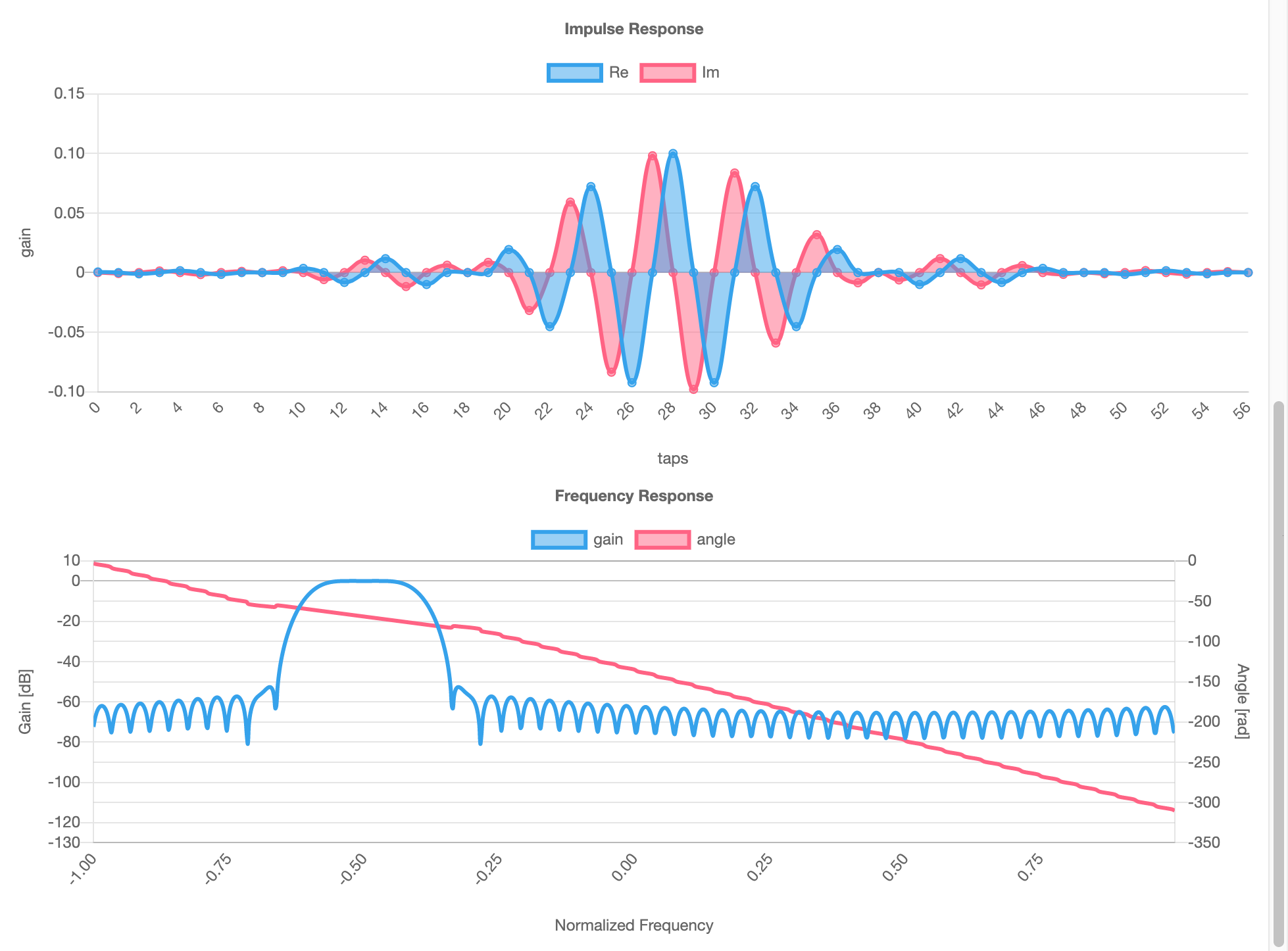
ComplexAnalyserNode (WebAudio) を作った (IQ信号のFFT) | tech - 氾濫原 に続き、WebAssembly を使って複素 FIR Filter を行う AudioWorkletNode の実装を書いてみた。前回と同様 Rust と wasm_bindgen を使っている。Rust 側の実装はとても素朴。
- https://github.com/cho45/complex-fir-filter-node/blob/master/complex-fir-filter-node.js
- https://github.com/cho45/complex-fir-filter-node/blob/master/src/lib.rs
Analyser と違うのは、直接信号に手を加える必要があるというところ。つまり AudioWorklet 内で wasm の実装を呼ぶ必要がある。
wasm_bindgen を使おうと思ったが…
wasm_bindgen の JS 側の実装は Uint8Array を文字列化するために TextEncoder を使っている。しかし TextEncoder は AudioWorkletGlobalScope には(今のところ)存在しておらず、エラーになってしまった。
自動生成されたコードに手を入れて使うのはあまりやりたくないのと、どっちにしろメモリ管理を自力でやる必要はあるので、wasm_bindgen の生成するJSコードは使わず、直接 wasm を呼びだすようにした。
なおエラーメッセージの転送などで、どうしても Uint8Array から文字列を生成したいケースはある。今回は ASCII 以外の文字が入ることは想定していないので TextEncoder の代わりに String.fromCharCode() でお茶を濁した。
wasm module を AudioWorkletGlobalScope に受け渡す
AudioWorkletGlobalScope にはそもそも fetch もないため、wasm のコードを AudioWorkletGlobalScope 内で直接読みこんでインスタンス化することができない。
どうするかというと、メインスレッド(など)で fetch を行い、wasm のモジュールを得てから、これを postMessage で transfer するという余計な手順が必要になる。
wasm module は postMessage ができるが、wasm の instance はできないので、instance 化は AudioWorkletGlobalScope 側でやる必要がある。