✖










(batch_size, timesteps, features) が入力になる。batch_size はこのバッチ(学習・予測の1単位)中のサンプル数 (予測するデータの数) で stateless なら None (可変長) にできる、timesteps は与える時系列の長さ、features は特徴量。
features は 例えば1次元の波形データであれば 1 になる。3つのセンサーデータがある場合なら3になる。
timesteps は固定長にもできるし、可変長にもできる。可変長の場合は None を指定する。可変長といっても、単一バッチ中の timesteps の数は揃える必要がある。
timesteps を変えても RNN レイヤーのパラメータ数は変化しない。パラメータ数は features のサイズとRNNのユニット数に依存する。
stateless RNN の場合、RNN の内部状態はバッチごとにリセットされる。
1つのサンプルの出力は、与えた timesteps の数からしか影響されない。また、バッチ内の各サンプルは独立している。
例えば以下のような (3, 5, 1) なバッチを与えた場合、stateless RNN は、1つ目のサンプルに関しては [1, 2, 3, 4, 5] という情報をつかって 6 を予測するようになる。2つ目のサンプルも同様で、1つ目のサンプルとは内部状態が独立して (学習した重みはもちろん共有しているが) [ 2, 3, 4, 5, 6] から 7 を予測する。
# batch_input_shape = (3, 5, 1) 1 2 3 4 5 -> 6 2 3 4 5 6 -> 7 3 4 5 6 7 -> 8
stateful の場合は手動でリセットしない限り、バッチの最後の内部状態はリセットされない。
極端な例だと1回のバッチで timesteps が1というこもありうる。混乱しやすいのでサンプル数1で例を示してみる。
以下のように3回のバッチにわけてstateful RNNへ入力を与える。すべてサンプル数 (batch_size) は固定。timesteps の数は任意。stateless ではリセットしていたバッチ最後の各サンプルの最後の状態を保持しているので、batch #2 では、1つのtimestepsを与えているだけだが、それまでの timesteps である 1 2 3 4 5 も考慮された状態で予測される。
# batch #1 shape = (1, 5, 1) 1 2 3 4 5 -> 6 # batch #2 shape = (1, 1, 1) 6 -> 7 # batch #3 shape = (1, 2, 1) 7, 8-> 9
statelessで学習させて stateful に予測させるということもできる。これらの違いは内部状態をバッチ間で共有するかどうかだけなので、十分に長い系列で学習しているならあまり問題はない。この場合は、学習時に与えたステップ数しか考慮されていないが、連続で推論して新しい系列を得たいときはstateless より早く予測できる (途中の状態を保持したままなため再度過去の時系列を与える必要がない)。
stateful で学習させるのは結構めんどうくさいので、stateless で十分に長い時系列を与えて学習させて、リアルタイム予測などで実際に使うときは stateful にするというやりかたはありかもしれない。
意味がある予測ではないけど、試しにやってみた。
space = np.linspace(0, 1, 1000)
data = signal.square(2 * np.pi * 50 * space) * signal.square(2 * np.pi * 30 * space) / 2 + 0.5 こういう一時データをRNN(GRU)で学習させてみる。急激な値の変化があると学習結果が面白いことが多いので矩形波にしてる。

def create_model(batch_size=None, timesteps=None, stateful=False):
inputs = Input(batch_shape=(batch_size, None, 1))
x = inputs
x = GRU(32, stateful=stateful, return_sequences=False)(x)
x = Dense(1, activation='sigmoid')(x)
outputs = x
model = Model(inputs, outputs)
model.compile(optimizer=keras.optimizers.Adam(lr=0.01), loss='binary_crossentropy', metrics=['accuracy'])
return model
model = create_model(timesteps = 100)
model.summary()
gen = keras.preprocessing.sequence.TimeseriesGenerator(data[:-10].reshape( (len(data)-10), 1 ), data[10:], length=100)
model.fit_generator(gen, epochs=30, validation_data=gen, shuffle=False) 過去の状態から10ステップ先を1つ予測するという問題設定にした (特に問題に意味はない)
stateless でも stateful でも同じモデルを作れるようにして、まず stateless で学習させる。ここでは過去の系列は100ステップで学習させている。特に意味がある学習ではないので validation に同じ系列を指定してる。
tstart = time.time()
predict_len = 500
start = 207
result = []
for n in range(predict_len):
predicted = model.predict( data[start+n-100:start+n].reshape( (1, 100, 1) ) )
result.append(predicted[0])
result = np.array( result)
elapsed = time.time() - tstart
print('predict {}ms'.format(elapsed * 1000))
plt.figure(figsize=(10,10))
plt.subplot(211)
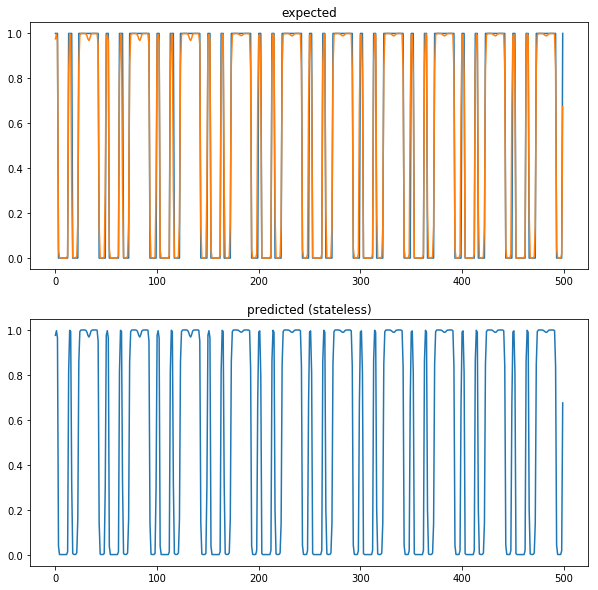
plt.title('expected')
plt.plot(data[start+10:start+500+10])
plt.plot(result)
plt.subplot(212)
plt.title('predicted (stateless)')
plt.plot(result)
plt.show()
result_stateless = result 後々、stateful とのコードと合わせるため一括で predict せずサンプル数1つで予測させてる。
一応一通り予測できている。ちなみに "predict 6278.290271759033ms" かかった。
model.save_weights('/tmp/param.hdf5')
model_stateful = create_model(batch_size = 1, stateful=True)
model_stateful.load_weights('/tmp/param.hdf5')
model_stateful.summary() weight を保存して、stateful=True にしたモデルに作りなおして weight をロードする。つまり stateless のモデルと weight は一緒の状態になる。
tstart = time.time()
start = 207
result = []
## preload same state with stateless
# model_stateful.predict( data[start-1-100:start-1].reshape( (1, 100, 1) ) )
for n in range(predict_len):
# give just new 1 timestep
predicted = model_stateful.predict( data[start+n-1:start+n].reshape( (1, 1, 1) ) )
result.append(predicted[0])
result = np.array( result)
elapsed = time.time() - tstart
print('predict {}ms'.format(elapsed * 1000))
plt.figure(figsize=(10,10))
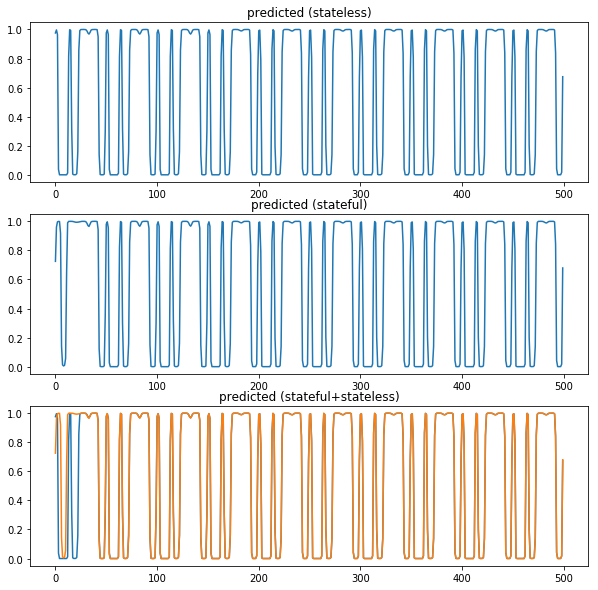
plt.subplot(311)
plt.title('predicted (stateless)')
plt.plot(result_stateless)
plt.subplot(312)
plt.title('predicted (stateful)')
plt.plot(result)
plt.subplot(313)
plt.title('predicted (stateful+stateless)')
plt.plot(result_stateless)
plt.plot(result)
plt.show() stateful では毎回1ステップだけ与えて予測させる。最初は過去の時系列がないため乱れているけど、ステップを与え続けると stateless と同じように予測できる。stateful でもコメンアウトしたところを実行すれば最初から stateless と全く同じ状態になる。
これは "predict 327.3053169250488ms" で終わる。
モノラルになるとかじゃなく、ステレオ入力すると、デフォルトではモノラル結合されて、同じデータが2チャンネルにコピーされて流れてくる。
echoCancelation が有効だとこういう挙動になるらしく、これを止めさせるとちゃんとステレオデータがとれる。getUserMedia で以下のように指定する。余計なことをできるだけ止めさせたい場合はいろいろ指定する必要がある。
const stream = await navigator.mediaDevices.getUserMedia({
audio: {
channelCount: {ideal: 2, min: 1},
echoCancellation: { exact: false },
noiseSuppression: { exact: false },
autoGainControl:{ exact: false },
}
}); Benchmark.js ちゃんと使えるので良いのですが、計測を頑張っている割に結果表示が貧弱というのが悲しいところです。
なので Perl の Benchmark.pm 風に表示する complete の関数を書いてみました。cli-table に依存します。
for x 115,102,309 ops/sec ±0.43% (95 runs sampled) for of x 62,020,029 ops/sec ±0.23% (96 runs sampled) Fastest is for +--------+-------------------------------+--------+-----------+ | name | ops | vs for | vs for of | +--------+-------------------------------+--------+-----------+ | for | 115102308.6ops/sec (+/-0.43%) | - | 86% | +--------+-------------------------------+--------+-----------+ | for of | 62020028.7ops/sec (+/-0.23%) | -46% | - | +--------+-------------------------------+--------+-----------+
//#!/usr/bin/env node
"use strict";
const Benchmark = require('benchmark');
const Table = require('cli-table');
const array = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
new Benchmark.Suite().
add('for', () => {
let sum = 0;
for (let i = 0, len = array.length; i < len; i++) {
sum += array[i];
}
return sum;
}).
add('for of', () => {
let sum = 0;
for (let i of array) {
sum += i;
}
return sum;
}).
on('cycle', function(event) {
console.log(String(event.target));
}).
on('complete', function() {
console.log('Fastest is ' + this.filter('fastest').map('name'));
const array = this.slice(0).sort( (a, b) => b.hz - a.hz);
const table = new Table({
chars: {
'top': '-' ,
'top-mid': '+' ,
'top-left': '+' ,
'top-right': '+',
'bottom': '-' ,
'bottom-mid': '+' ,
'bottom-left': '+' ,
'bottom-right': '+',
'left': '|' ,
'left-mid': '+' ,
'mid': '-' ,
'mid-mid': '+',
'right': '|' ,
'right-mid': '+' ,
'middle': '|'
},
head: ['name', 'ops'].concat( array.map( b => 'vs ' + b.name ) )
});
const comparison = array.map( (a, ia) => array.map( (b, ib) => {
if (ia === ib) return "-";
return Math.round((a.hz / b.hz - 1) * 100) + '%';
}));
array.forEach( (bench, i) => {
table.push([
bench.name,
`${bench.hz.toFixed(1)}ops/sec (+/-${bench.stats.rme.toFixed(2)}%)`
].concat(comparison[i]))
});
console.log(table.toString());
}).
run({});
https://developer.mozilla.org/ja/docs/WebAssembly/Rust_to_wasm に書いてある通りで便利。alert 出しても面白くないのでFFT のベンチをとってみるというのをやってみた。
タスクは N=4096 の複素数のFFTをやることとした。rust 側のコードは rustfftを呼ぶだけ。
以下のような組合せで実行
N = 4096 [wasm] instance pointer x 8,361 ops/sec ±0.23% (97 runs sampled) [wasm] instance wasm_bindgen x 7,869 ops/sec ±0.23% (99 runs sampled) [wasm] one func pointer x 2,730 ops/sec ±0.48% (95 runs sampled) [wasm] one func wasm_bindgen x 2,753 ops/sec ±0.34% (97 runs sampled) [js] instance dsp.js x 3,722 ops/sec ±0.74% (92 runs sampled) Fastest is [wasm] instance pointer +------------------------------+--------------------------+----------------------------+---------------------------------+-------------------------+---------------------------------+----------------------------+ | name | ops | vs [wasm] instance pointer | vs [wasm] instance wasm_bindgen | vs [js] instance dsp.js | vs [wasm] one func wasm_bindgen | vs [wasm] one func pointer | +------------------------------+--------------------------+----------------------------+---------------------------------+-------------------------+---------------------------------+----------------------------+ | [wasm] instance pointer | 8360.9ops/sec (+/-0.23%) | - | 6% | 125% | 204% | 206% | +------------------------------+--------------------------+----------------------------+---------------------------------+-------------------------+---------------------------------+----------------------------+ | [wasm] instance wasm_bindgen | 7869.3ops/sec (+/-0.23%) | -6% | - | 111% | 186% | 188% | +------------------------------+--------------------------+----------------------------+---------------------------------+-------------------------+---------------------------------+----------------------------+ | [js] instance dsp.js | 3721.9ops/sec (+/-0.74%) | -55% | -53% | - | 35% | 36% | +------------------------------+--------------------------+----------------------------+---------------------------------+-------------------------+---------------------------------+----------------------------+ | [wasm] one func wasm_bindgen | 2752.8ops/sec (+/-0.34%) | -67% | -65% | -26% | - | 1% | +------------------------------+--------------------------+----------------------------+---------------------------------+-------------------------+---------------------------------+----------------------------+ | [wasm] one func pointer | 2730.0ops/sec (+/-0.48%) | -67% | -65% | -27% | -1% | - | +------------------------------+--------------------------+----------------------------+---------------------------------+-------------------------+---------------------------------+----------------------------+
https://github.com/cho45/wasm-fft-sketch/blob/master/sketch.js#L174
とりあえず何も考えずに pure rust のライブラリをコンパイルして呼んでいるだけなのに、wasm 版が早い (rustfft が良いのかもしれないが)。
計算の比重が高いからか、意外とメモリコピーしてていても差がでない。
wasm_bindgen と wasm-pack が大変使い勝手が良く、ほぼ悩むことなく即 Rust のコードを書きはじめて、またそれをすぐに JS から呼ぶことができる。内部的には Rust 側のブリッジ関数と JS 側のブリッジ関数を同時に作ってくれている。
ただ、wasm はメモリ空間が JS のメモリ空間と分かれているため、wasm_bindgenが生成するJS側のブリッジ関数は (便利ではあるが) 若干非効率な実装になっており、TypedArray の受け渡しではコピーが多くなる。
これを防ぐには、やはり自力で wasm 側のメモリ空間からメモリを確保して TypedArray をインスタンス化して使用し、必要なくなったら free するという、メモリ管理を自分でやる必要がある。
これはまぁまぁ面倒くさいが、生成されたJSコードを読めばどう呼べば適切かは容易にわかるので、とりあえずは難しいことではない。
生成コードをただ使う場合、関数呼び出しだけなら生成コード内でメモリのfreeが行われるので、あまり気にする必要はないが、struct に関しては生成コードをただ使っている場合でも、明示的にオブジェクトの free を呼ぶ必要がある。JS にはデストラクタがないので仕方ないが、注意がいる。
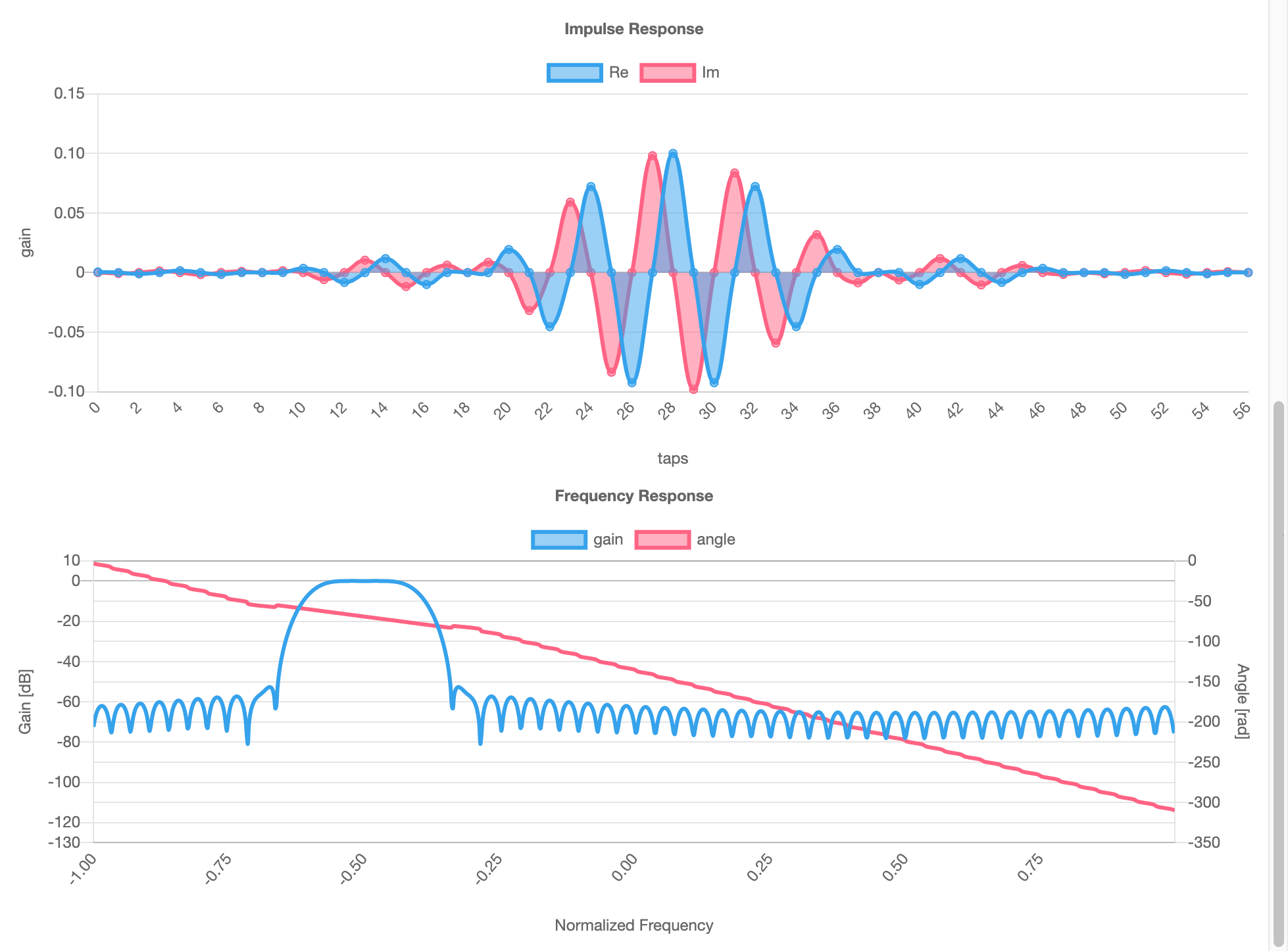
習作としてFIR (Finite Impulse Response) フィルタの可視化をつくってみた。
FIRフィルタのcoefficient(係数)をJSONで張りつけると、係数のグラフと、その周波数特性を表示する。複素数対応
https://github.com/cho45/complex-analyser-node
WebAudio の AnalyserNode は実数計算しかしないタイプ (仕様でそう決まっている) ですが、IQの2ch入力の信号を FFT して表示したいので、ほぼ類似のAPIを持つComplexAnalyserNodeを作ってみました。
簡単な割に IQ 信号を WebAudio で処理する際のデバッグに便利です。
FFT部分はwasmにコンパイルしたrustfftを呼んでおり、自分では実装していません。
AudioWorkletNode と AudioWorkletProcessor をうまく使いわける必要があるのですが、今回は以下のようにしています
こういう構成なので、wasm は普通にメインスレッドで読みこんでメインスレッドで使っています。Analyser の場合は audio スレッドで信号内容に手を加えるということはしないので、余計なことを audio スレッドでやらせたくないという気持ちがあります。
もともと WebAudio にある AnalyserNode とインターフェイスを似せようとすると同期的にしなくてはいけないので若干制約があります。全部非同期にすればもうちょいやりようがある気はします。
ComplexAnalyserNode (WebAudio) を作った (IQ信号のFFT) | tech - 氾濫原 に続き、WebAssembly を使って複素 FIR Filter を行う AudioWorkletNode の実装を書いてみた。前回と同様 Rust と wasm_bindgen を使っている。Rust 側の実装はとても素朴。
Analyser と違うのは、直接信号に手を加える必要があるというところ。つまり AudioWorklet 内で wasm の実装を呼ぶ必要がある。
wasm_bindgen の JS 側の実装は Uint8Array を文字列化するために TextEncoder を使っている。しかし TextEncoder は AudioWorkletGlobalScope には(今のところ)存在しておらず、エラーになってしまった。
自動生成されたコードに手を入れて使うのはあまりやりたくないのと、どっちにしろメモリ管理を自力でやる必要はあるので、wasm_bindgen の生成するJSコードは使わず、直接 wasm を呼びだすようにした。
なおエラーメッセージの転送などで、どうしても Uint8Array から文字列を生成したいケースはある。今回は ASCII 以外の文字が入ることは想定していないので TextEncoder の代わりに String.fromCharCode() でお茶を濁した。
AudioWorkletGlobalScope にはそもそも fetch もないため、wasm のコードを AudioWorkletGlobalScope 内で直接読みこんでインスタンス化することができない。
どうするかというと、メインスレッド(など)で fetch を行い、wasm のモジュールを得てから、これを postMessage で transfer するという余計な手順が必要になる。
wasm module は postMessage ができるが、wasm の instance はできないので、instance 化は AudioWorkletGlobalScope 側でやる必要がある。
無線機の出す I/Q 信号をサンプリングして 2ch (ステレオ) としてコンピュータに入力し、これを直接 WebAudio から扱って音声までデコードする。ソフトウェア側はブラウザだけで完結する。
実用レベルではないが SSB の復調まではできたので一旦記録しておく。
無線フロントエンド(アンテナや局発ミキサなどのハードウェア)が必要になるが、それは用意されていて、PCへの入力は2chのステレオマイク入力として行われているものとする。
自分の環境では KX3(無線機) のアナログ I/Q 出力を USB Audio Device のマイク入力に入れてサンプリングしている。
最初の要件を定義する。
シンプルにまずこれだけを目標にする。
SSB モードが実装できれば、単純に全く同じ実装で AM と CW もひとまず復調できるし、サイドバンドの選択ができるというところに信号処理の面白さがある (と今のところは思っている) ので、ちょうど良い目標だと思う。
無線フロントエンド側で、特定の周波数のcos/sinをそれぞれミックスした信号のこと。
例えば 7020kHz の cos/sin 信号をアンテナからのRF信号にミックスすると、7020kHz を 0Hz として周波数変換 (ヘテロダイン)される。cos波だけだと 7030kHz も 7010kHz も同様に 10Hz に周波数変換されてしまう (イメージがでる) が、直交位相 (sin波) でも周波数変換することで、負の周波数と正周波数の情報を信号処理で分けることができるようになる。
どちらのサイドバンドを復調するかはバンドパスフィルタの時点で選択して抽出する。その後適切に周波数変換して、real だけとれば音声として聞こえる。
音声信号はそこそこ流量があるので、print デバッグみたいなことは難しい。せっかく WebAudio なので、適時ブラウザ上に可視化しながら実装をすすめる。問題に気付きやすいし、なによりそのほうが楽しい。
https://lowreal.net/2019/07/17/1 に書いたが、実は最初にやると一番簡単なので、まずこれを実装しておく。
入力のIQ信号をそのまま複素数として扱い、FFT にかけるだけで良い。実数のFFTは出力の上半分を無視するが、複素数FFTの場合、出力の上半分は負の周波数領域の解析結果となっており、適切にシフトさえすれば難しいことなしにそのまま可視化できる。
複素バンドパス フィルター設計
- MATLAB & Simulink
- MathWorks 日本 この記事がわかりやすい。
これによって -nyquistFreq 〜 +nyquistFreq の任意の範囲を取り出すことができる。
既に複素数の信号をさらに周波数変換する。LO (ローカルオシレータ) 周波数の cos/sin を複素数で元の信号に乗算する。
複素ミキサーの良いところは原理的にはイメージが発生しないというところ。普通のミキサーでは LO に対して -LO と +LO の信号が発生するが、それがない。
周波数変換を経て ±n Hz 〜 0Hz の信号になっているので、real だけとって実数にする。これを出力すれば音声が出てくる。
GNU screen をずっと使っていたけど、なんとなく tmux に移行した。256色カラーとかがデフォルトで有効なのがとりあえず良いかな。
ずっと screen を使っていたといっても特に使いこなしまくっているわけではないので、普通に使う分には多少の設定でほぼ違和感なくすることができた。2重 tmux も大丈夫。
前に tmux いいよみたいな流行がでたとき移行しなかったのはなんか不愉快な人が使っていたからで特に tmux に罪はなかったが、そういう記憶も忘れたので、そろそろいいかという気がする。
GNU screen のとき定義していた cdd という、既に開いている別ウィンドウのディレクトリにcdするコマンドがあった(ref. cdd とお別れして、別の cdd を定義した | tech - 氾濫原 )。このままでは tmux で動かないので書きかえた。
function cdd() {
typeset -A mapping
local window=$1
mapping=($(tmux list-windows -F '#{window_index} #{pane_current_path}'))
local dir=$mapping[$window]
if [[ $dir == "" ]]; then
echo "window not found"
else
cd "$dir"
fi
} GNU screen のときはややトリッキーなことをしていたけど、tmux だとlist-windows の出力を工夫するとマッピングを直接得られるので、zsh の連想配列に入れてそのまま取得できた。(逆に、tmux だと環境変数にウィンドウ番号は入っていないので、screen のときの方法だとうまくできない)
今のところ自分は window 内を複数 pane に分割しないのでこれでうまくいくんだけど、分割すると結果が不定になりそう。
元々書いてた cdd は引数なしで実行するとリストを表示して選択して cd できるようにしていたけど、全く使わなかったので機能自体をなくした。
なぜか list-windows ではなく list-panes していたので、list-windows を使うように変更した
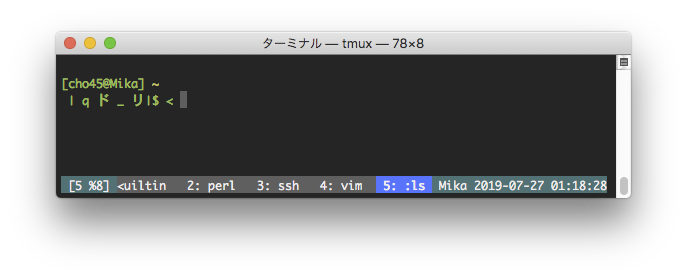
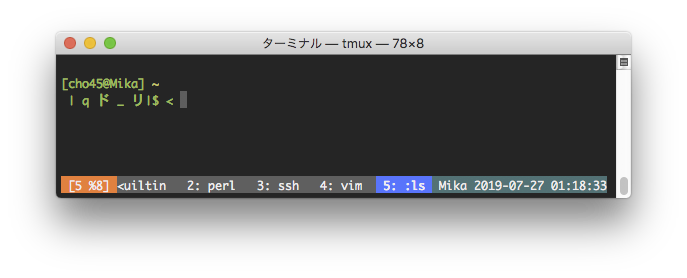
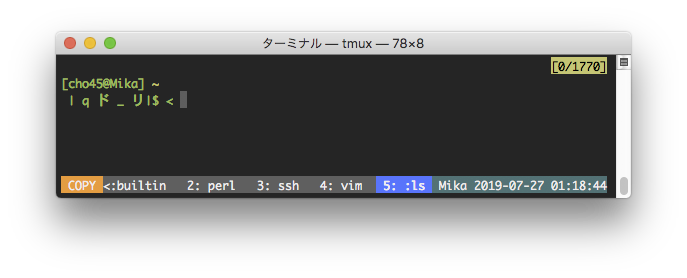
set-option -g status-left "#[fg=colour255,bg=colour23]#{?client_prefix,#[bg=colour202],}#{?#{==:#{pane_mode},copy-mode},#[bg=colour208] COPY , [#I #D] }" こんな感じで設定すると、通常は [4 %7] (4はwindow番号、%7はpane識別子)みたいになり、prefix 入力中は色が変化し、copy モードに入ると、さらに別の色で COPY という表示がでるようになる。
man tmux すると #{?foo,true,false} みたいな記法とか #{==:#{var},foo} みたいな記法について記述があり割と柔軟に設定できた。