機械に機械学習のモデルを設計してもらう(何もわからない)
主に Gemini を使って、LLM主体でモデルの設計と学習をなるべくさせてみるということに数日とりくんでた。
自分が知らないことをLLMにやらせてみようというのを時々やっている。
課題
モールス符号の音響受信をさせる。7年前にKerasを使って頑張って似たようなことをやった覚えがある。その情報は渡さずに「今こういうのやるならどういうモデルがいいかな」という相談からはじめた。
Gemini いわく「 CTC損失を用いたStreaming Conformer (CNN + Transformer)」がいいのではということだった。よくわからないが全く理解しないままこの方向ですすんでみることにする。(賢いあなたは、わからないことがあったらその時点で必ず解消しましょう)。
リアルタイム音声認識ということでこれを提案してきたのだろう……
できたもの
https://cho45.github.io/morse-decoder-2026/demo.html
一応計画の段階で「最終的にブラウザでリアルタイムにストリーム処理できること」は入れてたので、いろいろ問題はありつつも動くものはできた。
pytorch でモデルを作り、最終的に onnx に変換して onnx web で動いている (wasm)。WebGPU でも動きはするけど、なんかちゃんとやってないのでパフォーマンスがでない。
「SNRいくつまでデコードができる」みたいなことを言いたいが、SNRの定義がなんともいえない (信号のある瞬間の振幅基準) ので難しい。このSNRで-15dBぐらいまでギリデコードができる。もうちょっと頑張ってほしいけど……
モデル構造
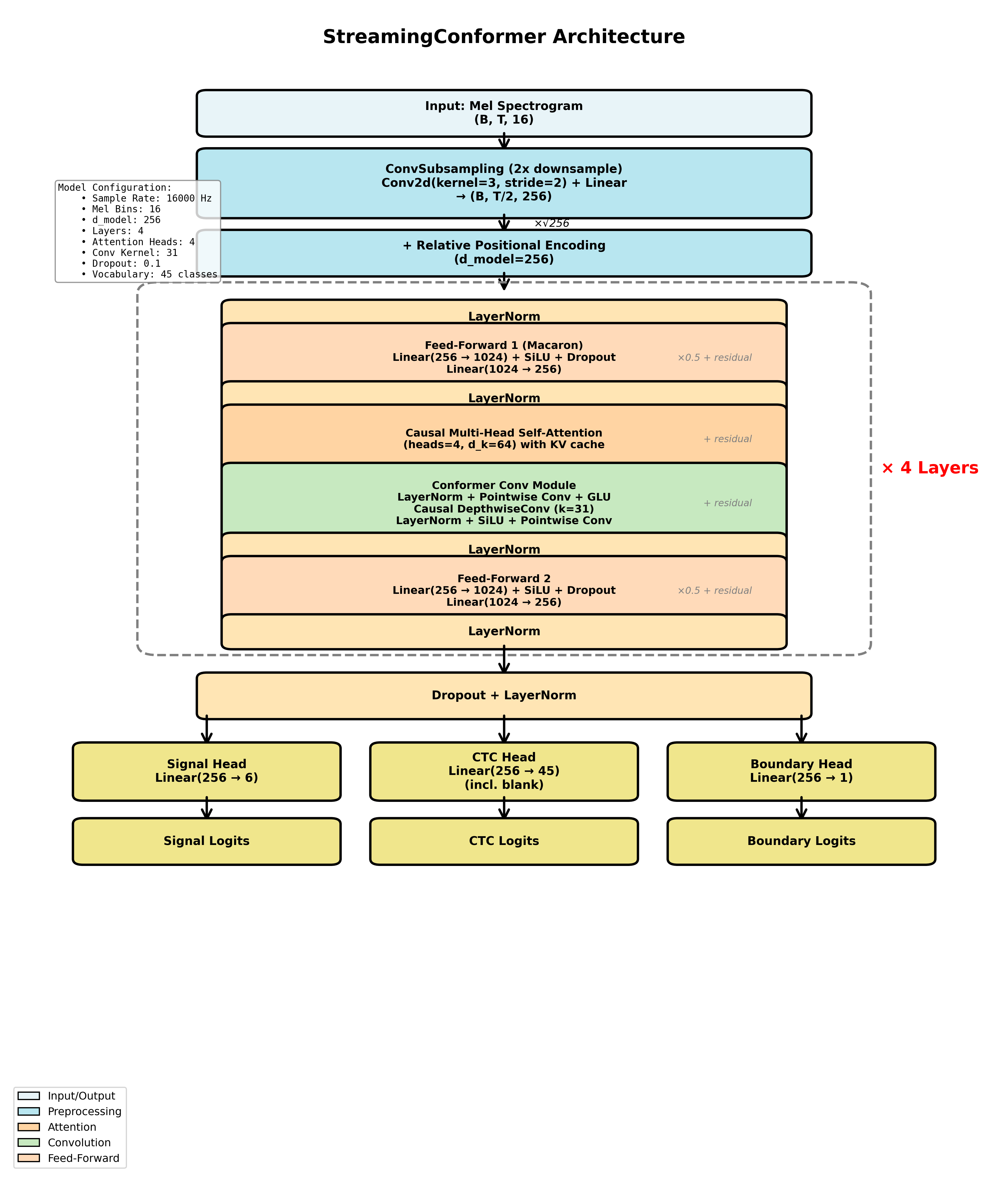
こんな感じ。CNN + Transformer のことを Conformerというらしい。まんなかの4層がそれ。ただのモールス復号のモデルにしてはデカいはずだけど、もっと少ない状態だとまったくうまくいかなかった。
入力はスペクトログラムを特定ピーク中心で切り出したものになっている。つまりベースバンド波形ではなく画像として見てる。別途ピーク検出と切り出しを行ってからこのモデルに入れる想定。位相が不要だから画像として扱うほうがいいっぽい?
しかし疑問点
モデルの内容には、ほぼ口を出さずにやれるところまでやったけど、そもそもいくつか疑問があるので、今更訊いた。
なぜ入力にメルスペクトログラム?
(意図: 特定周波数付近を切り出して渡しているので、通常のスペクトログラムで十分だし実用上は楽なのでは?)
A:「メルスペクトログラムは、一般的な音声認識(ASR)モデルの標準的な入力形式であり、情報の圧縮とノイズ耐性に優れているため採用されています。狭帯域にクリップする場合、メル尺度による圧縮の恩恵は薄れるため、本アプリにおいては線形スペクトログラムの方が解像度を維持でき、より合理的である可能性が高いです。」
「リアルタイム音声認識」にひっぱられてあんまり考えずに決めてるな……
出力がCTCなのはなぜ?
Q: 「今回のモールス学習の場合、かなり厳密にラベルがつけられるはずですよね。そして実際そうしているし Signal Head として出力もしている。それでもなおCTCを使う理由は?」
A:「Signal Head による物理的な信号認識を補助としつつ、CTC を使うことで「文字」としての文脈や区切りを柔軟に扱い、デコード時の頑健性を高めるためです。」
Q:「今回の場合ラベルの柔軟性というよりは出力の簡略化の側面がつよい?」
A:「はい、その通りです。Signal Headのように「全フレームを分類」するのではなく、CTCを使うことで「重複除去とblank削除」という単純なルールだけで、複雑な後処理なしに最終的なテキストを直接得られるという、出力の簡略化と利便性の側面が非常に強いです。」
フーン……
他
出力に CTC 以外に Signal Logits と Boundary Logits がある。これらはCTC出力からだけの学習で一切上手くいかなかったため、苦肉の策として追加した出力になっている。(ここは自分の指示……)
- Signal Logits: モールスの「短点」「長点」「符号間空白」「文字間空白」「単語間空白」「ブランク」を予想させる -- モールスの形状を強制的に学習させる
- Boundary Logits: モールスにおいて、符号が確定する瞬間に1になる。つまり文字符号の後の空白1ユニットの直後に発火する -- CTCが発火すべきポイントを間接的に学習させる意図 --- これそのままCTCへの入力に使ったら楽や~んと思ったけど、それだとCTCがチートして、Boundary Logits が高かったら適当に文字出すようになってしまって一敗
これが正しいことかはわからないが、Gemini 的には学習を進めるうえで有効ですとはいっていた。まぁ結果としてうまくはいったけど、これのせいでモデルサイズが大きくなっている面がある気がする。
得られたもの
やはり自分で正解知らないことをボーっとやらせるのは非常に難しい。結局急がば回れになることが多い…… わかってるんだよ。わかってるけどわからないまま作りたいんだ!
機械学習の修正タスク投げると、いくら事前に指示をしていてもテストを書かないし実行してくれない。最終的には「平均的なエンジニアはテストを書かず本体のコードだけに集中している。そこから学んでいるので自分もそういう傾向にあるのだ」という開きなおりをされた。
関連エントリー
- RNN モールスデコーダの試作 メモ書き。試行錯誤の途中でコードが消えさったりしていてよくないので、やったことだけ書いておく モールスの特徴 信号周波数が固定されており正弦...
- モールスデコーダの続き RNN モールスデコーダの試作 | tech - 氾濫原 波形ではなくSFFTの結果を認識させる モールスで必要なのはキャリア周波数の周辺帯...
- RNN (時系列) AutoEncoder で遊んでいる keras を使ってみたらすんなりモデルを書けたので、少し遊んでいる。入出力の shape の意味を理解できれば、詳しいアルゴリズムまで知る...
- ZOOM UAC-232 買った ZOOM ズーム USBオーディオインターフェース 2イン/2アウト32bitフロート入力対応 2023年発売 UAC-232 cho45 ...
- Ruby Sequel で生 SQL をメインに使う Sequel はドキュメント見ると SQL そのまま書くやりかたもとクエリビルダを介すやりかたも許されていると感じるので (別に他のライブラ...
