合、stateless RNN は、1つ目のサンプルに関しては [1, 2, 3, 4, 5] という情報をつかって 6 を予測するようになる。2つ目のサンプルも同様で、1つ目のサンプルとは内部状態が独立して (学習した重みはもちろん共有しているが) [ 2, 3, 4, 5, 6] から 7 を予測する。
# batch_input_shape = (3, 5, 1) 1 2 3 4 5 -> 6 2 3 4 5 6 -> 7 3 4 5 6 7 -> 8
stateful の場合は手動でリセットしない限り、バッチの最後の内部状態はリセットされない。
極端な例だと1回のバッチで timesteps が1というこもありうる。混乱しやすいのでサンプル数1で例を示してみる。
以下のように3回のバッチにわけてstateful RNNへ入力を与える。すべてサンプル数 (batch_size) は固定。timesteps の数は任意。stateless ではリセットしていたバッチ最後の各サンプルの最後の状態を保持しているので、batch #2 では、1つのtimestepsを与えているだけだが、それまでの timesteps である 1 2 3 4 5 も考慮された状態で予測される。
# batch #1 shape = (1, 5, 1) 1 2 3 4 5 -> 6 # batch #2 shape = (1, 1, 1) 6 -> 7 # batch #3 shape = (1, 2, 1) 7, 8-> 9
statelessで学習させて stateful に予測させるということもできる。これらの違いは内部状態をバッチ間で共有するかどうかだけなので、十分に長い系列で学習しているならあまり問題はない。この場合は、学習時に与えたステップ数しか考慮されていないが、連続で推論して新しい系列を得たいときはstateless より早く予測できる (途中の状態を保持したままなため再度過去の時系列を与える必要がない)。
stateful で学習させるのは結構めんどうくさいので、stateless で十分に長い時系列を与えて学習させて、リアルタイム予測などで実際に使うときは stateful にするというやりかたはありかもしれない。
意味がある予測ではないけど、試しにやってみた。
space = np.linspace(0, 1, 1000)
data = signal.square(2 * np.pi * 50 * space) * signal.square(2 * np.pi * 30 * space) / 2 + 0.5 こういう一時データをRNN(GRU)で学習させてみる。急激な値の変化があると学習結果が面白いことが多いので矩形波にしてる。

def create_model(batch_size=None, timesteps=None, stateful=False):
inputs = Input(batch_shape=(batch_size, None, 1))
x = inputs
x = GRU(32, stateful=stateful, return_sequences=False)(x)
x = Dense(1, activation='sigmoid')(x)
outputs = x
model = Model(inputs, outputs)
model.compile(optimizer=keras.optimizers.Adam(lr=0.01), loss='binary_crossentropy', metrics=['accuracy'])
return model
model = create_model(timesteps = 100)
model.summary()
gen = keras.preprocessing.sequence.TimeseriesGenerator(data[:-10].reshape( (len(data)-10), 1 ), data[10:], length=100)
model.fit_generator(gen, epochs=30, validation_data=gen, shuffle=False) 過去の状態から10ステップ先を1つ予測するという問題設定にした (特に問題に意味はない)
stateless でも stateful でも同じモデルを作れるようにして、まず stateless で学習させる。ここでは過去の系列は100ステップで学習させている。特に意味がある学習ではないので validation に同じ系列を指定してる。
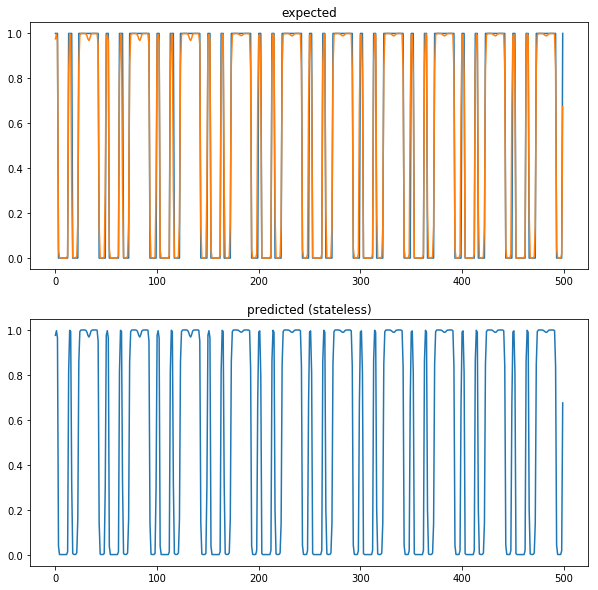
tstart = time.time()
predict_len = 500
start = 207
result = []
for n in range(predict_len):
predicted = model.predict( data[start+n-100:start+n].reshape( (1, 100, 1) ) )
result.append(predicted[0])
result = np.array( result)
elapsed = time.time() - tstart
print('predict {}ms'.format(elapsed * 1000))
plt.figure(figsize=(10,10))
plt.subplot(211)
plt.title('expected')
plt.plot(data[start+10:start+500+10])
plt.plot(result)
plt.subplot(212)
plt.title('predicted (stateless)')
plt.plot(result)
plt.show()
result_stateless = result 後々、stateful とのコードと合わせるため一括で predict せずサンプル数1つで予測させてる。
一応一通り予測できている。ちなみに "predict 6278.290271759033ms" かかった。
model.save_weights('/tmp/param.hdf5')
model_stateful = create_model(batch_size = 1, stateful=True)
model_stateful.load_weights('/tmp/param.hdf5')
model_stateful.summary() weight を保存して、stateful=True にしたモデルに作りなおして weight をロードする。つまり stateless のモデルと weight は一緒の状態になる。
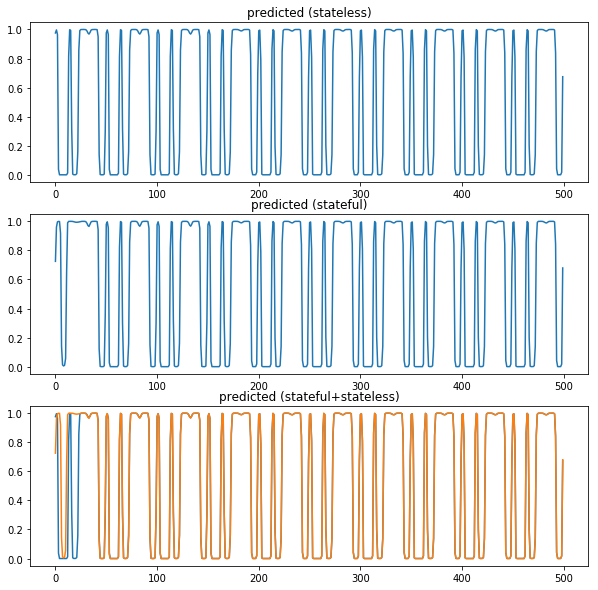
tstart = time.time()
start = 207
result = []
## preload same state with stateless
# model_stateful.predict( data[start-1-100:start-1].reshape( (1, 100, 1) ) )
for n in range(predict_len):
# give just new 1 timestep
predicted = model_stateful.predict( data[start+n-1:start+n].reshape( (1, 1, 1) ) )
result.append(predicted[0])
result = np.array( result)
elapsed = time.time() - tstart
print('predict {}ms'.format(elapsed * 1000))
plt.figure(figsize=(10,10))
plt.subplot(311)
plt.title('predicted (stateless)')
plt.plot(result_stateless)
plt.subplot(312)
plt.title('predicted (stateful)')
plt.plot(result)
plt.subplot(313)
plt.title('predicted (stateful+stateless)')
plt.plot(result_stateless)
plt.plot(result)
plt.show() stateful では毎回1ステップだけ与えて予測させる。最初は過去の時系列がないため乱れているけど、ステップを与え続けると stateless と同じように予測できる。stateful でもコメンアウトしたところを実行すれば最初から stateless と全く同じ状態になる。
これは "predict 327.3053169250488ms" で終わる。
CW の最小単位である短点の長さ t は以下で求められる。w は符号速度、単位 wpm (通常は 10〜40wpm) 。
5 (トトトトト 短点5つ)や訂正信号 <HH> (トトトトトトトト 短点8つ) を送信しているときに最大の帯域幅になる。短点の長さ t の on/off の繰り返しであるので、波長 2t の矩形波となる。24wpm では t = 50ms なので波長100ms、すなわち 10Hz の矩形波。
これを搬送波に乗せると (AM変調なので) 両側波帯に帯域が広がるため最低でも 20Hz の帯域幅になる。矩波形なので奇数次数の高調波も発生し、5倍まで考慮するだけで100Hzになる。
なお10wpm で 4Hz、50wpm で 21Hz の矩形波。
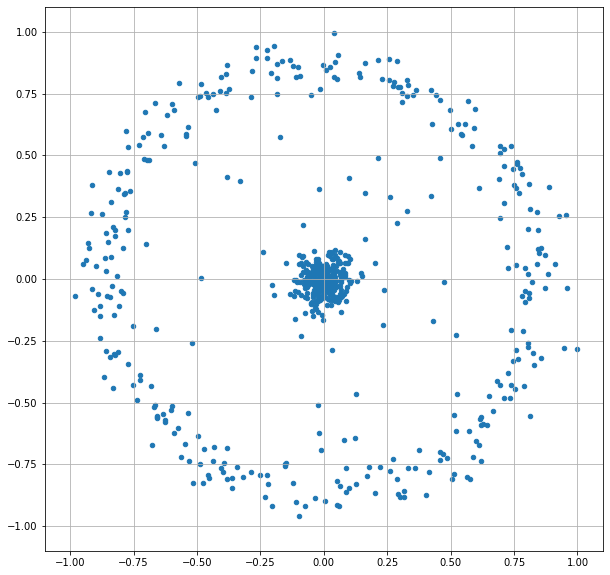
普通CWのコンスタレーションを気にすることはないと思うが、一応確認しておくと、BPSK などと比べるときに想像しやすい (なぜ BPSK が CW/OOK と比べて 3dB 有利かとか)
上の図のように中央部 (off) と周辺部 (on)にわかれる。
これがたとえば BPSK の場合は、中央ではなく、左端と右端になる。すなわち信号空間的には距離はCWの2倍になる。2倍=3dBよくなるということはこういうこと
モールスで必要なのはキャリア周波数の周辺帯域だけ。モールスは通信速度があまり早くなく、帯域幅も100Hz程度のため、周波数分解能と時間分解能にトレードオフのあるSFFTでも、十分解析可能なはずだと思った。
例によってここは node.js で作った。web-audio-engine を使って実際にモールスの信号をつくり、それを AnalyserNode で連続で FFT して画像をつくった。
ラベルデータは考えられるだけでいくつか作りかたがある
画像として処理するなら、どこからどこまでが符号でその符号が何かがわかればいいが、連続信号として処理したいなら、人間が認識できる最短の位置にラベル付けするのが正しそう、と考えた。
一応どの正解データも作れるのようにデータ生成コードを書いた。
符号のon/offはその後なんらかのアルゴリズムでさらにデコードする必要があるが、モールスの場合はクロックが固定ではないので割と面倒くさい。
ということで早々に符号列のパターンを直接認識させる方法をとることにした。認識させるのはあくまで符号列 (トツーやツートトト) であって、(A や B という文字ではない)
単語単位で認識させることができればもっと精度が上げられそうだけど、コールサイン (パターンはあるがほぼランダム) をとれないと意味がないので、ランダム精度を重視している。
モールスは、人間の場合、速度によってやや異る方法で認識している。
入力はタイムシリーズ型式 (None, timestep, features) timestep は 72、features はデコード対象周波数を中心とした magnitude。
出力はどのモールスの符号か?を表わす64次元のone-hotベクトル。
いろいろなモデルをつくっては壊して試した。
が、どうもこれではうまくいかなそうだという気がしてきた。2dB (ノイズ帯域500Hz) 程度のSNRでもほぼ認識できない。
角度は周期があるのでよくよく考えると平均や分散を出すのがむずかしい。いろいろやりかたがあるみたいだけど「単位ベクトル合算法」で計算してみる。
#!/usr/bin/env python
import numpy as np
deg = np.array([80, 170, 175, 200, 265, 345])
rad = deg * np.pi / 180
# ベクトル化 (計算が楽になるので複素数に)
cmp = np.cos(rad) + np.sin(rad)*1j
# 平均をとる
mean_complex = np.mean(cmp)
# このときの複素数の角度が平均角度
avg = np.angle(mean_complex)
# 絶対値(ベクトル長)小さいほどばらつきは大きい ( [0, 1] )
var = 1 - np.absolute(mean_complex)
print(avg * 180 / np.pi + 360) #=> 190.65
print(var) #=> 0.68 平均角度は分散も考えないと意味がないことがある。90°と270°の平均は↑の計算で180°になるが、ベクトル長さが0なので、平均として妥当な角度は存在してない。
こういう感じのコードをコピペする。本体は xorshift128、seed から初期値を xorshift32 で設定する (seed をそのまま初期値にすると、近い seed から似たような乱数が始まるので)
Math.random.seed = (function me (s) {
// Xorshift128 (init seed with Xorshift32)
s ^= s << 13; s ^= 2 >>> 17; s ^= s << 5;
let x = 123456789^s;
s ^= s << 13; s ^= 2 >>> 17; s ^= s << 5;
let y = 362436069^s;
s ^= s << 13; s ^= 2 >>> 17; s ^= s << 5;
let z = 521288629^s;
s ^= s << 13; s ^= 2 >>> 17; s ^= s << 5;
let w = 88675123^s;
let t;
Math.random = function () {
t = x ^ (x << 11);
x = y; y = z; z = w;
// >>>0 means 'cast to uint32'
w = ((w ^ (w >>> 19)) ^ (t ^ (t >>> 8)))>>>0;
return w / 0x100000000;
};
Math.random.seed = me;
return me;
})(0);
console.log('seed', 1); //=> seed 1
Math.random.seed(1);
console.log(Math.random()); //=> 0.9905915781855583
console.log(Math.random()); //=> 0.24318050011061132
console.log(Math.random()); //=> 0.00421533826738596
console.log(Math.random()); //=> 0.7972566017415375
console.log('seed', 2); //=> seed 2
Math.random.seed(2);
console.log(Math.random()); //=> 0.620286941062659
console.log(Math.random()); //=> 0.3181322005111724
console.log(Math.random()); //=> 0.7347465583588928
console.log(Math.random()); //=> 0.9439261923544109
console.log('seed', 1); //=> seed 1
Math.random.seed(1);
console.log(Math.random()); //=> 0.9905915781855583
console.log(Math.random()); //=> 0.24318050011061132
console.log(Math.random()); //=> 0.00421533826738596
console.log(Math.random()); //=> 0.7972566017415375 JSの数値型はすべて浮動小数点だけど、ビット演算は32bit整数で行われる。ほとんどの場合、ビット演算の結果は signed 32bit 整数として見たときの値になる。
// not not なのでビット表現は変化しないが、符号ビットが立っているので -1 になる ~~0xffffffff //=> -1
その中で 符号なし右ビットシフト演算子は「The result is an unsigned 32-bit integer.」と書いてあって、珍しい。
// 0ビットシフトなのでビット表現は変化しないが、符号ビットを無視するので 0xffffffff になる (-1)>>>0 //=> 4294967295
.png)
keras を使ってみたらすんなりモデルを書けたので、少し遊んでいる。入出力の shape の意味を理解できれば、詳しいアルゴリズムまで知ることなく遊べるぐらいまで簡単になっていた (だからといって最適なモデルが作れるわけではないけど)
過去の信号列から現在の信号状態を学習した結果、出力として各時点での再構築された信号列が出るわけだけど、これを並べていくと、ネットワークがどういう特徴を学んでいるか伺い知れるところがある。
メモ書き。試行錯誤の途中でコードが消えさったりしていてよくないので、やったことだけ書いておく
検出したい周波数を中心として0Hzに正規化 (検波)し、振幅を得る。100Hz のローパスフィルタをかけ、ダウンサンプル (200Hz 程度) する。
これを Denoising AutoEncoder のネットワークに順次入力し、デコーダ出力列から信号列を復元する (出力はある程度重なるので、最終的に平均を出す)。
出力は文字データではなく、フェージングや符号ゆらぎなどを解決した符号列とする。つまり入力数と出力数は必ず一致し、実際に文字化する処理は含まない。
.png)
こういうデータ。これはノイズが少ないのでわかりやすい。
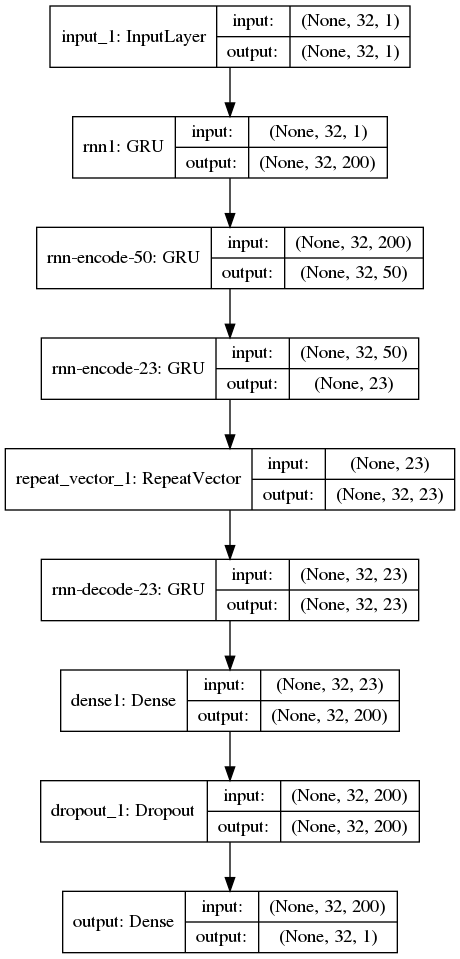
適切なパラメータが一切わからないが試行錯誤してこんな形になった。RNN の場合、入力シェイプがやや難解でググったり他の人のコードを読んだりして理解した。最初は LTSM を使っていたけど時間がかかるのでGRUにしてみた。
実際の入力データは keras.preprocessing.sequence.TimeseriesGenerator を使うのが楽だった。(最初は知らなくて自力でつくっていた)。timestep は 32、つまり過去の信号 32 サンプル分を1サンプルずつずらしながら入力している。
RepeatVector の前まではエンコーダで、その後がデコーダ。
node.js と web-audio-engine を組合せて大量にノイズ+信号のデータと正解データを作って学習させた。
学習はちゃんとできて、認識できるのは認識できる。
.png)
ただ、ノイズがかなり多い信号はやはりどうしようもなかった。聴覚だと聞きとれても、そもそも 0Hz に正規化した時点でノイズに埋もれてしまっていて、学習しようがなさそうだった。
.png)
ということでこの方法ではなく他の方法を考えてみることにした。
とりあえずできるのかな〜ベースでやったため、ちゃんとした評価方法を考えてなかった。SNRなど評価の指標を立てたい。しかしSNRは求めかたが難しくてこまってる。
binary_crossentropy を loss function にして、出力層を sigmoid にしているにも関わらず、肝心の target (y_train) が 0/1 ではなく、0/0.9999... みたいな値になっていた。当然誤差が常に発生することになる。
acc が一生上がらなくて???と思っていたらこれが原因だった。
nvidia driver のインストールまわりで Ubuntu が起動しなくなったり操作不能になったりする。OS 再インストールを何度かしなおす必要があった。機械学習専用のマシンに Ubuntu だけインストールするのがおすすめ。
Ubuntu は最新版ではなく LTS を入れること。事例が少なくて面倒なことになる。
とりあえずサードパーティドライバをインストールしてみる
sudo apt update sudo ubuntu-drivers autoinstall sudo reboot
これで nvidia-smi はできるが古いのが入ってしまった。
ppa から nvidia-driver-* でグラボにあった最新のドライバをいれる。
sudo add-apt-repository ppa:graphics-drivers/ppa sudo apt update sudo apt install nvidia-driver-430
ドライバが入ったら、tensorflow-gpu などを入れるが、各ツールキットのバージョンがうまく一致していなければ動かない。
自分でやろうとせず、余計なことをしないで Anaconda を使うのが正解。Anaconda が nvidia の外部ツールキットも含めて必要なものをすべて入れてくれる。
# これですべてが入る conda install tensorflow-gpu
$ python >> import tensorflow as tf >> tf.test.gpu_device_name()
なおドライバが古いと CUDA driver version is insufficient for CUDA runtime version と怒られる。