
✖
![]()
![]()
![]()
![]()
![]()
![]()
http://www.sqlite.org/withoutrowid.html WITHOUT ROWID 最適化について
SQLite は常に暗黙的な rowid カラムを持っていることになっている。これはカラムとして明示することもできるし、interger primary key として定義されたフィールドは暗黙的な rowid の代わりにすることができる。SQLite ではこの rowid が基本のプライマリキーになっている。
適当な数値をプライマリキーにしたい場合はこれで全く問題ないが、複合キーだったり文字列をプライマリキーにしたい場合、その表面上のプライマリキーとは別に rowid カラムができる。このケースでは表面上のプライマリキーを使って SELECT しようとすると、表面上のプライマリキーのインデックスを探したうえで、さらに rowid のインデックスを探すことになる。つまり、このケースのプライマリキーとは単に UNIQUE なインデックスでしかない。
そこそこ最近(3.8.2・2013年)からは WITHOUT ROWID をテーブル定義時に指定することで、暗黙的な rowid 生成を抑制して、プライマリキー指定した定義を「真のプライマリキー」とすることができる。
これによって
と良いことがある。一方デメリットで気になるのは
![]()
![]()
![]()
TF-IDFによる類似エントリー機能の実装をしてみました。ほぼSQLiteですませるような構成です。
MeCab を使った形態素解析などでもいいのですが、お手軽にやりたかったので以下のようにしています。
my $text = ...;
$text =~ s{<style[^<]*?</style>}{}g;
$text =~ s{<script[^<]*?</script>}{}g;
$text =~ s{<[^>]+?>}{}g;
$text =~ s{[^\w]+}{ }g;
my $words = reduce {
$a->{$b}++;
$a;
} +{},
map {
s/^\s|\s$//g;
$_;
}
map {
if (/[^a-z0-9]/i) {
Text::TinySegmenter->segment($_);
} else {
$_;
}
} split /\s/, $text; 不必要なHTML要素及びタグを削除し、記号類を全てスペースに置換したうえでスペースで分割し、日本語が含まれていそうな部分だけ TinySegmenter による簡易形態素解析をしています。
自分しか書かない日記の類似をとるので、表記揺れが殆どないことを前提に、アルファベットだけで構成される部分に関してはそのまま特徴語としたいためです。また、プログラムについて書くことが多いので日本語部分は比較的重要度が低いという見立てがあります。
転置インデックスはあるワードがどのエントリに含まれるかを記録したデータ構造です。エントリー中の文章を適切な粒度で分割して、ワードからエントリーをひけるインデックスをつくります。
転置インデックスだけでも、あるワードが含まれるエントリーのリストを得るのは簡単になるので、例えば「共通ワードが多いエントリ同士は類似している」というスコアリングを採用するなら、転置インデックスのみで実現できます。
DBとしてSQLiteを使っているので、簡単な定義の単一テーブルだけを作ってなんとかしています。
CREATE TABLE tfidf (
`id` INTEGER PRIMARY KEY,
`term` TEXT NOT NULL,
`entry_id` INTEGER NOT NULL,
`term_count` INTEGER NOT NULL DEFAULT 0, -- エントリ内でのターム出現回数
`tfidf` FLOAT NOT NULL DEFAULT 0, -- 正規化前の TF-IDF
`tfidf_n` FLOAT NOT NULL DEFAULT 0 -- ベクトル正規化した TF-IDF
);
CREATE UNIQUE INDEX index_tf_term ON tfidf (`term`, `entry_id`);
CREATE INDEX index_tf_entry_id ON tfidf (`entry_id`); 見ての通りですがターム(ワード)とエントリIDでユニークなテーブルです。
エントリ内のHTMLを適当な粒度で分割したのち、このテーブルに入れています。この段階では term, entry_id, term_count だけ埋めます。
INSERT INTO tfidf (`term`, `entry_id`, `term_count`) VALUES (?, ?, ?); TF-IDFは特徴語抽出のアルゴリズムです。文書中のワード出現頻度 (Term Frequency) と、全文書中のワード出現頻度の逆数( Inverse Document Frequency) から、ある文書のあるワードがどれぐらいその文書を特徴付けているかをスコアリングできます。
転置インデックスから「共通ワードが多いエントリ同士は類似している」というスコアリングを使ってエントリを抽出すると、ワード数の多いエントリ同士は類似していなくても類似しているとスコアリングされてしまいます。
TF-IDF を使って各ワードに重み付けをすれば「特徴語の傾向が似ている文書は類似してる」というスコアリングにすることができます。
まずは後述する正規化を考えずにテーブルの tfidf カラムを埋めます。
-- SQRT や LOG を使いたいので
SELECT load_extension('/path/to/libsqlitefunctions.so');
-- エントリ数をカウントしておきます
-- SQLite には変数がないので一時テーブルにいれます
CREATE TEMPORARY TABLE entry_total AS
SELECT CAST(COUNT(DISTINCT entry_id) AS REAL) AS value FROM tfidf;
-- ワード(ターム)が出てくるエントリ数を数えておきます
-- term と entry_id でユニークなテーブルなのでこれでエントリ数になります
CREATE TEMPORARY TABLE term_counts AS
SELECT term, CAST(COUNT(*) AS REAL) AS cnt FROM tfidf GROUP BY term;
CREATE INDEX temp.term_counts_term ON term_counts (term);
-- エントリごとの合計ワード数を数えておきます
CREATE TEMPORARY TABLE entry_term_counts AS
SELECT entry_id, LOG(CAST(SUM(term_count) AS REAL)) AS cnt FROM tfidf GROUP BY entry_id;
CREATE INDEX temp.entry_term_counts_entry_id ON entry_term_counts (entry_id);
-- TF-IDF を計算して埋めます
-- ここまでで作った一時テーブルからひいて計算しています。
UPDATE tfidf SET tfidf = IFNULL(
-- tf (normalized with Harman method)
(
LOG(CAST(term_count AS REAL) + 1) -- term_count in an entry
/
(SELECT cnt FROM entry_term_counts WHERE entry_term_counts.entry_id = tfidf.entry_id) -- total term count in an entry
)
*
-- idf (normalized with Sparck Jones method)
(1 + LOG(
(SELECT value FROM entry_total) -- total
/
(SELECT cnt FROM term_counts WHERE term_counts.term = tfidf.term) -- term entry count
))
, 0.0) 一時テーブルを使いまくっています。何度も同じ TF-IDF 計算をするなら効率化のため保存しておけそうなテーブルもありますが、更新処理が複雑になるためTF-IDF更新時に作っては消しています。修正が頻発するような開発初期段階では特に一時テーブルは設計変更などに強くて便利です。
TF-IDF を計算して、エントリごとにエントリ中の単語数次数を持つ特徴ベクトルを作ったことになります。このあとコサイン類似度をとるわけですが、その際にはベクトルの大きさが不要なのでこれを正規化します。
ベクトル正規化はあるベクトルを方向(角度)をそのままに長さを1にするとこを言っています。コサイン類似ではエントリごとの角度だけを比較したいので、あらかじめ文書ごとのベクトルを正規化することで計算を簡単にできます。
-- エントリごとのTF-IDFのベクトルの大きさを求めておきます
CREATE TEMPORARY TABLE tfidf_size AS
SELECT entry_id, SQRT(SUM(tfidf * tfidf)) AS size FROM tfidf
GROUP BY entry_id;
CREATE INDEX temp.tfidf_size_entry_id ON tfidf_size (entry_id);
-- 計算済みの TF-IDF をベクトルの大きさで割って正規化します
UPDATE tfidf SET tfidf_n = IFNULL(tfidf / (SELECT size FROM tfidf_size WHERE entry_id = tfidf.entry_id), 0.0) コサイン類似はベクトル長さを無視しての角度の差を求めるためのアルゴリズムです。2つのベクトルの角度の差のコサインを求めます。例えば、2つのベクトルの角度差が0(一致している)場合、 = 1、90度(直交・相関関係なし) なら 、180度(負の相関)なら と、なります。
前もってベクトル正規化をしているのでかけ算と足し算だけで計算できます。
ただ計算が簡単とはいえ、候補エントリ数*関係するワード(ターム)の数だけレコードをひいてくる必要があるので結構大変になってしまいます。
ここの効率化方法があまり思いつかず以下にようにしています
特徴語の共通語が多い順で足切りをしているので、長いエントリほどここでは有利となってしまいます。また、極端に短いエントリに関しては100エントリ以上が同一数の共通語を持つ状態になる場合があり、このケースではスコアをつける前に「類似」と判定すべきエントリが確率的に足切りされてしまうので正確ではありません。
TF-IDF の大きい順に50件だけを採用しているので、正確なコサイン類似度ではありません (ベクトル正規化のときに使った次数と違う) が、無視しています。
うまくいった場合はスコアリングで上位に類似エントリが集まるようになります。
-- 類似していそうなエントリを共通語ベースでまず100エントリほど出します
CREATE TEMPORARY TABLE similar_candidate AS
SELECT entry_id, COUNT(*) as cnt FROM tfidf
WHERE
entry_id > ? AND
term IN (
SELECT term FROM tfidf WHERE entry_id = ?
ORDER BY tfidf DESC
LIMIT 50
)
GROUP BY entry_id
HAVING cnt > 3
ORDER BY cnt DESC
LIMIT 100
-- 該当する100件に対してスコアを計算してソートします
SELECT
entry_id AS eid,
SUM(a.tfidf_n * b.tfidf_n) AS score
FROM (
(SELECT term, tfidf_n FROM tfidf WHERE entry_id = ? ORDER BY tfidf DESC LIMIT 50) as a
INNER JOIN
(SELECT entry_id, term, tfidf_n FROM tfidf WHERE entry_id IN (SELECT entry_id FROM similar_candidate)) as b
ON
a.term = b.term
)
WHERE eid != ?
GROUP BY entry_id
ORDER BY score DESC
LIMIT 10 これによって求められた類似エントリは別途テーブルに保存しておいて、表示時にはこのテーブルのみをひいてくる構成にしました。
![]()
![]()
![]()
結構みてる気がする
![]()
![]()
![]()

久しぶりに CD を買った。原点回帰っぽい構成みたいだけど、どうなんだろうな〜
ところで久しぶりにリッピングしようと思ったら CD ドライブがついているPCが起動せず、面倒なのでドライブを買った……

ASUS外付けDVDドライブ 軽量薄型/M-DISC/バスパワー/Win&Mac/USB2.0(USB3.0搭載PCでも利用可能)/書込みソフト付属/ブラック SDRW-08D2S-U LITE cho45
前までは EAC でリッピングしていた記憶があるけど、今回は iTunes でリッピングした。CDDB がまだ生きてて簡単だった。
![]()
![]()
![]()
自宅にいくつか Anker の充電器はあるが、Quick Charge 付きのものはなかった。そして、充電器いくつかあるとはいえ、旅行にいこうとすると足りなくて不便だった。
ということで上記のものを買った。ポート数多くなって便利。
Zenfone2 は Quick Charge 2.0 対応なので (特にそうとは書いてないが 9V 充電可能)、繋ぐと以下のように「急速充電中」とともに、発熱に関しての警告がマーキーで表示される。
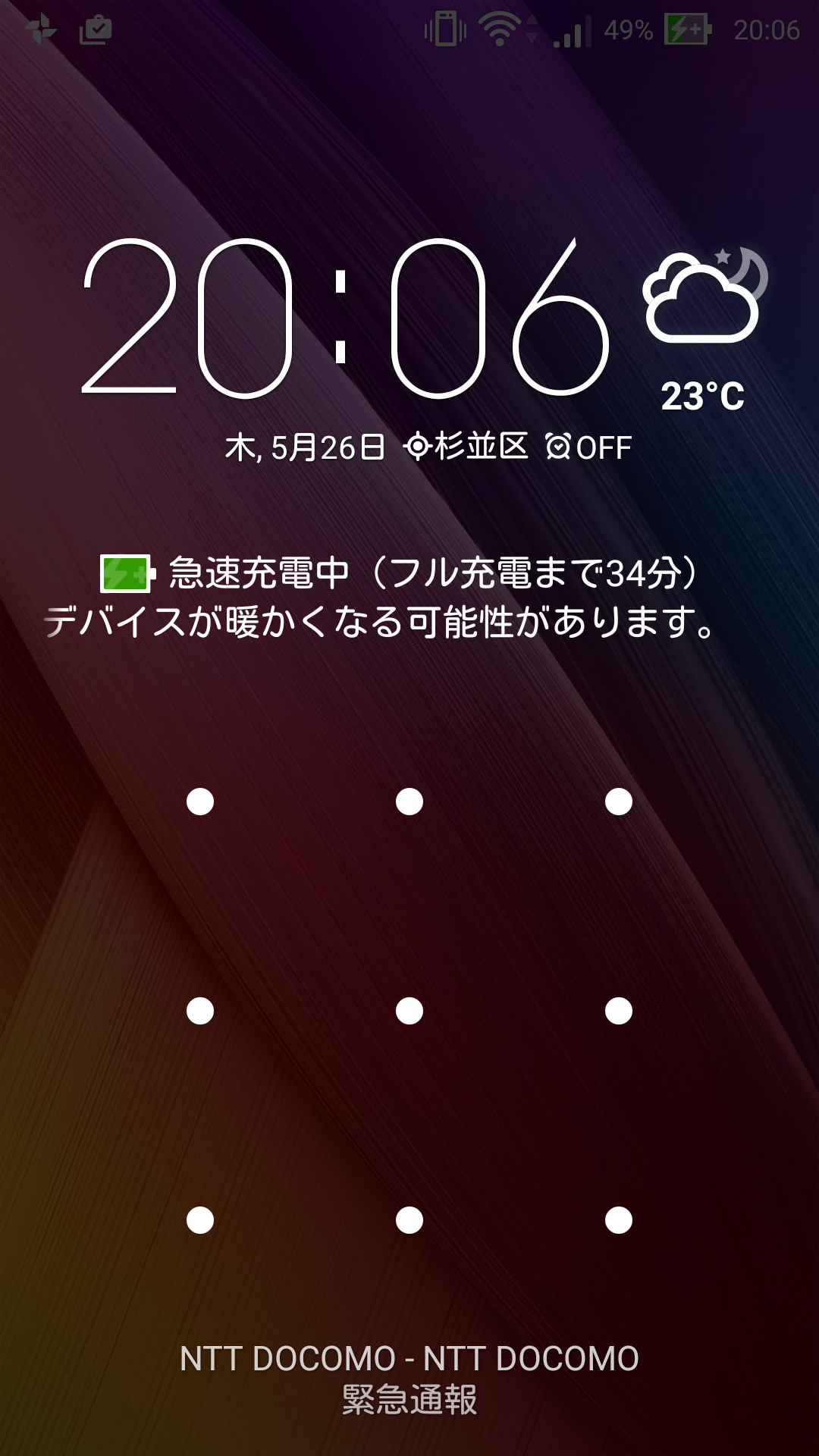
ただ、Quick Charge 対応ポートは1つだけなので、急速充電したいときは気をつける必要がある。USBケーブルをQuick Charge ポートだけ色が違うものにした。
![]()
![]()
![]()
![]()
![]()
![]()
SQLite にはかなり基本的な算術演算関数しかない。追加で何かしらやるためには拡張 (Run-Time Loadable Extension) を使う必要がある。
LOG や SQRT などはオフィシャルの Contributed Files のextension-functions.c をコンパイルして使う。 http://www.sqlite.org/contrib
Ubuntu でのコンパイル。当然ながら SQLite のヘッダファイルなどが必要なので入れておく。
sudo apt-get install libsqlite3-dev
そのうえで以下のようにコンパイルする。apt-get で入れてる場合 -I などは指定しなくてもデフォルトで良さそう。必要なら pkg-config sqlite3 とかして引数を得る。
gcc -fPIC -shared extension-functions.c -o libsqlitefunctions.so -lm
extension-functions.c の冒頭にもコンパイル方法が書いてある。ただし、今はそれだと上手くいかなくて、-lmは最後につけないとダメ。罠があって、リンクに失敗しても load_extension するまで気付かない。
使うときは以下のように load_extension() を使う
select load_extension("/path/to/libsqlitefunctions.so"); Perl から DBD::SQLite 経由で使う場合、
$dbh->do('SELECT load_extension("/path/to/libsqlitefunctions.so")'); とする。が、実はこれだけだと動かず、以下のように謎のエラーが出る。
DBD::SQLite::db do failed: SQL logic error or missing database not authorized
ドキュメントにも書いてあるが、sqlite_enable_load_extension を前もって呼ぶ必要がある。
$dbh->sqlite_enable_load_extension(1);
# または
$dbh->func(1, "enable_load_extension"); 拡張の開発方法については Run-Time Loadable Extensions を見る。
![]()
![]()
![]()
食品安全委員会の QA によると、
大豆イソフラボンの安全な一日摂取目安量の上限値70〜75mg/日(大豆イソフラボンアグリコン換算値)
と書いてある。150mg ぐらい摂取すると健康被害の影響があるかもしれないので、その半分を上限にしているらしい。ちょっと調べてみると、これが案外厳しい基準に思えたので記録しておく。
大豆イソフラボンアグリコン換算は以下のようになっている。食品表示にある「イソフラボン」はイソフラボン配糖体のことなので、換算して考える必要がある。
(例)大豆イソフラボン配糖体10mg×0.625 =大豆イソフラボンアグリコンとして 6.25mg
ここで、一番メジャーな紀文の調整豆乳について見てみると、「イソフラボン 43mg/200ml」となっている。0.625 をかけて、26.875mg/200ml (大豆イソフラボンアグリコン換算値)
また、FAQ中の表に豆乳の含有量について記載がある。
(大豆イソフラボンアグリコンとしてmg/100g)
〜 省略 〜食品名(検体数):豆乳(3検体)
含有量: 7.6〜59.4
平均含有量: 24.8
紀文の調整豆乳はだいたい平均的な値の倍(訂正)
もし毎食コップ一杯の豆乳を飲むと、それだけで75mg/日を超える。もちろん他の大豆製品 (特に味噌や納豆) にも含まれるので豆乳単体でどうとはいえない。
なお、大豆イソフラボンアグリコンの一日摂取目安量の上限値、70~75 ㎎/日は、この量を毎日欠かさず長期間摂取する場合の平均値としての上限値であること、また、大豆食品からの摂取量がこの上限値を超えることにより、直ちに、健康被害に結びつくというものではないことを強調しておく。
と書いてある通りなので、豆乳めっちゃ好きすぎる!!!とか、豆乳で必要タンパク質全部とるぞ!!みたいな意気込みがなければ、平均的には大丈夫なのかな。
大人は毎日1日コップ一杯ぐらいは他に大豆食品をとっていても問題なさそう。妊婦や子供に対してはもっと気をつけるべきのようで、だぶん牛乳代わりに毎日飲む/飲ませるみたいな習慣はやめたほうが良さそう、というのが僕からみた温度感です。

キッコーマン飲料 調製豆乳 200ml×18本 cho45
![]()
![]()
![]()
電子工作などのときに、一時的に部品を挟んでおきたいときとかの道具として何を使っているかといえば標題にある通り逆作用ピンセットというもので、これはすなわちノーマリークローズなピンセットである。力を加えていないときはピンセット自体のバネで閉じており、挟んでおいておくことができる。
便利な特徴がいくつかある
この手の逆作用ピンセット(反作用ピンセットや逆作動ピンセットなど、用語が揺れてる)は100均でも売ってることがある。自分が使っているのも100均でたまたま買ったものだけど、ものすごく活用している。

だいぶ前に便利かと思ってヒートクリップというのを買ったことがあるが、結局ほとんど使っていない。

ヒートクリップはリード付き半導体のはんだ付け時に熱から守るために使うというのが本来の用途だが、そもそもそんなに熱に弱い半導体って今時使うことがない。
そして汎用のクリップの用途で考えるとこの商品はバネ圧が強すぎて使いにくい。ので、この手の用途でも逆作用ピンセットのほうが圧倒的に使いやすい。
![]()
![]()
![]()
![[シチズン Q&Q] 腕時計 フォルコン V722-850 ブラック - CITIZEN](https://m.media-amazon.com/images/I/41OvjM8ihNL._SL500_.jpg)
腕時計は普段しないのだが、某国家試験をうけるときに時計が必要だったのでこれを買っていた。最近はしばらく妻が使っていたが、電池切れで動かなくなってしまった。妻用には別の時計を買ったが、動かない時計だけ放置しておくのもなんなので電池を変えることにした。
元々入っていたのは SR626SW だが、100均で売ってたのが SR621SW だけだったため、こちらで代用した。この2つは厚みが違う。よって入らないことも予想されたが、100円なので試してみることに。結果的にはうまくいった。ただし、やはりすこしゆるい。
元が1000円の時計を時計屋で電池交換してもらうのもかなりアレなので、自分でやった。
この時計の場合特に特殊な工具はいらず、小さめのドライバーがあれば裏蓋をはずせる。裏蓋さえはずせば電池が見えるのでとりかえるだけだった。
Wikipedia のIEC_60086の項にも書いてあるけど、型番によって化学構造(電圧や電流などの決定要因)と寸法がわかるようになっている。
SR626SW は
![]()
![]()
![]()
体調不良 - 氾濫原 のあと、月曜日の昼ぐらいから気持ち悪くなった。20時ぐらいにマスク(電車が臭いので)して帰宅開始したがなんとか(というか奇跡的に)吐き気を抑えて帰宅できた。夕食は食べずに寝たが、22時ぐらいに結局トイレで吐いて、多少はすっきりした。ただ下痢なのと発熱で夢見が悪くあまり寝れず。昼食から10時間ぐらい経っていたけど、胃の中に滞留物がまだ残っていた。
子供も夕方あたりに吐いたらしくて家の中がだいぶひどかった。
火曜日は会社休んで病院。結局ウィルス性胃腸炎らしいが、待ってる以外に特に治療法もないみたいで、ビオフェルミンと吐き気止めと抗生物質が処方された。午前中は何も食べず、昼ぐらいにおかゆを食べた。火曜日中は特に良くならず。
火曜の昼あたりから今度は妻が発症した。 (定期検診で病院にいってたがついでに点滴をうけてきたらしい)。一方子供は火曜夕方ぐらいには元気になった。
水曜朝もまだ気持ち悪くて結局会社を休んだ。昼ぐらいまでに一度症状が軽くなったが、うどんを食べてしばらく経ったらまた気持ち悪く。
胃腸炎といえば一ヶ月前にも患っておりとにかく体調不良の頻度と強度が高い。なんとかしてほしい。
![]()
![]()
![]()
KX2
http://qrznow.com/new-elecraft-kx2-announced-this-thursday-at-the-dayton-hamvention-2016/
アメリカの Elecraft から KX2 という無線機が出たらしいです。KX3 よりも小さい! バンドはCW/DATA/SSB 80m〜10m と、KX3 からは 50MHz と AM/FM がオミットされています。出力も KX3 が最大15Wに対しKX2 は 10Wのようです。KX3 のオプションにあったルーフィングフィルタはKX2ではなし。I/Q 出力もなし。
肝心の重さは 13oz (369g) と、KX3 よりもさらに半分ぐらいの軽さのようです。
本体 $749。ATU が $179.95、Li-ion のバッテリーパックが $59.95。モバイルの HF トランシーバとしては競合するものがもともと殆どないんですが、KX2 は完全に競合するものがなく、コストパフォーマンスは良さそうです。とはいえ I/Q 出力がないのがちょっと時流からするとキツい感じがします。回路図みながら辿ればとれそうな気はしますが。
![]()
![]()
![]()
金曜日の夕方ぐらいから全身倦怠感と頭痛がはじまり、微熱(37度台)に。熱は土曜日中ぐらいで下がったが頭痛は治らず、今(月曜日)でもまだ痛い。
![]()
![]()
![]()
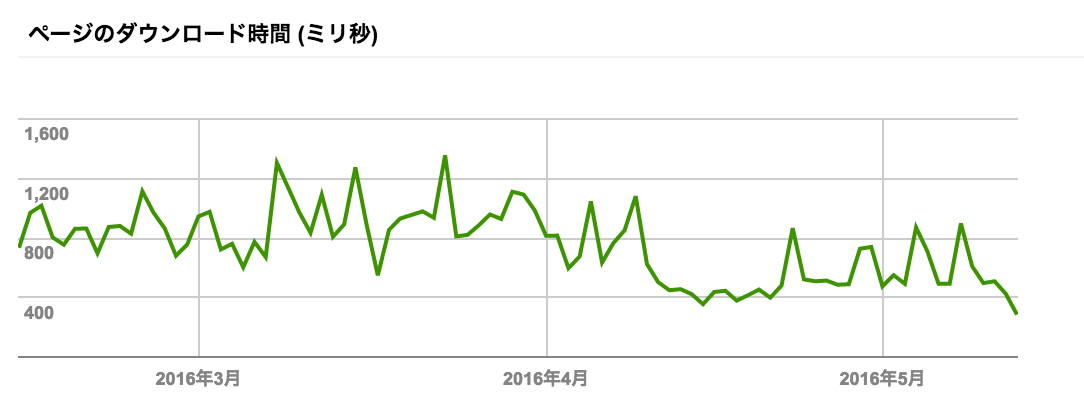
sitemap.xml を送信した翌日ぐらいに Googlebot からの連続したアクセスがくるようになる。Googlebot は HTTP/1.1 で Keep-Alive が有効なため、普段にパラパラくるアクセスよりも、このときのように連続してアクセスされる場合、多くの場合でコネクション時間がなくなるために高速にレスポンスを返せる。
連続したアクセスの場合、2分ぐらい Keep-Alive している。
これは結果として Search Console の「クロールの統計情報」に表示されている「ページのダウンロード時間 」のグラフにも反映されているような感じで、sitemap.xml を追加した次の日あたりで平均ダウンロード時間がかなり少なく表示される。
![]()
![]()
![]()
Server::Starter は hot deploy 用の汎用スーパーデーモンで、Perl で書かれています。h2o の起動にも使われているのでみなさんおなじみでしょう!
Server::Starter がやってることは、Server::Starter 側で listen したソケットの fd を環境変数につっこんで子プロセスを起動というものです。子プロセス側では渡ってきた環境変数を読んで、fd について accept すれば良いことになります。
これを node.js でやるには以下のようにすれば良いようです。
//#!/usr/bin/env node
"use strict";
const http = require('http');
const server_starter_port = process.env['SERVER_STARTER_PORT'];
if (!server_starter_port) {
console.log('SERVER_STARTER_PORT is not set');
process.exit(1);
}
const fds = server_starter_port.split(/;/).map( (i) => i.split(/=/) );
const server = http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World\n');
});
process.on('SIGTERM', () => {
console.log('server exiting');
server.close();
});
for (let fd of fds) {
console.log('listen', fd);
server.listen({ fd: +fd[1] });
} 起動はたとえば以下のように
start_server --port=5001 -- node server.js
http.Server の listen() のドキュメントには fd を渡せるバージョンが書いてありませんが、net.Server の listen() がサポートしているので、同様に渡せるようです。
これだけで node.js のプロセスの hot deploy が簡単にできます。
node.js には cluster というのがあります。これは node.js を複数プロセスで動かすための仕組みなんですが、これの woker プロセス側の listen() は master プロセスと ipc してうまいことやるみたいな感じのようです。
![]()
![]()
![]()
このサーバはVPS 1台で動いていて、メモリは1GBしかありません。常時メモリ上限まで使いきっており、スワップファイルもそこそこあります。そういうわけで、できるだけメモリ消費をケチりたいのです。
このサーバ上で動いているサービスがいくつかあるのですが、実際のところどれも殆どアクセスはありません。一番アクセスされていてこの日記システムぐらいです。
それらのサービスをそれぞれ別プロセスで起動させておくと、たいへん無駄なので、できるだけプロセス自体を同居させています。
Plack::Builder が提供している mount() を使うと、vhost を実現できます。
builder {
mount 'http://lowreal.net' => do {
my $guard = cwd_guard("lowreal.net/");
Plack::Util::load_psgi("script/app.psgi")
};
mount 'http://env.lowreal.net' => do {
my $guard = cwd_guard("env.lowreal.net/");
Plack::Util::load_psgi("script/app.psgi")
};
}; このようにすると、Host ヘッダに応じて、ディスパッチするアプリケーションを変えることができます。
これを利用して、複数の psgi アプリケーションを1つの psgi アプリケーションにまとめて起動しています。
ただし、起動時 (load_psgi時) にだけ cwd を設定しているため、cwd 依存のコードがあるとうまく動きません。
単にプロセス数も減らせますが、それぞれのアプリケーションで共通で使うモジュールがかなり多いので、それらを fork 前にロードして共有しておくことで、プライベートメモリ使用量を削減しようという意図もあります。
上記のまとめた psgi アプリケーションを start_server と plackup 経由で起動しています。
start_server 用には以下のような環境変数を設定しています
export KILL_OLD_DELAY=15
export ENABLE_AUTO_RESTART=1
export AUTO_RESTART_INTERVAL=3600
exec setuidgid cho45 \
$PERL/bin/start_server --path=/tmp/backend.sock --port=5001 -- $PERL/bin/plackup -p 5001 -s Starlet\
--max-workers=5 \
--max-reqs-per-child=500 \
-a backend.psgi ENABLE_AUTO_RESTART によって、時間経過で自動的にプロセス全体を再起動しています。再起動間隔は AUTO_RESTART_INTERVAL に決まり、この場合1時間ごとになっています。
KILL_OLD_DELAY には新プロセスが起動して、リクエストが受けつけられるようになるまでにかかる時間を余裕をもって指定します。これを指定しないと、プロセス再起動がかかるたびに、モジュールなどのロードが終わるまでの数秒アクセス不能時間ができるので、特に ENABLE_AUTO_RESTART する場合は必須そうです。
これで、もしメモリリークしていても1時間以内に綺麗になることが保証されるとともに、fork した worker プロセスが働いて Copy on Write が起こってプライベートメモリ量が増えたとしても、1時間以内に fork しなおしになるため、共有メモリ量が一定より高い状態を保つことができます。
Linux のプロセスが Copy on Write で共有しているメモリのサイズを調べる - naoyaのはてなダイアリー にある shared_memory_size.pl が便利でした。共有メモリの割合を表示してくれるのでわかりやすいです。
Starlet のプロセス名をわかりやすくしたかったのも、このスクリプト実行時に指定しやすくするためでした。
こんな感じで使っています。
shared-memory-size.pl `pgrep -f /srv/www/backend.psgi` PID RSS SHARED 29583 55460 47792 (86%) 29584 55760 44688 (80%) 29585 65224 41396 (63%) 29586 56280 44704 (79%) 29587 55352 44660 (80%) 29588 58908 46748 (79%)
起動してすこし経ったあとの状態です。起動直後は90%以上ですが、プロセスが動くごとに少しずつ共有割合が減っていきます。自分の環境で、観測したうちだと60%ぐらいまで下がるようです。
ps -c で見るメモリ使用量には共有分が考慮されていないので、実際の物理メモリ使用量よりもかなり大きく出ます。仮に1プロセスあたり70MBぐらいメモリを消費していても、うち40MBぐらいが共有であることを考えると、worker プロセス1つあたり30MB、5プロセスで150MB程度の物理メモリ消費量になります。
![]()
![]()
![]()
アクセスログを見ていたら Applebot なるものからのアクセスがあった。
https://support.apple.com/ja-jp/HT204683
ほんとに Apple のウェブクローラらしい。ただ
robots の制御指示で Applebot には言及していなくても Googlebot について指定されている場合、Apple のロボットは Googlebot に対する指示に従います。
と書いてあって、それはどうなんだ、という感じがする。
![]()
![]()
![]()
UAからしてなんか怪しいが、210.160.8.236 からくる BOT で、DNSを逆引きすると target.microad.jp. らしい。マイクロアドを使ってるつもりはないんだけど、Adsense 貼るとくるのかな?
まともなクローラのつもりなら、UA をもうちょっとわかりやすくしといてほしいですね。まともな会社なら自社クローラのUAと目的ぐらい書いとくべきだと思います。
![]()
![]()
![]()
![]()
![]()
![]()
今までのページャは良くある ?page=2 みたいな形式でした。これは内部的には offset / limit を使う SQL になります。
変更したページャは /.page/20160509/3 という形式です。20160509 が表示するページ番号、3 がそのページに表示する最大の数です。ページ番号はトップページからのページの場合、日付になっており、内部的には日付ベースの where 句になります。3 は limit です。
これらによって、サーバ側のエントリ表示数のデフォルト設定によらず、URLによって決まる内容が生成されます。よって
このサイトは「日記」なので、日付単位でエントリがまとめられています。「ブログ」の表示に慣れていると違和感があるかもしれませんが、以下のような違いがあります。
ちょうど、紙に日記を書くときのように、1日の中では連続し、1日単位では独立しているというイメージです。
この挙動は正直初見ではわかりにくいと思うのですが、過去分は1日単位で上から下へ書かれる前提で複数のエントリを構成しているケースがあって、変えるに変えれません。
![]()
![]()
![]()
子供のおもちゃのチョロQを見ていて不思議に思ったことがあって調べたので書いておきます。
チョロQみたいなプルバック式のミニカーは、後退するときにぜんまいを巻き上げることで、前進時に動力にするわけです。なので、くるま全体を床に押し付けたまま前後してもぜんまいは巻き上がらず (後退で巻き上がっても前進させた分巻き戻る)、走らないと思っていました。
自分の遊んだ記憶だと、後退するときだけ押し付けて、一旦持ちあげてもう一度後退させていた覚えがあるのです。
いつこの「プルバックの走らせかた」を学んだのか全く覚えていませんが、当然そういうものという認識でいました。そしてそもそも「後退時に巻いたぜんまいで動く」以上の仕組みを知りませんでした。
子供は「プルバックの走らせかた」を知らず、適当に前後させたらなんかうごくことだけ学習しています。
子供が遊んでるときの挙動を見てるいると、ただ床に押し付けてゴリゴリと前後するだけでもぜんまいが巻き上がり、しかもどう見ても巻いた以上に長い時間回転することに気付きました。
Wikipedia の「プルバック式」の項を見ると
ゼンマイを使うプルバック式動力では、後退の時のみギア比の大きい状態になるよう、内部の歯車が浮き上がるようになっており、ゼンマイの力で前進する時だけタイヤを高速回転させるような構造を持つものも多い。
と書いてあって、ギア比が前進と後退で変わるような仕掛けがあるようでした。
「プルバック ギア」とかで検索すると、もうすこし詳しいページも見つかります。構成するギアのうち2つのギアの軸は方向によってずれることで、いずれか一方が噛み合うように調整されているようです。
もしかすると常識なのかもしれないですが、こういう面白い仕掛けがしてあるとは考えていなかったので、びっくりしました。
![]()
![]()
![]()
結局ガルパンは5回ぐらい見てしまった。劇場版がみたい。
![]()
![]()
![]()
ボトルガムを買うと、だいたい2日ぐらいでなくなってしまって金がもったいないという感じになってしまう。
職場にいると無限にストレスが溜まってるので、手の届くところにガムとか食べものを置いておくと無限に食べてしまう。もったいないので、できるだけ買わないで水をガブ飲みしてるけど、口が寂しい。
![]()
![]()
![]()
そういえば、ものすごくイライラしているときは掃除すると多少気が紛れる (やる気になった場合だけだけど)。すこし前にイライラしたときは、ひたすらトイレ掃除をしていた。
掃除には良い点がいくつかあって
一定の「満足感」は手に入ることがほぼ保証される。そんなものは他にあるか? ネトゲとかは瞬間的な満足感はあるが社会的には虚しい。掃除は同居家族がいるなら社会的な利益もある。
しかし、どういった種類のことでも「やらされている」と思った時点ですべての利点は失われる。他人のために働くということをすると、自分で満足するということがなくなる。成果評価の裁量を他人に奪われた時点で生きてる実感はなくなる。
![]()
![]()
![]()
少しでもストレスが解消されることがら
大きくストレスが溜まることがら
他人の道徳観に関するストレス (路上喫煙も同じ) は「こんなやつが社会でうまく生きてるのに、なぜおれは社会でこんなに否定されているのか」という感情に基いている。
![]()
![]()
![]()
![再発患者 [Blu-ray] - syrup16g](https://m.media-amazon.com/images/I/41kwBbi7K5L._SL500_.jpg)

