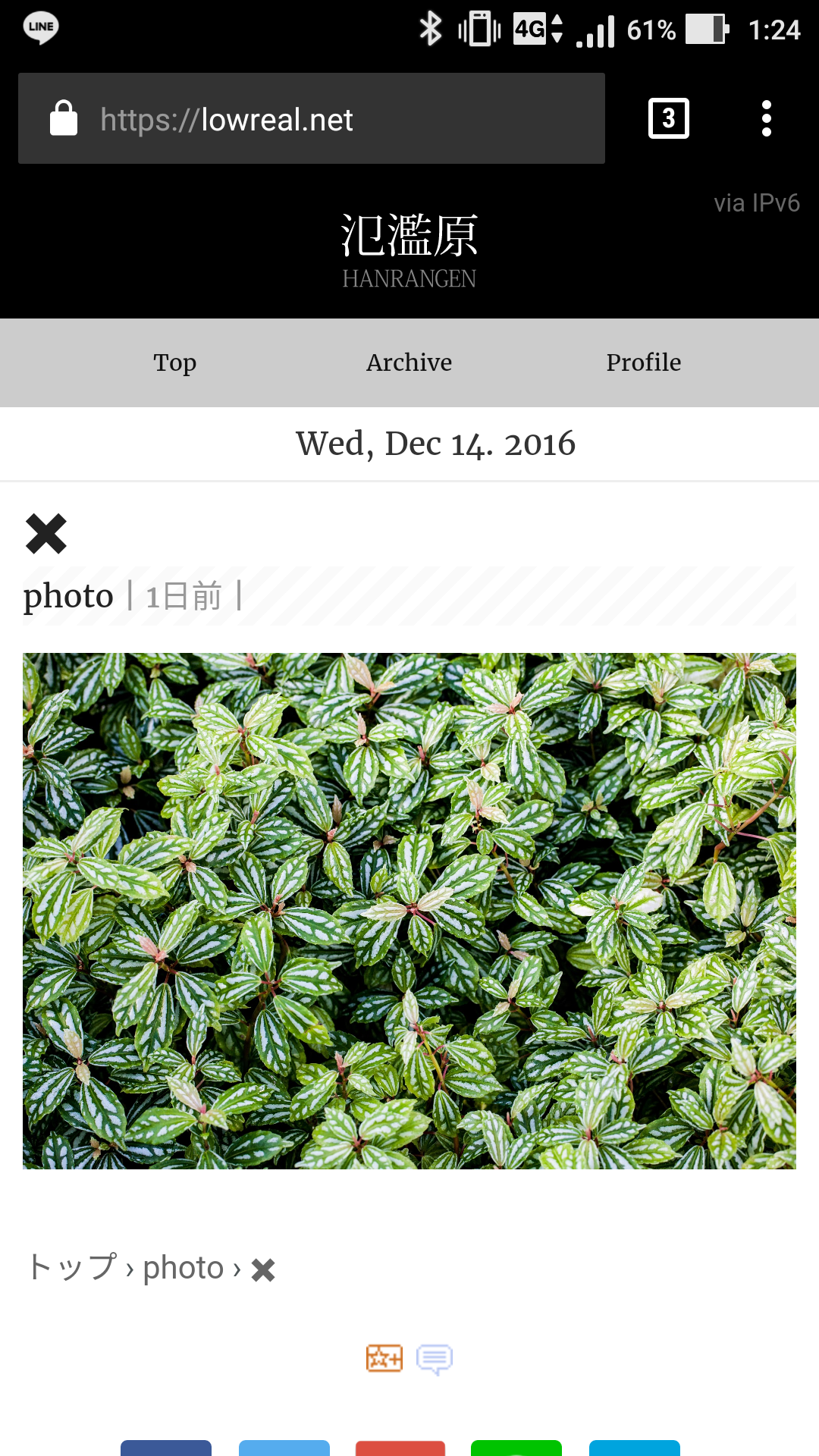
✖
![]()
![]()
![]()

![]()
![]()
![]()
花王の漂白剤シリーズに「ハイター」というのがあるが、種類がいっぱいあってよくわからない。というところだけど、実は公式のFAQに一覧があって、どのように成分が違うのかと用途が記載されている。
大きな違いは「界面活性剤」の有無になる。汎用性が高いのは含まれていないほうなので、とりあえず買うなら「ハイターE」「月星ブリーチC」あたり、「ハイターE」は一般向けだと「ハイター 衣料用漂白剤」になる。

なお基本的に「ハイター」には塩素系を期待すると思うが、酸素系の「ハイター」も存在しているので注意が必要。
消毒用途では基本的に10倍希薄して使うことになっている (商品は6%だが、塩素は揮発してしまうため 5% 扱いとする)。0.5%以上 (5000ppm) の濃度で使用しても消毒効果は上がらず、残ってしまう時間が長くなるだけなので、必ず守る。
なお次亜塩素酸ナトリウムが重宝される理由としては、蛋白質と接触すると食塩に変化するため残留リスクが低いことにある。
![]()
![]()
![]()
QAサイトで間違ったことが書いてあると、正解を書きたくなる心理を利用して、どんな回答にもまず間違った答えを機械が書くというのはどうか (あっててもいいけど)
![]()
![]()
![]()
![]()
![]()
![]()
さくらのVPSのウェブサーバでIPv6の接続をうける | tech - 氾濫原 で、IPv6 アクセス環境がないと書いたが、スマフォで簡単に IPv6 接続できることを知った。

IIJ mio の場合、APN の設定で IPv4/IPv6を選ぶだけで優先的に v6 接続されるようになる。
自力で確認できる環境が身近にあることがわかったので、このサーバでホストしているホストを IPv6 対応してみた (もとも IPv6 インターフェイスも listen してるので単に AAAA レコードをひけるようにしただけ)
見た目が何も変わらないのが正しい状態なのだけど、IPv6 接続されてるのかよくわからないので、仕掛けをしてみた。
判定は単に REMOTE_ADDR を見て、IPv6 アドレスだったら IPv6 接続と判定する。: を含んでいたら IPv6 と判定するようにする。
このサイトの場合、ページ全体をキャッシュしているため、内容をIPv4/IPv6で出しわけると持つべきキャッシュが倍になってしまい現実的ではない。ということで、以下のようにした。
![]()
![]()
![]()

郑州炜盛电子科技 という会社の MH-Z19 という CO2 センサを買ってみました。Aliexpress で $22 ぐらいでした。
5V の電源と 3.3V のインターフェイスが必要ですね。


Ruby 用のライブラリを書いて読みだして、GrowthForecast に投げてみました。Raspberry Pi 上で動かしています。シリアルは USB 経由で、PWM では GPIO 経由で読んでいます。
結構おもしろくて、人がいるかいないかはグラフから一目でわかるレベルです。換気するとそくざに値に反映されるのもおもしろいです。
Ruby で読み出し用のライブラリを書いてみました。
Serial 経由の読みこみとPWM (Linux のみ。sys/class/gpio 経由) どちらとも実装してあります。
Serial は仕様書通りに書いただけですが、PWM はちょっと工夫がいるのと、データシートそのままだとちゃんと値がでず試行錯誤したのでメモしておきます。
PWM はエッジトリガをしかけて時間をそこそこ正確に計測する必要があります。Linux の GPIO でやる方法がわからなかったので、ちょっと調べて以下のようにしました。
select でブロックしてエッジが検出されると制御が戻ります。read したあと seek で戻さないと、次の select でブロックせずビジーループになってしまうようでした。
def self.trigger(pin, edge, timeout=nil, &block)
self.direction(pin, :in)
self.edge(pin, edge) #=> write "/sys/class/gpio/gpio#{pin}/edge"
File.open("/sys/class/gpio/gpio#{pin}/value", "r") do |f|
fds = [f]
buf = " "
while true
rs, ws, es = IO.select(nil, nil, fds, timeout)
if es
f.sysread(1, buf)
block.call(buf.to_i)
f.sysseek(0)
else
break
end
end
end
end 処理速度が不安でしたが、1ms 単位でとれれば十分なので Ruby + /sys/class/gpio でも十分でした。
データシートだと以下の計算式になっています。ここで th は PWM の high の時間、tl は low の時間、ppm は CO2 濃度です。
ppm = 2000 * (th - 2e-3) / ((th + tl) - 4e-3) が、どうみてもデータシート通りの値がでてきませんでした。どうやら型番が一緒で、検出レンジが 0〜2000ppm のものと、0〜5000ppm のものがあるようで、2000 の部分を 5000 にするとうまく計算できました。
シリアル経由だと、ゼロ補正とスパン補正というのがあります。仕様書にどうやってキャリブレーションするか書いてないのですが、おそらく以下の手順です
↑ の手順おそらく間違いなので以下の正しいと思われる手順を書きます。MH-Z19B のデータシートの手順です。
まぁキャリブレーションは難しいのですが、一定期間内の最低値を外気のCO2濃度 (約400ppm) とみなしてときどき自動で補正していく方法もあるようです。
気象庁の二酸化炭素濃度のグラフを見る限り、近年は 400ppm 程度のようです。季節変動もみられますが、センサーの精度よりも小さいので無視できます。
ビル衛生管理上では 1000ppm を目安に換気せよと書いてあります。これは二酸化炭素の影響だけではなくて、これを目安として他の有害物質の滞留を防ぐという意味合いもあるみたいです。
また CO2 単体でも 2000ppm以上になると自覚できる症状が現れることがあるようです。
![]()
![]()
![]()
![]()
![]()
![]()
internal がデフォルトで、特に問題もないしずっとこれにしていたが、h2o が再起動されるたびにキャッシュが消えるのではないか? どうせ memcached も起動してるのでそっちにストアすべきではないか? と思いはじめたので変えてみた。
まぁ弱小ウェブサイトだとそもそも resumption かかるようなことがぜんぜんないので意味ない。Google Bot も分散アクセスのせいか全く resumption しないし。
![]()
![]()
![]()
最近子どもがとなりのトトロにハマってて毎日見てるんだけど、今朝は「お父さん」と「お母さん」が病院で会話しているシーンを見て、「星野源みたいねぇ」「ガッキーみたいねぇ」とか言いだして笑った。メガネかけてると星野源みたいねぇと言うのはしばしばあるんだけど、さらに「ガッキーみたいねぇ」は初めて聞いた。
最近は直接見てないはずなので (というか親が見ようとすると嫌がる)、結構前のを覚えているようだ。
![]()
![]()
![]()
![]()
![]()
![]()
↑ の写真 webp で Google Photos にアップロードしたんだけど、Chrome で見ても jpeg でしか配信されない。うーん…… いまいち webp 配信の条件がわからない。
Google Photos 上のサムネとかは webp になってるけど、大きめの画像は jpeg 固定なんだろうか
![]()
![]()
![]()
homebrew で入れる。
$ brew install libtiff $ brew install --HEAD webp
~/Library/Application Support/Adobe/Lightroom/Export Actions
にスクリプトを置くと、書き出しダイアログで選べるようになる。書き出したあとスクリプトの引数に現像済みファイル名が渡されるので、これを処理するようにすればよい。
以下のようなファイルを webp.rb という名前で Export Actions フォルダに保存して実行属性をつけておく。
#!/usr/bin/env ruby
require 'logger'
logger = Logger.new('/tmp/webplog')
logger.info ARGV.inspect
begin
ARGV.each do |f|
dir = File.dirname(f)
out = File.join(dir, File.basename(f, ".tif") + '.webp')
logger.info "%s => %s" % [f, out]
IO.popen([
'/usr/local/bin/cwebp',
'-metadata', 'all',
'-preset', 'photo',
'-q', '90',
'-o', out,
'--',
f
], :err=>[:child, :out]) do |io|
while l = io.gets
logger.info l.chomp
end
end
end
rescue Exception => e
logger.fatal e.inspect
end ファイル設定
として
「後処理」で「webp」を選ぶ
で書きだし。
EXIF が消える。cwebp が TIFF の EXIF デコードに非対応のため
![]()
![]()
![]()
リバースプロキシとして使っている h2o で
proxy.reverse.url: http://localhost:5001/
みたいに書いていたら確率的に connection failure がでて悩んだ。結局
proxy.reverse.url: http://127.0.0.1:5001/
で解決
/etc/hosts に ::1 localhost のエントリ(IPv6)があり、h2o は解決したアドレスのうちからランダムに1つ選択するため。プロキシ先のバックエンドサーバは IPv6 を bind しておらず、::1 が選択された場合に接続に失敗していた。
![]()
![]()
![]()
start_server が listen してないポートは以下のようなエラーになる。
cp socket:(null):80 is not being bound to the server
h2o は SIGHUP で graceful restart が可能だが、listen するポートが変わった場合は実際にlistenしている親プロセス (start_server プロセス) の再起動が必要になる。
![]()
![]()
![]()
これまで HTTPS (443) だけ h2o で処理していたが、nginx に使ってるぶんのメモリ量がMOTTAINAIのでh2oだけでやるようにした。さようなら nginx。
複雑なことをしているホストは全くなかったので普通に書きかえていっただけ
![]()
![]()
![]()
最初からアドレスついてたので意外とやることない。
ifconfig すると既に v6 のアドレスがついている。Scope:Global になっているやつがグローバルIPアドレス (正確にはグローバルユニキャストアドレス)
inet6 addr: 2001:e42:102:1807:160:16:210:51/64 Scope:Global
これを該当ドメインの AAAA レコードでひけるようにする。
nginx -V の結果に --with-ipv6 があることを確認する。
server {
listen 80;
listen [::]:80;
...
} という感じにして ipv6 側もlistenするようにする。
listen: 80 と書いてる場合、デフォルトで v6 も listen するようになっているのでやることはない。
ここでの「DNS サーバの IPv6 対応」はDNS サーバへの通信が IPv6 でできるかという話になるが、value-domain の NS1.VALUE-DOMAIN.COM とか、さくらインターネットの ns1.dns.ne.jp は対応していないっぽい?
IPv4 で解決できるなら別に問題ないんだけど、IPv6 オンリーの環境 (あるの?) からだと名前がひけないことになる。
自分に IPv6 アクセス環境がないので、とりあえず1つのドメインだけ対応させた。現状ではとくに IPv6 の対応したからといってメリットがないのが微妙。。。
![]()
![]()
![]()
人と人とは利害が一致する部分と一致しない部分があり、ある言葉を受けとるときにバイアスを補正して受けとる必要がある。自分にとって無意味なことでいちいち気が乱されるようなことを避けるために、相手のポジションと自分のポジションによって生じるバイアスは補正して理解しないといけない。インターネットは大変いろんな立場の人がいるため、いちいち全部の話を真面目に聞いてるとアホになる。
向いてる方向性が一緒なら議論可能なので、素直に意見をもってよい。
このとき必要なのは議論ではなくて交渉なので、議論をもとめられても適当にやっておけば良く、話真剣に受け止める必要はない。
なお経営者対従業員的な文脈だと、経営系の人はこういうことを言うと渋い顔をするので、あくまで「経営者視点を持ってます(キリッ」ってことにして真面目に聞いているフリをしておくこと。
お互いの利害を直交のベクトルとして合成したときの大きさによって、どれぐらい真剣に聞くかを決めたらいい気がする。二項対立というよりは、どのぐらい話を真剣に聞くべきかというアナログ値を感じたほうがよい。
![]()
![]()
![]()
どのぐらいまで生きていられるのか気になったので試してみる。wrk を使う (ab だとうまく高負荷にできなかった) wrk は brew で入る。
ベンチの際いくつか注意する
$ wrk -c 170 -d 10s -t 16 https://...
Running 10s test @ https://...
16 threads and 170 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 164.27ms 64.53ms 852.22ms 80.26%
Req/Sec 61.56 22.99 170.00 72.60%
9278 requests in 10.10s, 44.31MB read
Non-2xx or 3xx responses: 22
Requests/sec: 918.52
Transfer/sec: 4.39MB 日記システムは、これぐらいでCPUは使いきってちょいちょいエラーが発生する感じだった。
ヤフー砲が瞬間最大で100req/sec、継続的に30req/secぐらいらしいので、現実的にはこの日記が負荷で死ぬことはまずなさそう。他のサービスも同居してて相互に影響してる(バックエンドプロセスのワーカーを共有してる)けど。
![]()
![]()
![]()
サーバ移行のタイミングでつかいはじめた。監視をちゃんとするようにしようという感じ。loadavg5 と filesystem でひとまず監視。メトリクスの保存とグラフ化はフリープランだと1日だけなのであまり重視してない。
しかし、さくらのVPSはホスト不具合で落ちるってことは滅多にないので、やりたいことはサーバ自体の死活というよりウェブサーバの監視になる。このへんはプラグインでごにょごにょやってみている。パフォーマンス(応答時間のパーセンタイル値とか)とエラー数あたりでアラートが出せればいいかなという感じ。
![]()
![]()
![]()
高誘電体 MLCC は容量が時間経過で減少していくが、約125度(キュリー温度)まで加熱すると容量が回復する特性がある、らしい。
エージングで容量が減っていくというのはいいとして、一定より温度をあげると回復するというのを知らなかったのでびっくりした。
PS3/PS4 の修理方法でとにかくホットブローするみたいなのがあるけど、はんだクラックだけではなくて容量回復するという意味合いもあるのだろうか。
![]()
![]()
![]()
welq 問題でいろいろ思うところがあるけど、最終的にこれは「国会議員バカばっかり問題」と一緒ということなのだなと思って、解決にはほど遠いので気が重くなった。
「国会議員バカばっかり」って思うんだけど、あれは有権者が求めて選ばれた存在なわけで、こう思うということは有権者バカばっかりと思うに等しい。
検索エンジンの結果って、人々が求めるもののランクを上げた結果なので、その結果がバカなのって、結局人間がバカってことなんだよなあと思う。検索エンジンは人知を超えて賢くあるべきか?そして教育的であるべきか?はたしてそんな人工知能はバカな人間に受け入れられるのか (ビジネスになるのか)。
![]()
![]()
![]()
ネトゲって最初からエンドコンテンツなので、スキル上げとかが途方もない。とはいえゲームなのでやってればいつか終わるぐらいのバランスにはなっている。結果僕らは学ぶことができる、時間をかければあらゆるタスクは必ず終わる。さらにネトゲに飽きて失った時間に気付いたときにもう一つ学ぶことができる。人生は有限であること。
![]()
![]()
![]()
さくらのVPSにMongo Rescueのリストアができなかった (未解決) | tech - 氾濫原 の続きで、結局クリーンインストールした。さっき DNS を切り替えたので様子見。一応 DNS の TTL 時間はとっくにすぎたので、変な BOT 以外はいまのところ旧サーバにアクセスない。
どうやったかのメモはまた別にかく
一通り移行できたつもりだけど、元々雑多なサーバ内容かつ長期運用していたのでよくわからない。外形監視を自宅 Raspi からやっておくべきだったかなあ。
プランは東京 2GB SSD にした。前がだいぶ古い大阪 1GB HDD プランだったので SSH で繋いで体感できるぐらいパフォーマンスあがった。ウェブ側も早くなってて Google からの評価があがるといいんだけどな〜
![]()
![]()
![]()
![]()
![]()
![]()
カスタムOSインストールガイド - Ubuntu 16.04 – さくらのサポート情報 を見ながらインストールまでやる。
旧サーバと同じホスト名にしてDNSをふりかえたいが、DNS やホスト名まわりは最後にやる。
手元からまず copy-id
$ ssh-copy-id user@ufhostname
リモートの設定をかえる
$ sudo vi /etc/ssh/sshd_config PasswordAuthentication no PermitRootLogin no UsePAM no $ sudo /etc/init.d/ssh restart # 別のターミナルを開いて ssh できることを再度確認
ssh, http, https と mosh 用の udp ポートをあけておく (該当するソフトウェアをインストールすると勝手に空いたりするのだが念のため)
sudo ufw default deny sudo ufw allow 80 sudo ufw allow 443 sudo ufw allow 22 sudo ufw allow 60000:61000/udp sudo ufw enable
sudo apt-get install zsh gcc libncurses5-dev language-pack-ja git daemontools daemontools-run mysql-server ca-certificates cpio curl dnsutils imagemagick imagemagick-common irssi libcairo2-dev libcurl4-openssl-dev mime-support nginx nginx-common nginx-full ntp ntpdate optipng pkg-config rsync shared-mime-info w3m wget xz-utils xml-core zip libxml2-dev libtiff5-dev libssl-dev libsqlite3-dev libreadline-dev libpng12-dev libpango1.0-dev libopenjpeg-dev libmysqlclient-dev libjpeg8-dev libgif-dev libfreetype6-dev libffi-dev cmake screen ruby-dev rrdtool libdb-dev postfix unattended-upgrades
sudo ln -s /etc/service /service
home ディレクトリごとまるごと移す
一時的に sudo で rsync をつかえるようにする
$ sudo vi /etc/sudoers.d/rsync Defaults env_keep += "SSH_AUTH_SOCK" Defaults!/usr/bin/rsync !requiretty cho45 ALL=(ALL) NOPASSWD: /usr/bin/rsync ||< >|| ## dry-run sudo rsync --dry-run -auvz -e 'ssh -i /home/cho45/.ssh/id_ecdsa' --rsync-path='sudo rsync' --progress /home/cho45/ cho45@160.16.210.51:/home/cho45/
/srv /etc/nginx /etc/postfix # /etc/mysql 変更点がなかった。。。あらためて見直そう /etc/letsencrypt # /var/lib/mysql mysqldump でやった # /service 手動でやる
意外とうつすのない?
git の HEAD を入れてるので再度コンパイルして /usr/local にインストール
cd ~/project/h2o git clean -f cmake -DWITH_BUNDLED_SSL=on . make sudo make install
ログファイルを /var/log/h2o に作るようにしてるが前もってディレクトリがないとしぬ
sudo mkdir /var/log/h2o
/var/log/h2o/*.log {
daily
missingok
rotate 90
compress
delaycompress
notifempty
create 0640 www-data adm
sharedscripts
postrotate
svc -h /service/h2o
endscript
} 5.14.4 が gcc の関係?で入らなかったので、これを期に 5.22.2 に移行
perlbrew install perl-5.22.2 --as perl-5.22
前のマシンで perlbrew list-modules した結果を保存して cpanm にくわせてインストール。入らないやつが無視されるので、完全ではないがだいたい入る。
5.22 で動かなくなったコードを地味に修正したりした。
db ファイルだけ rsync したらいけるだろと思ったけど割といけなかったので、dump して restore する。mysql 自体のバージョンもあがってるのでまぁこのほうがよさそう。
mysqldump -uroot --routines --all-databases --flush-privileges | ssh cho45@160.16.210.51 'mysql -uroot'
たいしてデータ入ってないので一瞬。--routines でユーザテーブルもコピーしている。 --flush-privileges をつけないとコピーしたユーザデータが反映されないのでつけとく。
160.16.210.51 www.lowreal.net 160.16.210.51 lowreal.net 160.16.210.51 cho45.stfuawsc.com 160.16.210.51 coqso.lab.lowreal.net 160.16.210.51 no-real.net 160.16.210.51 block.lab.lowreal.net
みたいなのを /etc/hosts に書いて検証。証明書も転送して設定済みなので DNS だけ書きかえればうごいてくれるという感じのはず。。
DNS の向き先を新サーバに向ける
さくらのVPSはA レコードがひけてないと逆引き設定がつくれないので、Aレコードが適用されたあとにやる。
/etc/hostname も変える。
ここまでやったら一旦リブート。30秒ぐらいで起動するのでたすかる……
旧サーバからぬいてくる
crontab -l > crontab.user sudo crontab -l > crontab.root
新サーバに適用する
crontab crontab.user sudo crontab crontab.root
/etc/sysctl.conf に追記
net.core.somaxconn = 50000 net.ipv4.tcp_max_syn_backlog = 30000 net.core.netdev_max_backlog = 5000 net.ipv4.ip_local_port_range= 1024 65535
sudo sysctl -p で反映
![]()
![]()
![]()
これだけ買った。本当はおむつが欲しいんだけど、欲しいブランドのものがなかった…
定期便でも頼んでるけど、定期便で頼んでいると在庫確認に無頓着になりがちで
の二択になる。適切な配達間隔を設定すること自体が難しい。定期便自体が月イチの決まった日付前後の配達になるので「なくなりそうだから頼もう」と思ったタイミングだと時既に遅しということがある。
結局
のいずれかになる。
おむつの場合ストックがものすごい邪魔なので、多めに頼むってのが難しい。それと成長にともなって商品変更を迫られるので、そもそも大量に買いたくない。おかげで、なくなりそうになったらプライムで追加発送とか、近くのドラッグストアで買うみたいな運用になる。
Dash Button だと「足りない」と気付いたときにすぐ買うという場合は便利そう。そして物理ボタンなので家族で共有して押せるというところが便利。洗剤とかだと気付いた人が詰めかえるという運用なので「なくなったから買って」「忘れてた」「はやく買って」「カートにはいれた」みたいなことが発生してめんどうくさい。
ただし「もうすぐ定期便で届くし、それまでは在庫持つよ」というケースでも発注してしまうことが予想できてちょっとむずい。
![]()
![]()
![]()
キャッシュの持ちかたを変えて、圧縮 (gzip) して持つように変えた。キャッシュを返すときは gzip ずみのをそのまま返すように。
gzip 非対応ブラウザでおかしくなる気がするけど、昨今そんなブラウザは聞いたことがないので現実的には問題なかろうという気がする。
これによりキャッシュ用のDBファイル(SQLite)のサイズが劇的に減ったので、ファイルキャッシュに乗りやすくなったはず……
![]()
![]()
![]()
誤り訂正や、超解像技術みたいなのを前提とした圧縮方法に興味がある。なんとなく面白い感じがする。本来存在していたデータを意図的に削って送って、受取側の「経験」みたいなものを信用する感じが面白い。
画像圧縮も、CPU速度と帯域を比べたときに帯域で律速されるぐらいに高解像度になると、ディープラーニングによる高解像度化や、自動色付けを前提とした画像圧縮アルゴリズムが産まれても不思議ではない。
つまりこれは「おい」と言うとお茶がでてくるみたいなシステム。これがコンピュータで実現すると面白い。送信側の「意図」みたいなものを最大限推論してデータを復元し、転送データを最小限にできる。
![]()
![]()
![]()
前まで webp のアップロードはできなかった気がするんだけど、最近試したらできるようになっていた。
Google Photos はいつからかブラウザによって webp が落ちてくるように変わったけど、そのタイミングでアップロードも変わったのかな?
ちなみに JPEG 2000 や JPEG XR はあいかわらずアップロード不可能
![]()
![]()
![]()
いままでハマったことがなかったのだけど、ついにハマってしまった。
補助グループ権限もつけてくれるsetuidgidのようなもの - (ひ)メモ を読んで、どうするかな〜と思いつつsetusergroupsを試してみたが、Unix::Groups がデフォルトで入っておらずちょっと困ったので python で以下のようにした。
#!/usr/bin/python
import os
import sys
import pwd
if len(sys.argv) < 3:
print >> sys.stderr, 'Usage: setusergroups user program'
sys.exit(1)
pw = pwd.getpwnam(sys.argv[1])
pw_name = pw[0]
pw_uid = pw[2]
pw_gid = pw[3]
pw_home = pw[5]
os.environ['HOME'] = pw_home
os.initgroups(pw_name, pw_gid)
os.setgid(pw_gid)
os.setuid(pw_uid)
os.execvp(sys.argv[2], sys.argv[2:]) エラると例外で落ちてトレースバックがでて十分なので特にエラー処理してな
ハマったのは Raspberry Pi の pi ユーザで i2c を触るようなデーモンを作るケースで、この場合 pi ユーザに i2c グループ権限がついてないとダメなのでこういうのが必要になる。
依存なしでどうにかしたかったのは、cpanm が ansible の Core Modules に入ってなくてめんどかったから
![]()
![]()
![]()