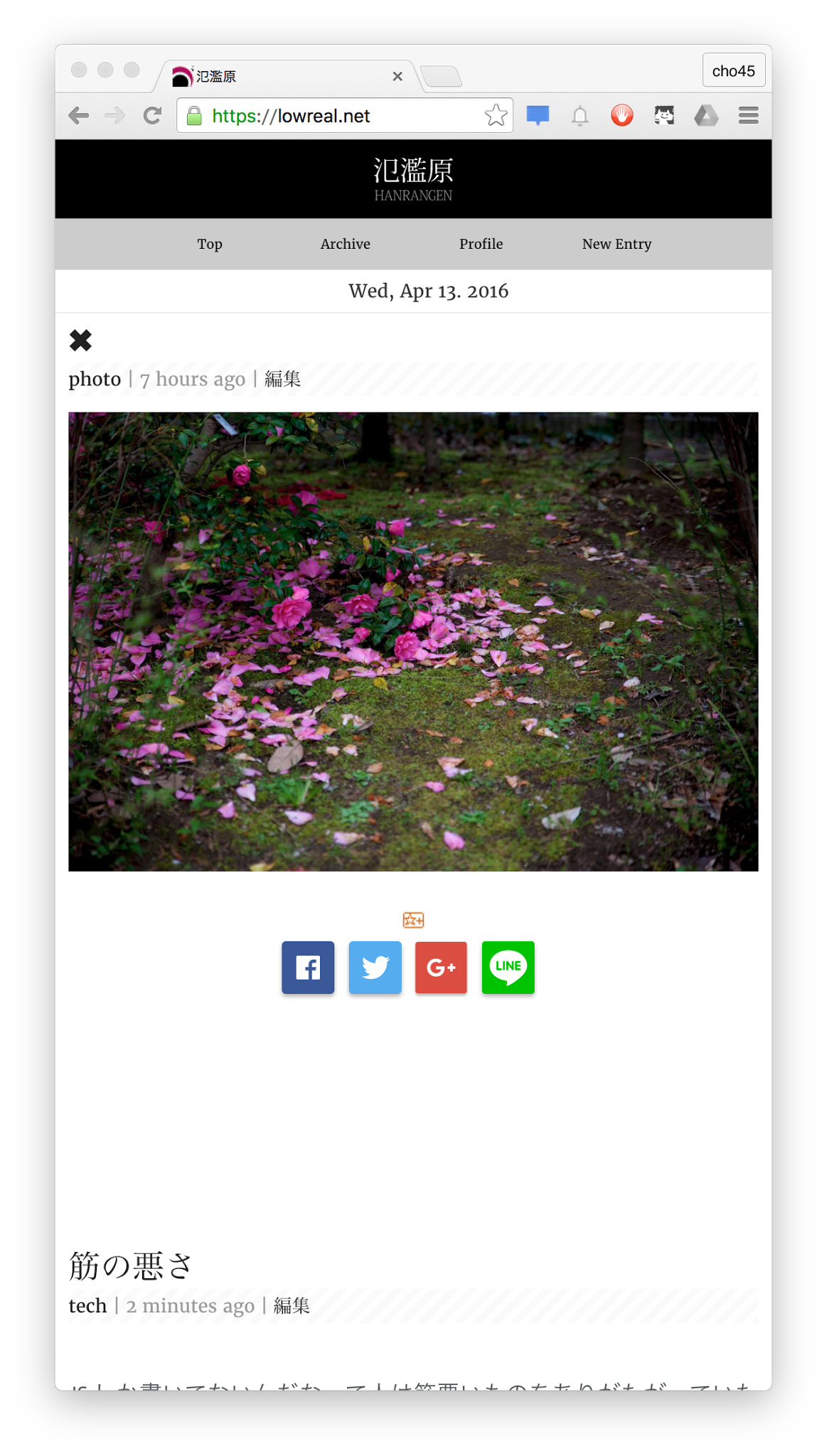
ひさしぶりに Chmertron をビルドしてみたら動かなくてつらい。codesign しなければフリーズしないんだけど、原因がわからない。
これのようだ。そのうち対策する https://github.com/electron/electron/issues/3871
ひさしぶりに Chmertron をビルドしてみたら動かなくてつらい。codesign しなければフリーズしないんだけど、原因がわからない。
これのようだ。そのうち対策する https://github.com/electron/electron/issues/3871
![]()
![]()
![]()
ES2015 の iterable protocol / iterator protocol だとそこそこ自然に無限リストを作れるわけなので、ちょっと試しにやってみました。node v5.2.0 で動かしました。
"use strict";
function* countup(n) {
for (;;) yield n++;
}
function* map(iterable, func) {
for (let value of iterable) {
yield func(value);
}
}
function* cycle(iterable) {
for (;;) {
for (let value of iterable) {
yield value;
}
}
}
function take(iterable, n) {
const ret = [];
for (let value of iterable) {
ret.push(value);
if (!(ret.length < n)) break;
}
return ret;
}
function* zip(iterable) {
for (;;) {
const nexts = [];
for (let it of iterable) {
nexts.push(it.next());
}
yield nexts.map( (i) => i.value);
if (nexts.some( (i) => i.done) ) break;
}
}
console.log(
take(
map(
zip([
countup(1),
cycle(["", "", "Fizz"]),
cycle(["", "", "", "", "Buzz"])
]),
(_) => _[1] + _[2] || _[0]
),
30
)
); FizzBuzz の map のところは destructive assignment ができるともうちょい綺麗に書けますが、現時点だとまだオプションが必要なのでキモい書きかたになりました。
protocol と言っている通り、next() を適切なインターフェイスで実装しているものは全て iterator なため、イテレータ全般に対して基底クラスみたいなものがありません。これはこれでいいんですが、不便な点があります。イテレータに対してメソッドの追加というのができません。
自分の中のオブジェクト指向の気持ちは以下のように書きたいのです。
[
countup(1),
cycle(["", "", "Fizz"]),
cycle(["", "", "", "", "Buzz"])
].
zip().
map( (_) => _[1] + _[2] || _[0] ).
take(30) しかし、イテレータの prototype というのは存在しないので、毎回必ず何らかの関数形式のラッパーが必要になってしまいます。
![]()
![]()
![]()
お葬式で酒・塩・鰹節
身内(配偶者の祖母)が亡くなったため、かなり久しぶりにお葬式という行事にあった。最中に気になったこととして、出棺前・納骨後に酒・塩・鰹節を使ったお清めがあった。具体的には、手を流水で清めたあと酒と塩と鰹節を口に含む。自分の祖父母は既に亡くなっているが、そういうことをした覚えがなかった。
特にいえば酒・塩はともかく、鰹節を使うイメージが全くなかった。鰹節というと、どちらかといえばおめでたいイメージがあるので、違和感を覚えたのだった。検索するとこの地域独自の文化らしいが、そもそも酒や塩も神饌と考えれば、さらに他にものがあってもおかしくはない気はしてきた。
![]()
![]()
![]()

殆ど子供の様子を書いてないが、育っている。最近の様子を書いておく
例えば
理解できてるはずのことを言っても無視することは多々ある。目があってても意図的に無視していることがある。
叱った直後に即座に「あーんあーん」と泣かないことがある。無表情か、泣くのを我慢しているような表情 (ないしは悔しそうな表情) をする。叱られてることはわかってるようだが、説明がわからないのかもしれない。
最後に「わかった?」「うん」「はいでしょ?」「はい」みたいなのを毎回やってる。これたぶんわかってないけど、これ以上確認する術がないし、やらないと話が終わらないので、どうすればいいかよくわからない。
あと叱るときはかなり真剣に叱らないとダメで、中途半端に叱るとニヤニヤしていて冗談だと思っている節がある。両手握って眼を見て叱るとすくなくとも真剣なのは伝わる模様。
泣くのを我慢しているような表情はあきらかに面白いんだけど、ここで笑うと気持ちが伝わらない(気がする)ので難しい。
言葉はそれほど話せない。2語出ることもあるが基本的には1語
もうすぐ2歳なので結構言い出している。「イヤ」ではなくて「あイヤ・あイヤ」という。謎。
あいかわらず食事のマナーは良くない。口に詰め込みまくって吐きだすことがある。詰め込むまえに「口の中にまだ入ってるよ」というと一応気付くみたいで、飲みこんでから口をあけて「ア!」と言ってもう中にないことを主張する。
薬飲むとき毎回ヨーグルトを使っているが、なぜかヨーグルトだけは毎日食べても飽きない(習慣と認識している?)みたいで素直に食べてくれる。
テレビがついていないときに、PS4 のコントローラを探し出して電源をつけていることがある。本人はそれ以上ちゃんと操作ができないので大人にコントローラを押し付けてくる。
大人が大人用の番組 (アニメを含む) を見ているとたいそう不満なようで、ひたすらワンワンワンワンと主張する。
「ないない (片付け)」も本人の気がのってればやってくれる。おもちゃの一部がないときは「これがないよ」というと、多少は探してくれる。
![]()
![]()
![]()
めっちゃ面白かった。
艦コレみたいなノリのアニメなのだと思って見ていなかったけど、とりあえず1話見てみるかと思った結果そういったものノリのものではないことがわかって、12話まで一気に見てしまった。その後OVA版を見てからもう一周見てしまった。
全体的には弱小高校が部活の全国大会で勝ち上がる王道スポコンみたいなストーリーだった。メインの部分を戦車道という架空の競技に置き換えた感じ。
演出がかっこいいとかいろいろあるけど、結局のところ主人公の徳が高いってのが良かった。
プライムビデオだと、テレビシリーズ12話とOVA1話(これが本当のアンツィオ戦です!)が見れる。OVAはテレビシシーズで飛ばされた試合。劇場版はまだ発売とかされない模様。
やたら人気?だから2期とかあるのかと思ったけど、これが全部みたい。

ガールズ&パンツァー cho45

![ガールズ&パンツァー 劇場版 [Blu-ray] - 渕上舞](https://m.media-amazon.com/images/I/61QuPEjbaOL._SL500_.jpg)
ガールズ&パンツァー 劇場版 [Blu-ray] cho45
![]()
![]()
![]()
そろそろやることなくなったので minify などをやることにしました。
ただ、ブログシステムの出力の最後ほうでページごとに全体を minify すると、全体としてどうしても処理に時間がかかってしまいます。要求として、キャッシュなしの状態からでも1エントリあたり0.1秒ぐらいでは処理したいので、これだと厳しい感じでした。(約7900エントリぐらいあるので、0.1s で処理しても全体のキャッシュ再構築に13分かかる計算です)
いろいろ考えたのですが (そもそも minify しないとかも)、以下のようにしました
minify には html-minifier を使っています。html-minifier はテンプレートを対象にした minify も一応サポートしていて、ある程度妥協すればテンプレート対象でも十分に minify できます。
テンプレートとエントリが前もってをminifyされていれば、あとは繋げて出すだけです。
このブログシステムのテンプレートは Text::Xslate::Syntax::TTerse です。
まず、Xslate のビュー読みこみをフックして、テンプレートを動的に minify するようにしました。
{
no warnings 'redefine';
*Text::Xslate::slurp_template = sub {
my ($self, $input_layer, $fullpath) = @_;
my $source = sub {
if (ref $fullpath eq 'SCALAR') {
return $$fullpath;
} else {
open my($source), '<' . $input_layer, $fullpath
or $self->_error("LoadError: Cannot open $fullpath for reading: $!");
local $/;
return scalar <$source>;
}
}->();
if ($fullpath =~ /\.html$/) {
$source = Nogag::Utils->minify($source);
return $source;
} else {
return $source;
}
};
$XSLATE->load_file($_) for qw{
index.html
_article.html
_adsense.html
_images.html
};
}; Xslate には pre_process_handler というのがあって、 読みこまれたテンプレートにフィルタをかけることができます。が、この機能だとファイル名がわからないので使っておらず、slurp_template を上書きしています。
(明示的に load_file しているのは、エラーが起きるなら起動時にしたいというのと、fork 前にロードすることでメモリの節約になるからで、本題とは関係ありません)
TTerse なテンプレートに対して html-minifier を使う場合、配慮する点がいくつかあります。
TTerse の場合以下のようにも書けますが、ダブルクオートの入れ子が HTML として見ると syntax error なので html-minifier で Parse Error になります。
<meta content="[% "foo" _ "bar" %]">
テンプレートの構文をタグに混ぜるには html-minifier 側にオプションを設定します (customAttrSurround)。
ただ、複数属性を囲うとうまく属性を分解できなくて死ぬっぽいので、個別に囲う必要がありました。
<!-- ダメ -->
<article
[% IF xxx %]
itemscope
itemprop="blogPosts"
[% END %]
> <!-- よろしい -->
<article
[% IF xxx %]itemscope[% END %]
[% IF xxx %]itemprop="blogPosts"[% END %]
> クラスをテンプレートで出しわけしていると死にます
TTerse 対応のためオプションは以下のようになりました。customAttrSurround が適切に設定されていれば、sortAttributes は true にしても問題ないようです。
function processMinify (html) {
return Promise.resolve(minify(html, {
html5: true,
customAttrSurround: [
[/\[%\s*(?:IF|UNLESS)\s+.+?\s*%\]/, /\[%\s*END\s*%\]/]
],
decodeEntities: true,
collapseBooleanAttributes: true,
collapseInlineTagWhitespace: true,
collapseWhitespace: true,
conservativeCollapse: true,
preserveLineBreaks: false,
minifyCSS: true,
minifyJS: true,
removeAttributeQuotes: true,
removeOptionalTags: true,
removeRedundantAttributes: true,
removeScriptTypeAttributes: true,
removeStyleLinkTypeAttributes: true,
processConditionalComments: true,
removeComments: true,
sortAttributes: true,
sortClassName: false,
useShortDoctype: true
}));
} エントリ保存時には、minify もそうですが、ほかにも修正を加えたいことが多々あります。例えば画像を強制的に https 化して mixed content を防ぎたいとか、コードハイライトを行いたいとかです。
コードハイライトは今まで highlight.js を使い、クライアントサイドでやっていました。これも本来ダイナミックにやる必要はなくポストプロセスでできることなので、そのように変えることにしました。highlight.js をサーバサイドで行うと、付与されるマークアップ分 HTML の転送量が増えますが、highlight.js 自体が結構大きいので、かなり長いコードをハイライトしない限り、サーバサイドでやったほうが得そうです。
以前サーバサイドでMathJaxを処理するようにしましたが、この node.js の内部向けサーバをさらに拡張して、JS でいろいろなポストプロセスの処理を書けるようにしました。
これにより、クライアントサイドでやってたことをそのままサーバサイドできるようになりました。すなわち、hightlight.js をそのままサーバサイドでも動かしていますし、jsdom を使って細かいHTMLの書きかえを querySelector など標準の DOM 操作でできるようにしています。
前述のように node.js で動くデーモンで、ブログシステム(Perl)とは別のプロセスで動き、APIサーバになっています。
全体的には以下のようなコードです。なお書き換え部分は変な挙動をするとやっかいなので、テストを書けるようにしてあります。
#!/usr/bin/env node
const jsdom = require("jsdom").jsdom;
const mjAPI = require("mathjax-node/lib/mj-page.js");
const hljs = require('highlight.js');
const minify = require('html-minifier').minify;
const http = require('http');
const https = require('https');
const url = require('url');
const vm = require('vm');
const HTTPS = {
GET : function (url) {
var body = '';
return new Promise( (resolve, reject) => {
https.get(
url,
(res) => {
res.on('data', function (chunk) {
body += chunk;
});
res.on('end', function() {
res.body = body;
resolve(res);
})
}
).on('error', reject);
});
}
};
mjAPI.start();
mjAPI.config({
tex2jax: {
inlineMath: [["\\(","\\)"]],
displayMath: [ ["$$", "$$"] ]
},
extensions: ["tex2jax.js"]
});
function processWithString (html) {
console.log('processWithString');
return Promise.resolve(html).
then(processMathJax).
then(processMinify);
}
function processWithDOM (html) {
console.log('processWithDOM');
var document = jsdom(undefined, {
features: {
FetchExternalResources: false,
ProcessExternalResources: false,
SkipExternalResources: /./
}
});
document.body.innerHTML = html;
var dom = document.body;
return Promise.resolve(dom).
then(processHighlight).
then(processImages).
then(processWidgets).
then( (dom) => dom.innerHTML );
}
function processHighlight (node) {
console.log('processHighlight');
var codes = node.querySelectorAll('pre.code');
for (var i = 0, it; (it = codes[i]); i++) {
if (/lang-(\S+)/.test(it.className)) {
console.log('highlightBlock', it);
hljs.highlightBlock(it);
}
}
return Promise.resolve(node);
}
function processImages (node) {
console.log('processImages');
{
var imgs = node.querySelectorAll('img[src*="googleusercontent"], img[src*="ggpht"]');
for (var i = 0, img; (img = imgs[i]); i++) {
img.src = img.src.
replace(/^http:/, 'https:').
replace(/\/s\d+\//g, '/s2048/');
}
}
{
var imgs = node.querySelectorAll('img[src*="cdn-ak.f.st-hatena.com"]');
for (var i = 0, img; (img = imgs[i]); i++) {
img.src = img.src.
replace(/^http:/, 'https:');
}
}
{
var imgs = node.querySelectorAll('img[src*="ecx.images-amazon.com"]');
for (var i = 0, img; (img = imgs[i]); i++) {
img.src = img.src.
replace(/^http:\/\/ecx\.images-amazon\.com/, 'https://images-na.ssl-images-amazon.com');
}
}
return Promise.resolve(node);
}
function processWidgets (node) {
var promises = [];
console.log('processWidgets');
var iframes = node.querySelectorAll('iframe[src*="www.youtube.com"]');
for (var i = 0, iframe; (iframe = iframes[i]); i++) {
iframe.src = iframe.src.replace(/^http:/, 'https:');
}
var scripts = node.getElementsByTagName('script');
for (var i = 0, it; (it = scripts[i]); i++) (function (it) {
if (!it.src) return;
if (it.src.match(new RegExp('https://gist.github.com/[^.]+?.js'))) {
var promise = HTTPS.GET(it.src).
then( (res) => {
var written = '';
vm.runInNewContext(res.body, {
document : {
write : function (str) {
written += str;
}
}
});
var div = node.ownerDocument.createElement('div');
div.innerHTML = written;
div.className = 'gist-github-com-js';
it.parentNode.replaceChild(div, it);
}).
catch( (e) => {
console.log(e);
});
promises.push(promise);
}
})(it);
return Promise.all(promises).then( () => {
return node;
});
}
function processMathJax (html) {
console.log('processMathJax');
if (!html.match(/\\\(|\$\$/)) {
return Promise.resolve(html);
}
return new Promise( (resolve, reject) => {
mjAPI.typeset({
html: html,
renderer: "SVG",
inputs: ["TeX"],
ex: 6,
width: 40
}, function (result) {
console.log('typeset done');
console.log(result);
resolve(result.html);
});
});
}
function processMinify (html) {
return Promise.resolve(minify(html, {
html5: true,
customAttrSurround: [
[/\[%\s*(?:IF|UNLESS)\s+.+?\s*%\]/, /\[%\s*END\s*%\]/]
],
decodeEntities: true,
collapseBooleanAttributes: true,
collapseInlineTagWhitespace: true,
collapseWhitespace: true,
conservativeCollapse: true,
preserveLineBreaks: false,
minifyCSS: true,
minifyJS: true,
removeAttributeQuotes: true,
removeOptionalTags: true,
removeRedundantAttributes: true,
removeScriptTypeAttributes: true,
removeStyleLinkTypeAttributes: true,
processConditionalComments: true,
removeComments: true,
sortAttributes: true,
sortClassName: false,
useShortDoctype: true
}));
}
const port = process.env['PORT'] || 13370
http.createServer(function (req, res) {
var html = '';
var location = url.parse(req.url, true);
req.on('readable', function () {
var chunk = req.read();
console.log('readable');
if (chunk) html += chunk.toString('utf8');
});
req.on('end', function() {
console.log('end');
if (location.query.minifyOnly) {
Promise.resolve(html).
then(processMinify).
then( (html) => {
console.log('done');
res.writeHead(200, {'Content-Type': 'text/plain; charset=utf-8'});
res.end(html);
}).
catch( (e) => {
console.log(e);
console.log(e.stack);
res.writeHead(500, {'Content-Type': 'text/plain; charset=utf-8'});
res.end(html);
});
} else {
Promise.resolve(html).
then(processWithDOM).
then(processWithString).
then( (html) => {
console.log('done');
res.writeHead(200, {'Content-Type': 'text/plain; charset=utf-8'});
res.end(html);
}).
catch( (e) => {
console.log(e);
console.log(e.stack);
res.writeHead(500, {'Content-Type': 'text/plain; charset=utf-8'});
res.end(html);
});
}
});
}).listen(port, '127.0.0.1');
console.log('Server running at http://127.0.0.1:' + port); 利用側は単純に http リクエストを送っているだけです。ときどきパースエラーで失敗したりするので、そういう場合は元々の HTML をそのまま使うようにしています。
という2段階のキャッシュがあります。テンプレートを変更しただけの場合、レンダリング結果のキャッシュを作りなおします。これは冒頭の通り約13分程度かかります。このページ単位のキャッシュはエントリを保存すると関連するキャッシュが自動的に無効になるようになっています。この場合、次回アクセス時に再生成になります。
記法フォーマッターのコード変更や、ポストプロセス処理に変更を入れた場合には、エントリのリフォーマットが必要です。これは全てやると約10分ぐらいかかります。ただ一部エントリだけにリフォーマットをかけるようなこともできるようにしています。
![]()
![]()
![]()
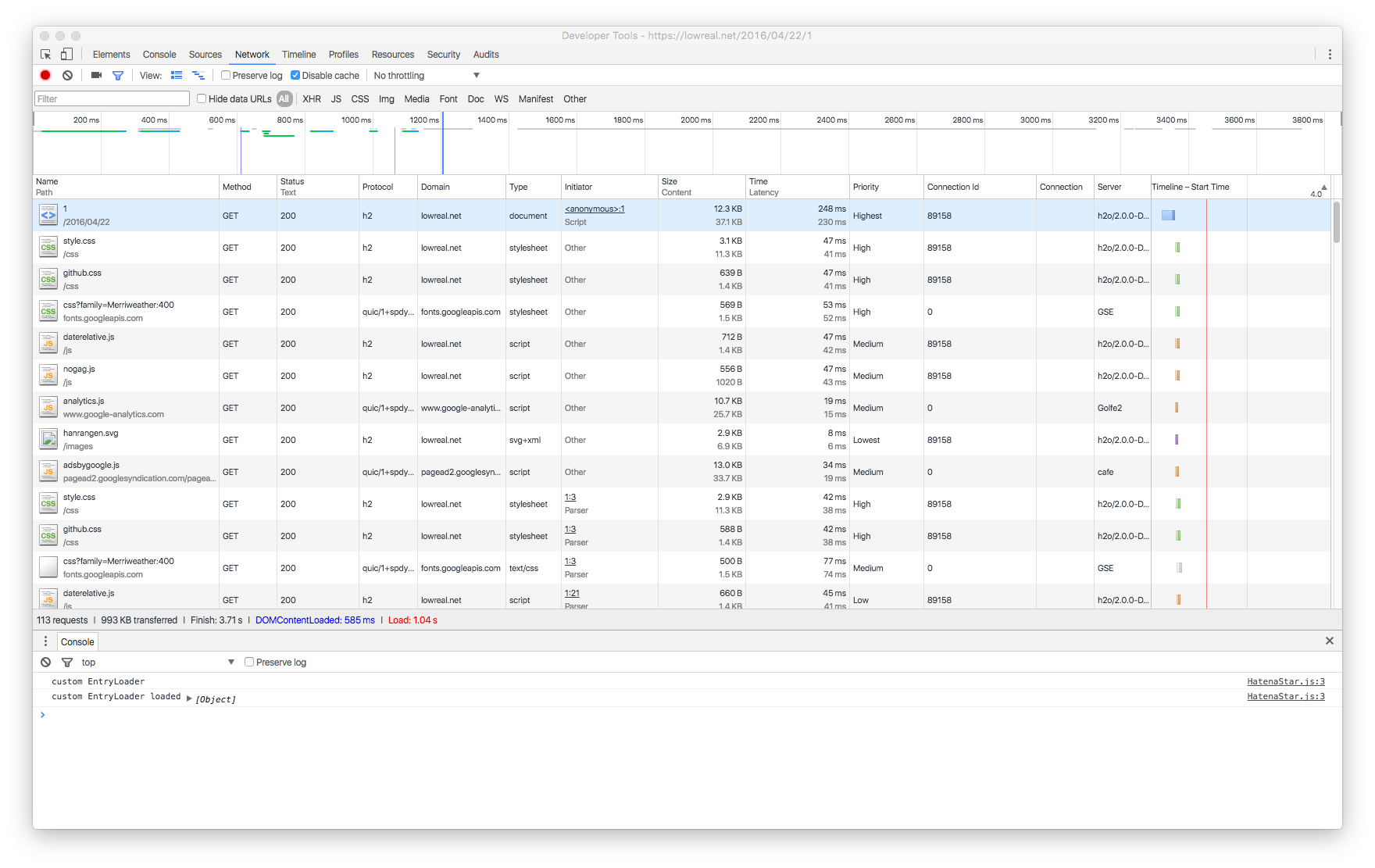
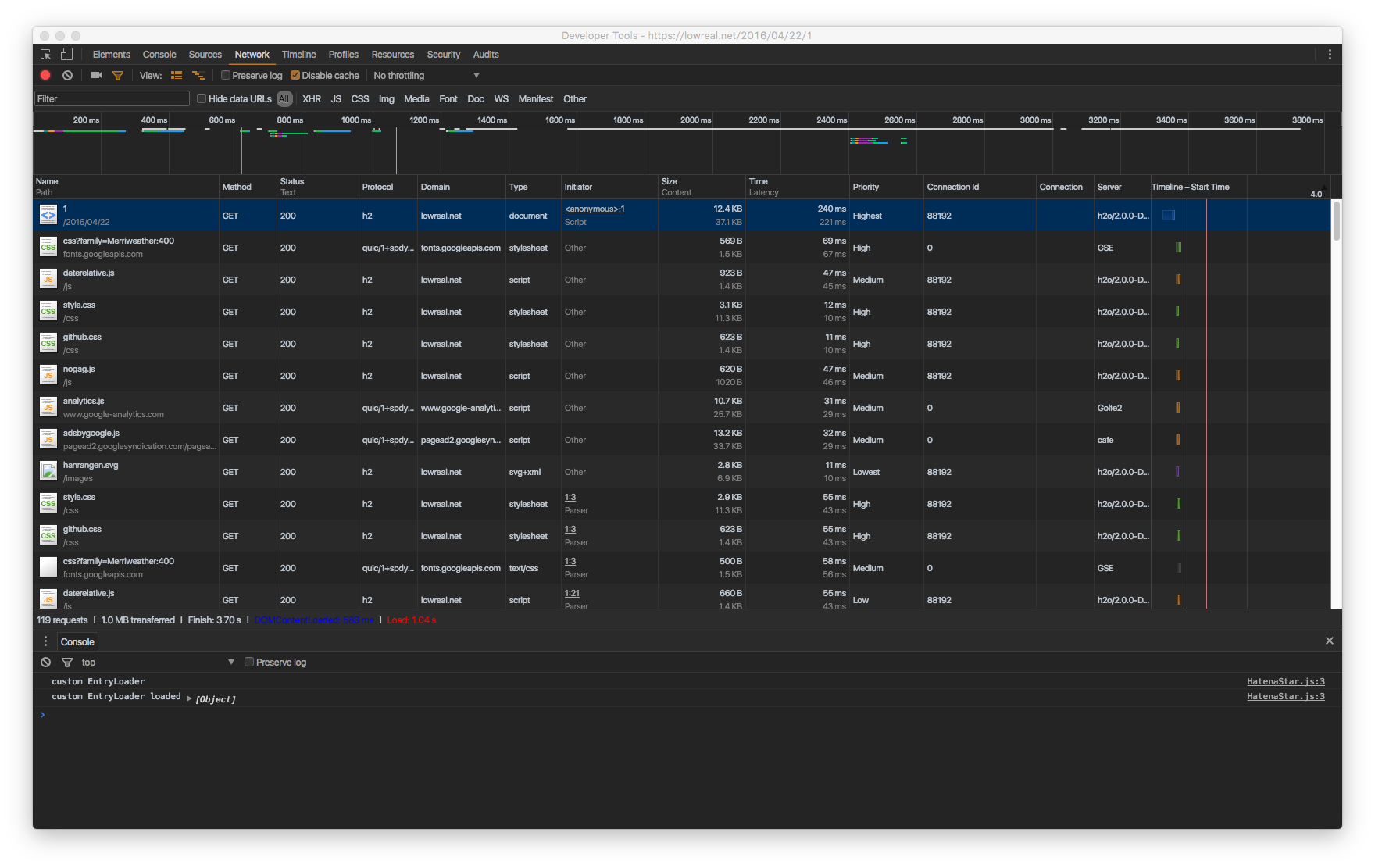
Default と Dark テーマの違い。お分かりいただけるだろうか……?
よく見ると Default のほうは、リソースの Timeline に DOMContentLoaded の線(青い線)がない。
今まで、なぜ表示されないんだろう? と疑問だったけど、Dark にしないと表示されないとは…… (バグじゃないか)
![]()
![]()
![]()
ほとんどのブラウザで、通常リロードは Cache-Control: max-age=0、スーパーリロードで Cache-Control: no-cache がリクエストヘッダとして送られてくるみたいなのですが、実際の挙動はともかく意味の違いがよくわかりませんでした。
RFC7234 によると max-age は
The "max-age" request directive indicates that the client is unwilling to accept a response whose age is greater than the specified number of seconds. Unless the max-stale request directive is also present, the client is not willing to accept a stale response.
no-cache は
The "no-cache" request directive indicates that a cache MUST NOT use a stored response to satisfy the request without successful validation on the origin server.
となっています。読んでも違いがよくわかりません。検索するとWhat's the difference between Cache-Control: max-age=0 and no-cache? あたりがヒットして、古いほうのRFC HTTP/1.1: Caching in HTTPが示されています。
max-age=0 は validate した結果最新とわかったならキャッシュを返すことを許しているが、no-cache はそもそも cache を使うことを許していない、という違いがあるようです。
もっというと、max-age=0 のときは validate して最新なら 304 を返してくれてもいいが、no-cache のときは validate すらせず全て 200 で転送しなおせという意味のようです。
レスポンス時の Cache-Control: no-cache が語感に反してキャッシュの利用を許可しているというのは良く知られている(?)と思いますが (キャッシュの利用を許可しないのは no-store)、これも max-age=0 との違いがよくわかってませんでした。
これについても上記の stackoverflow でわかりやすい解説があって、Cache-Control: no-cache は実質 Cache-Control: max-age=0, must-revalidate 相当だろうとのことでした。単純な max-age=0 はクライアント側が validate できなければ期限切れのキャッシュ利用を許しているという違いがあるようです。
![]()
![]()
![]()
Hardware IO Tools for Xcode をダウンロードすると Network Link Conditioner という環境設定が含まれていて、インストールするとそこそこ細かくネットワーク環境を再現できます。Xcode → Open Developer Tools → More Developer Tools… とたどるといろんなツールを検索できるページにいくので、そこからダウンロードしてこれます。
プリセットだと LTE っぽいプロファイルがないので、適当にカスタムプロファイルを作ってみました。Downlink/Uplink で別々に設定できることから、Delay はおそらく片道っぽいので、RTT / 2 を設定します。Bandwidth は各社の実効速度データのうち、下限付近を参考に設定しました。
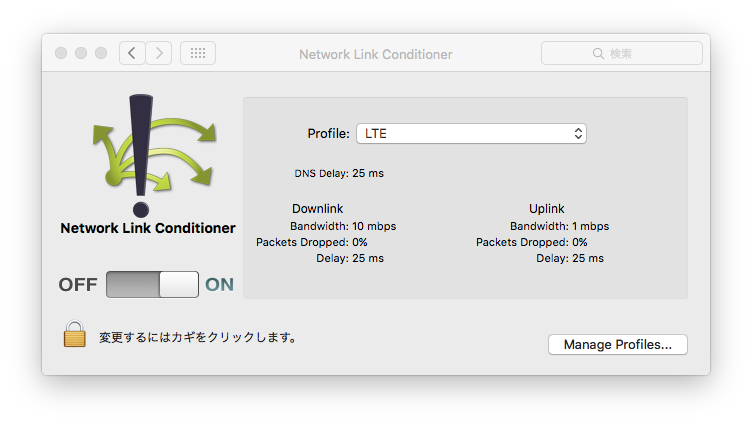
当然ながらテスト環境の回線品質が良くないとテストにならないので、平均とか25%値でテストしようと思うなら無線LANでテストしてたらダメそうです。
また、システム全体に効いてしまうので、他のアプリケーションで通信が発生しまくっているとかなり影響してきます。
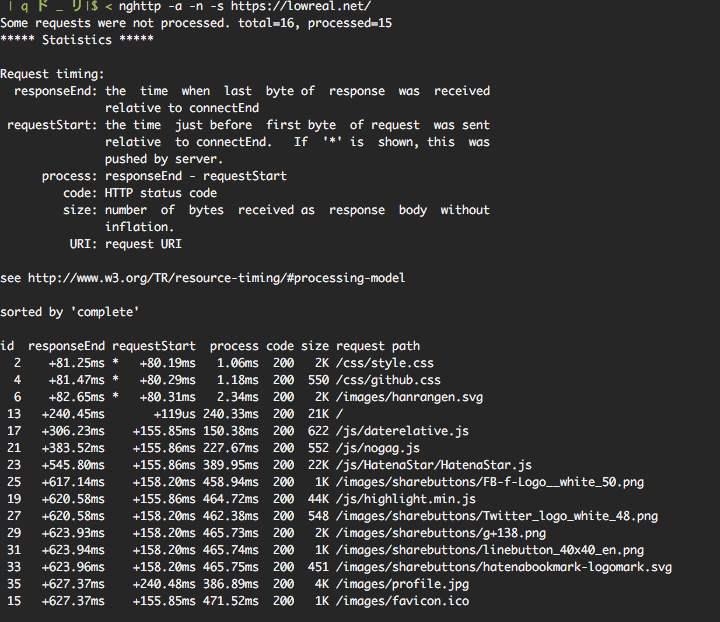
なお Chrome の場合は開発者ツールの Network タブで速度と Latency を設定して throttling できます。
ref.
![]()
![]()
![]()
h2o は mruby ハンドラで link ヘッダを使って push を指示すると、バックエンドへの問合せと非同期で静的ファイルを push してくれます。
もしバックエンドアプリケーションで link ヘッダを吐いて push する場合、バックエンドアプリケーションの処理が終わったあとから push が始まることになるので、アプリケーションの実行時間分、push できる時間を失うことになります。
自分はプリロード指示をバックエンド側のテンプレートに書きたい病にかかっており、現状で以下のようなテンプレートコードを書いて、バックエンドから preload ヘッダを吐いています。
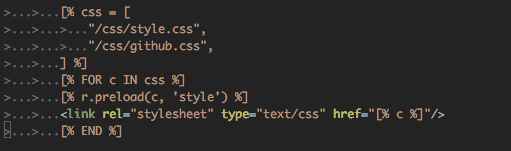
r.preload() は link ヘッダを追加するメソッドになっており、これを実際に読みこんでいるHTMLの部分の近くに置くことでリソース管理を簡略化しています。
しかし、これだとバックエンドから h2o へ server-push を指示する形になるので、前述のようにアプリケーションの実行時間分、push できる時間を無駄にします。
できれば無駄をなくしたいので、やはり h2o の mruby ハンドラでも link ヘッダを吐くことにします。
ただ、二重に設定を書きたくはないので、バックエンドの吐く link ヘッダを、h2o 起動時に取得しておき、以降のリクエストではそれを元に server-push させるようにします。
まずバックエンドのヘッダをファイルに保存しておきます。ここでは適当に curl を使ってます。
curl -s --head -H 'Cache-Control: no-cache' https://lowreal.net > /srv/www/lowreal.net.link.txt
そして、起動時に read して push する分の link ヘッダを作っておき、ハンドラでそれを送るように設定します。
mruby.handler: |
LINK = File.read("/srv/www/lowreal.net.link.txt").
split(/\r?\n/).select{|l| l.sub!(/^link: /, "") and l.match(/rel=preload/) and !l.match(/nopush/) }.
join("\n")
$stderr.puts LINK.inspect
lambda do |env|
[ 399, { "link" => LINK }, [] ]
end 運用上は、適当なタイミング(デプロイタイミング)で curl を打って再度ヘッダを保存して h2o を再起動するようにします。
余談ですが curl を使わずとも mruby ハンドラ内で使える http_request() があるので h2o で完結しそうと思いきや、起動中のコンテキストでは使えないみたいです。
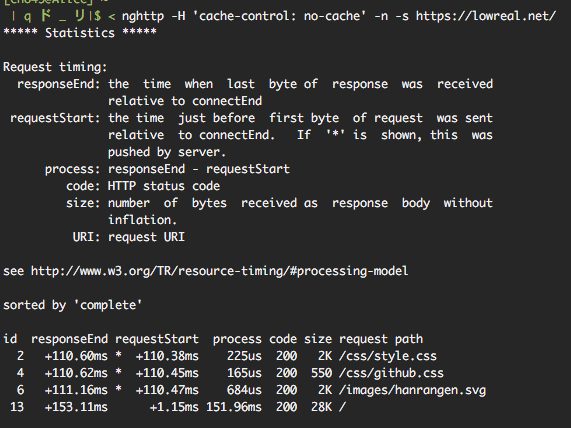
mruby ハンドラで server-push を指示しない場合
mruby ハンドラで server-push を指示する場合
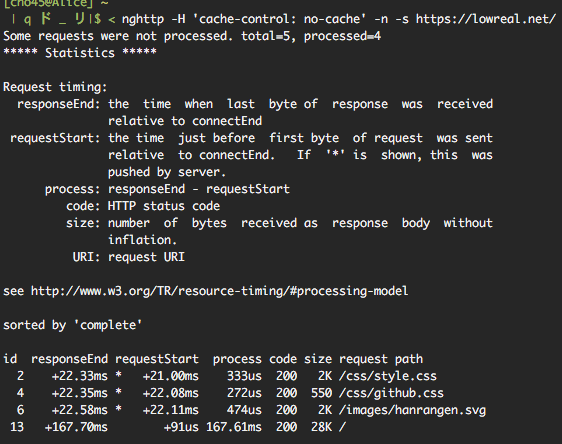
見るべきは、各リソースの responseEnd の時間と、 / に対する requestStart の時間の差です。ただ requestStart はいずれも 1ms 程度なので、注目するのは responseEnd だけで良さそうです。
mruby ハンドラで指示しない場合各リソースの responseEnd は100ms以上になっています。これはバックエンドの処理に約100msほどかかっているからです。一方 mruby ハンドラで指示する場合、responseEnd は 22ms ぐらいになっています。
この例だと、静的ファイルの responseEnd から、バックエンドのレスポンス開始までまだ時間があるので、もっと静的ファイルを server-push する余地がありそうです。
('cache-control: no-cache' をつけているのはバックエンド側のキャッシュを無効にして処理時間を作って差をわかりやすくしているだけです)
![]()
![]()
![]()
h2o の casper (cache-aware server-push) を有効にしていると、force reload したときでも push されなくなってしまって、だんだん混乱してきます。YAML を一時的に変えて再起動したりしていたのですが、自分以外にも影響が及ぶのでちょっとなんとかしました。
最初に思いつく方法で手軽なやつです。以下のようなブックマークレットでリロードすると cookie がない状態からのリロードになります。
javascript:document.cookie="h2o_casper=; max-age=-1; path=/";location.reload(true);
force reload 時にブラウザはリクエストヘッダに Cache-Control: no-cache をつけるので (全てのブラウザかどうかわかりませんが)、その場合にはクッキーを無視して push します (set-cookie は吐かれます)
Cache-Control: no-cache とクライアントが宣言しているなら、casper も無効になっているのは正当ではないか?と思い実装しましたが、ほんとにそうか自信がないので、ひとまず自分のところでテストしています (このサーバには適用済み)。
diff --git a/lib/http2/connection.c b/lib/http2/connection.c
index 4395728..bc83829 100644
--- a/lib/http2/connection.c
+++ b/lib/http2/connection.c
@@ -1185,6 +1185,19 @@ static void push_path(h2o_req_t *src_req, const char *abspath, size_t abspath_le
src_stream->pull.casper_state = H2O_HTTP2_STREAM_CASPER_DISABLED;
return;
}
+
+ /* disable casper (always push) when super-reloaded (cache-control is exactly matched to no-cache) */
+ if ( (header_index = h2o_find_header(&src_stream->req.headers, H2O_TOKEN_CACHE_CONTROL, -1)) != -1) {
+ h2o_header_t *header = src_stream->req.headers.entries + header_index;
+ if (h2o_lcstris(header->value.base, header->value.len, H2O_STRLIT("no-cache"))) {
+ /* casper enabled for this request but ignore cookie */
+ if (conn->casper == NULL)
+ h2o_http2_conn_init_casper(conn, src_stream->req.hostconf->http2.casper.capacity_bits);
+ src_stream->pull.casper_state = H2O_HTTP2_STREAM_CASPER_READY;
+ break;
+ }
+ }
+
/* casper enabled for this request */
if (conn->casper == NULL)
h2o_http2_conn_init_casper(conn, src_stream->req.hostconf->http2.casper.capacity_bits);
mruby.handler でなんとかできないかと思いましたが、mruby 側の env に渡ってくる HTTP_COOKIE とかを書きかえても h2o 内部の処理には影響しないみたいなので無理そうでした。
![]()
![]()
![]()
すこし昔書いたGoogle Keepのメモを発掘してきました。
電気料金 を30円/kWh、NAS の消費電力を 20W で計算すると、446円/月。24時間動かすので思いのほか電気料金がかかっていることになり、初期コストも含めて考えると、オンラインサービスと案外競合する。
NAS の特徴は
オンラインサービスの特徴
エンドユーザ向けサービスだが値下げによりかなり安価になっている。
1TBプランが月額$9.99、30Tまではほぼ$0.01/GBとなる。Nearline とほぼ同じだが、容量を使いきっていなくてもプラン容量分課金される点で異なる。
取り出しは当然無料だが速度の保証はない
エンドユーザ向けのサービス。有料プランは1TBのみで、月額1200円。1TB 以上のプランがないので、それ以上になる予測がたつ場合選択肢にあがらない。
エンドユーザ向けサービス。有料プランの最大が1TB、1TBのとき年額40000円。月額換算で3333円とかなり高い。
ただし、プライム会員(3900円/年)の場合、写真データ(RAWも含む)が無制限となっており写真だけ上げるなら異常に安い。しかしこの手の無制限サービスはすぐ終了する予測しかない。
約1円/GB
取り出しコストが大変複雑。月あたり使用容量の5%までを1時間あたりに分散してゆっくり取り出せば (約0.0067%/時) 無料。つまり取り出しソフトウェアがちゃんとしていれば、20ヶ月で常に無料で全量を取り出し可能
約1円/GB ($0.01/GB)
取り出しも$0.01/GBと書いてあるが、実際はこれに加えて転送量課金がある。$0.12/GB
なので、1TB ダウンロードしようとすると16000円ぐらいかかる。純粋に従量課金なので Glacier より料金はわかりやすいが、無料の範囲というのは存在しないので、ダウンロードでは必ずこの金額必要になる。
エンドユーザ的には価格で Google Drive に対するメリットがない。
![]()
![]()
![]()
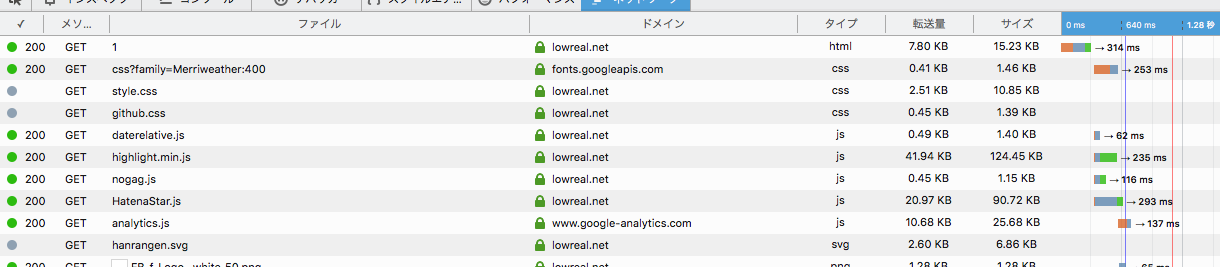
Firefox だと上記のようにリクエストが消滅してタイミングも全てない表示になるみたいです。
Chrome の Network タブだとプッシュしてもキャッシュからひいてくる時間を表示しているのか区別できなくてモヤっとします。
![]()
![]()
![]()
JSなしのソーシャルボタンというのを作ってみました。このサイトの各エントリ下部に実装されているものです。
各サービス、JS を読みこんでボタンを表示するタイプのものをメインに提供していますが、ソーシャルサービスへのシェアという機能で外部リソースの読み込みとJSの実行が発生するのは、提供される機能に対して割に合わないのではないかと思っていました。
実際ウェブサイトのパフォーマンスチューニングをしていると、細かいボタンのJSのダウンロード・パース・実行・表示後のリフローが結構多くて気になります。
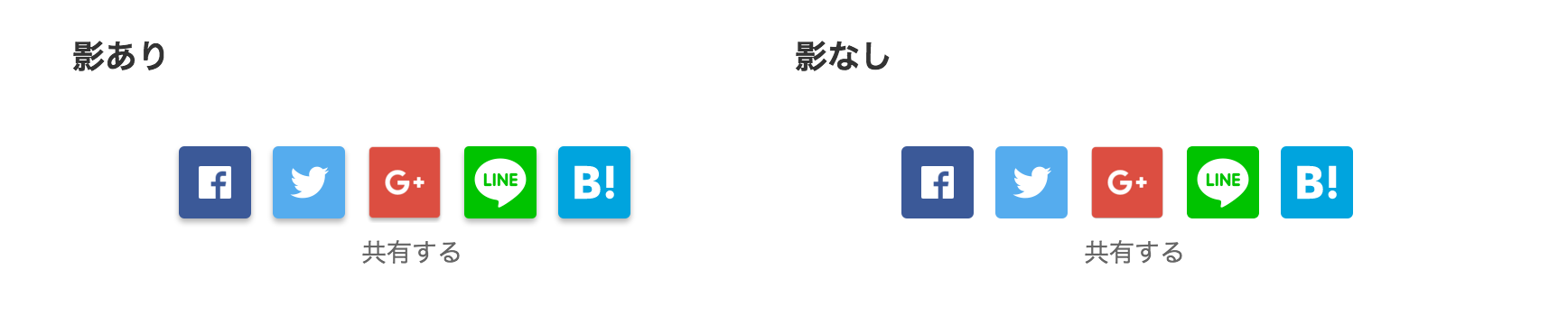
サービス
HTML+CSS+各サービスのアイコン画像(5つ)です。
各サービスのアイコンをSVGにしたかったのですが、各サービスのブランドガイドラインを読んでいると面倒になったのでオフィシャルなものを使っています。オフィシャルにSVG版が提供されていれば悩まないんですが、はてなブックマークしか提供していないようでした。
使っている画像はオフィシャルのものですが、さらに optipng や svgo をかけてあります (一部の画像にしか効きませんでしたが)。
LINE it! はスマフォかつアプリが入ってないと機能しません。JS版のボタンはスマフォの場合だけ出すような判定も入っているようです。テストページでは出しわけをしていませんが、このサイト内では画面サイズが小さいときだけ出るようにしています。
![]()
![]()
![]()

毎日寝る前に飲んでみてる。そんな期待してなかったけど、寝起きは確かに多少良くなった。元々ものすごく寝起きが悪いので少しマシになった程度だと思う。
ただし、短い睡眠時間を補うようなものではないので、睡眠時間が短いとあまり変わらずただただ眠い。どうしようもない。
![]()
![]()
![]()
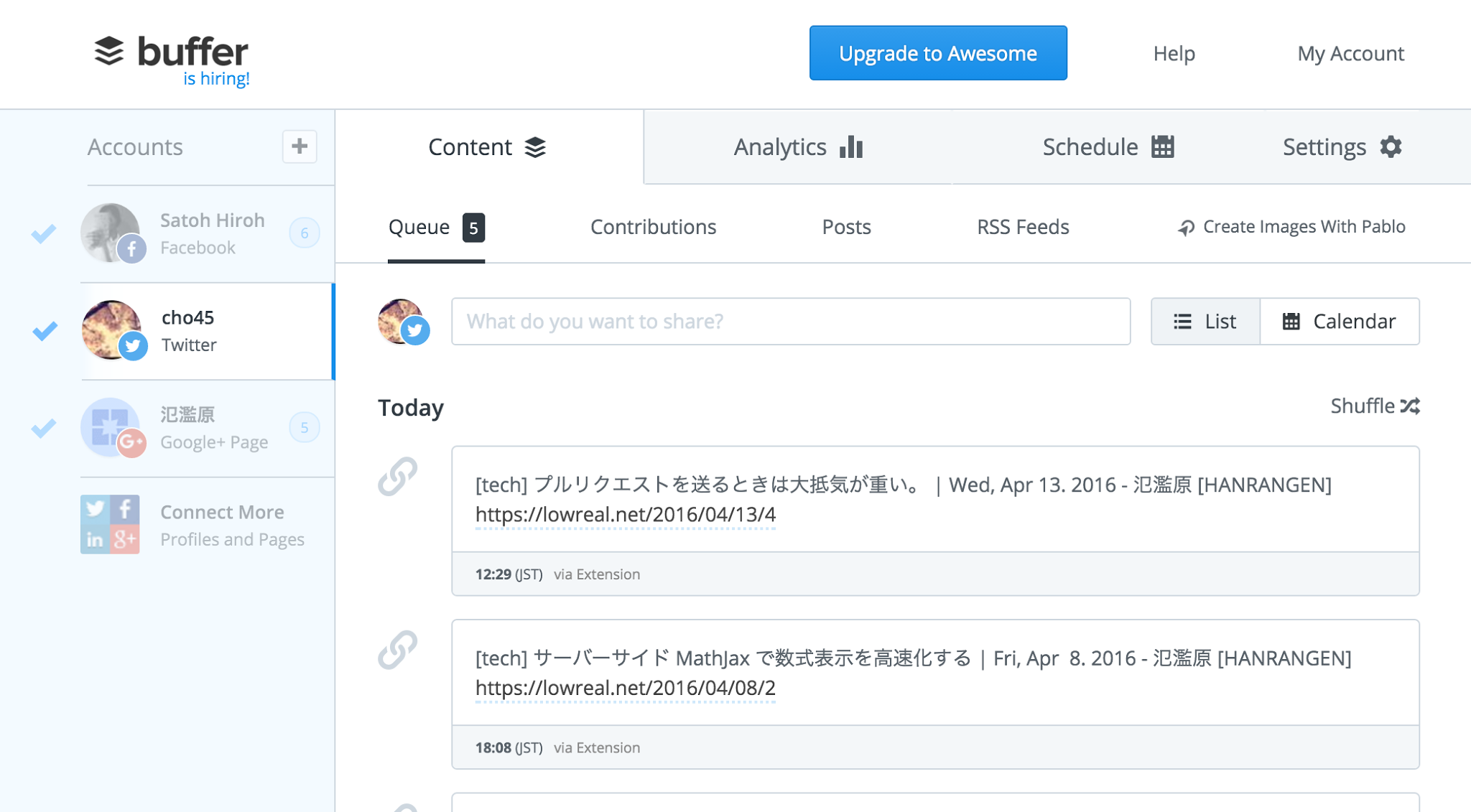
buffer というのをちょっと使ってみようとしています。予め Facebook / Twtter などを接続して、スケジュールを設定しておくと、buffer 経由で投稿したときにいい感じにマルチポストするというツールです。
スケジュールの設定がおもしろくて「このサービスはこの時間帯に投稿すると効果がたかいぞ!」みたいなことをサジェストしてくれて、それを時刻に設定できます。
buffer への投稿自体は chrome 拡張経由で手動でやってみています。
使い続けるかはよくわかりませんが、現在 Twitter とか Facebook を見ないようにしているので、buffer のような別サービスを挟んでおけば、うっかり見ることも減って良さそうです。
![]()
![]()
![]()
そういえば なんとなく思いたったので Twitter 使うのをやめてみ… | Mon, Feb 15. 2016 - 氾濫原 というエントリを書いてから2ヶ月ぐらい経ってました。意外と見ないと決めてしまえば見ないものです。
最初の一ヶ月ぐらい twitter.com, www.facebook.com, b.hatena.ne.jp を /etc/hosts を使ってブロックしていましたが、twitter.com と www.facebook.com はそんなことしなくても案外見ないのでブロックするのをやめました。b.hatena.ne.jp はうっかり見たい欲求にかられることがあるので、PCによってはブロックしたままにしてあります。
あたり前ですが Twitter や Facebook 由来のストレス(けまらしい感・バカにされている感)と時間の浪費はなくなったので、その点はいい感じです。代わりにそれらよりは多少生産的なこと (日記とか) に時間を消費している気がします。
精神の安定のため、内在的かつアウトプットを増やそうというのが自然にできるようになるといいなと思っています。
誰かに褒められれば嬉しいのは確かだけれども、それは直接次のモチベーションには繋がらないし、「誰かに褒められる」ことよりも「誰かに貶される」という期待値のほうが圧倒的に高いので、そういう場は精神を不安定にするだけで割に合わないという判断にまとめています。
![]()
![]()
![]()
あんまりスター付かないので気付いてなかったのですが、Chrome 拡張の「はてなのお知らせ」とかに通知がこなくなっていることに気付きました。
おそらく「HTTPS にしたこと」というより、http: から https: に URL が代わったことにより Hatena.Star.Token の更新が必要なんだと思います。が、s.hatena.ne.jp/cho45/blogs にログイン状態でアクセスすると現状タイムアウトしてしまうので、詰んでいます。
HatenaStar.js を読んでて気付いたのですが、
Hatena.Star.Token = null; がベタに書いてあるため、async と併用するとそもそも Token が初期化されてしまうようでした……
HTTPS とか関係なかったです。HTTP ではてなスターに登録していても、リダイレクトしているなら、リダイレクト先の Token を読んで判断するようです。
しかしHTTPSにしたことによって過去のスターが消えてそうなことに気付いたので、どうしようか考えています。
結局にっちもさっちも行かないことがわかったので、HatenaStar.js のコピーを編集して使うようにしました。
はてなスターに渡すURLは http: に戻しました。HTTPS になってからついたスターが表示されなくなってしまいますが (申し分けないのですが)、HTTP のときについたスターは復活するはずです……
まぁそもそも、そろそろはてなスター止めてもいいかもしれないんですが、もうちょっと頑張ってみようという感じです。
--- HatenaStar.orig.js 2016-04-15 23:11:20.355944766 +0900
+++ HatenaStar.js 2016-04-15 23:11:34.687944255 +0900
@@ -4655,7 +4655,39 @@
/* start */
-new Hatena.Star.WindowObserver();
+// new Hatena.Star.WindowObserver();
+
+Hatena.Star.Token = '7743b0e60f0e3b267f9723d3a5cf96981a59e4f3';
+Hatena.Star.EntryLoader.loadEntries = function (node) {
+ console.log('custom EntryLoader');
+ var entries = [];
+ var entryNodes = node.getElementsByTagName('article');
+ for (var i = 0, entryNode; (entryNode = entryNodes[i]); i++) {
+ var uri = entryNode.querySelector('a.bookmark').href || '';
+ var title = entryNode.querySelector('h1').innerText;
+ var container = entryNode.querySelector('.social .hatena-star');
+
+ var sc = Hatena.Star.EntryLoader.createStarContainer();
+ container.appendChild(sc);
+ var cc = Hatena.Star.EntryLoader.createCommentContainer();
+ container.appendChild(cc);
+
+ entries.push({
+ uri: uri.replace(/^https:/, 'http:'),
+ title: title,
+ star_container: sc,
+ comment_container: cc
+ });
+ }
+
+ console.log('custom EntryLoader loaded', entries);
+
+ return entries;
+};
+
+window.addEventListener('load', function () {
+ new Hatena.Star.EntryLoader();
+});
/* Hatena.Star.SiteConfig */
/* sample configuration for Hatena Diary */
![]()
![]()
![]()
[tech] JavaScript の必要ないソーシャルボタン | Fri, Apr 15. 2016 - 氾濫原 これを作るとき、最初のうちは全てSVGにするぞと意気込んでいて、Ligature Symbols に含まれるものをSVGに変換したらいいのではないかと、いろいろ試していました。
結局その方法はやめたのですが、SVG フォントから、個別の SVG ファイルに変換するスクリプトを雑に書いたので残しておきます。SVG フォント全体だとファイルサイズが大きすぎるので、必要なファイルだけ普通の SVG 画像として抽出するということです。
以下のように perl + XML::LibXML で書きました。グリフ名を引数に与えると、該当するグリフを個別の .svg に書き出します。LigatureSymbols でしか試していませんが、SVG フォントなら他のでもいけるかもしれません。
#!/usr/bin/env perl
use utf8;
use strict;
use warnings;
use v5.10.0;
use lib lib => glob 'modules/*/lib';
use XML::LibXML;
open(my $fh, "<", "LigatureSymbols-2.11.svg") or die "cannot open < input.txt: $!";
my $font = do { local $/; scalar <$fh> };
close $fh;
my $doc = XML::LibXML->load_xml( string => $font, load_ext_dtd => 0 );
my $xpc = XML::LibXML::XPathContext->new($doc);
# get copyright metadata
my $original_metadata = $xpc->findvalue('/svg/metadata');
my $units_per_em = $xpc->findvalue('/svg/defs/font/font-face/@units-per-em');
my $ascent = $xpc->findvalue('/svg/defs/font/font-face/@ascent');
my $bbox = $xpc->findvalue('/svg/defs/font/font-face/@bbox');
for my $glyph_name (@ARGV) {
my $glyph = $xpc->findnodes(sprintf('/svg/defs/font/glyph[@glyph-name="%s"]', $glyph_name))->[0];
my $horiz_adv_x = $xpc->findvalue('./@horiz-adv-x', $glyph);
my $document = XML::LibXML::Document->new('1.0', 'UTF-8');
my $svg = $document->createElement('svg');
$svg->setAttribute('width', $horiz_adv_x);
$svg->setAttribute('height', $units_per_em);
# $svg->setAttribute('viewBox', $bbox);
$svg->setAttribute('xmlns', 'http://www.w3.org/2000/svg');
$document->setDocumentElement($svg);
my $metadata = $document->createElement('metadata');
$metadata->appendChild($document->createTextNode($original_metadata));
$svg->appendChild($metadata);
my $path = $document->createElement('path');
$path->setAttribute('transform', sprintf("scale(1, -1) translate(0,%s)", -$ascent));
$path->setAttribute('fill', '#fff');
$path->setAttribute('d', $xpc->findvalue('./@d', $glyph));
$svg->appendChild($path);
warn "write to $glyph_name.svg";
say $document->toString(1) ;
open(my $fh, ">", "$glyph_name.svg");
print $fh $document->toString;
close $fh;
}
![]()
![]()
![]()
![]()
![]()
![]()
ずっと中途半端なデザインだなと思っていたので、改めて全体を見直しました。
大きい画像は devicePixelRatio に基いて大きい画像をロードするようなスクリプトを書いていたのですが、面倒なので最近になって常に 2048px の画像を読みこむように変えました。
しかし画面の表示は 960px 程度を最大にしており、Retina でも若干の無駄があるのが気になってきました。ということで、まず 1024px を最大幅にできるようにしました。
しかし、意外ともう少し狭い幅で見ることも多い気がするので (特に開発ツールを横に開いていると結構画面が狭い)、その場合幅だけ変えたバージョンをメディアクエリでだしわけしています。
スマートフォン向けにはさらに狭い幅向けのバージョンをメディアクエリでだしわけていますが、これはほぼ今まで通りです。
また、大きい画面の場合、photo タグが設定されているエントリと、それ以外のエントリで画像の幅を変えるようにしました。tech カテゴリでも無駄に横幅が大きい画像になっていて一画面の情報量が少なかったので、これで見易くなった気がします。
しかし、テキストの幅を制限しつつ画像は大きく表示したいと思うと、自分のデザイン能力だと綺麗にいかず難しく感じます。
![]()
![]()
![]()

STM32F103 C8 T6 の安いボードが ebay で売っているので買ってみました。水晶が実装済み基板が 300円程度。届いたボードに実装済みの外部水晶は8MHz (内蔵RCと周波数は一緒) のようです。また 32.768k の水晶もついています。他に実装されているのはLDOやUSBコネクタぐらいです。
なお USB デバイスを作りたい場合 RC オシレータだとクロック精度が足りないので外部水晶は必須です。
買ったのはこれです: http://www.ebay.com/itm/201529768817
STM32F103 C8 T6 という型番の読みかた
をあらわしています。STM32F103x8 (64k) や STM32F103xB (128k) はスペックシート共通になっています。 (ピン数とFlashのサイズの違いのみなので)
以下個人的に良さそうと思った点です。
Cortex-M3 なので M0 よりはパフォーマンスが良さそうです。一方 FPU や DSP 関係の命令 (SIMDとか) は M0 同様ありません。
SYSCLK (システムクロック) は
の3種類のクロックソースがあります。
HSE はさらに HSE バイパスと HSE クリスタルとに別れています。バイパスは発振器のクロックを直接入れるモードです。
PLL のクロックソースにはHSIとHSEがどちらも使えるようになっています。
8MHz の外部水晶がついてるので、8MHz の HSE を PLL のクロックソースとして 72MHz にします。USB 用のクロックもここから作ることになっています。
みたいになりそうです。が、とりあえず mbed 環境で動かしてみるためクロック設定は無視します (mbed 側で 72MHz に適当に設定されます)
例によって環境を整える部分は platformio でやります。
platformio.ini は以下のようにします。nucleo_f103rb は型番違いですが、ほぼほぼ互換性があります。nucleo_f103rb の外部水晶も 8MHz のようで、この場合 mbed の初期化コードは一切変更なしでいけそうです。
本来 boards の追加をもっと簡単にできたらいいのですが、現状の platfromio だとそういうことはできなそうです。
# platformio.ini # nucleo_f103rb は f103c8t6 とフラッシュサイズとピン数以外は互換 # 外部クロックも 8MHz で同じのためそのまま使える [env:stm32f103c8t6] platform = ststm32 framework = mbed board = nucleo_f103rb
Lチカはこのようにしました
#include "mbed.h"
DigitalOut led(PC_13);
// Serial serial(USBTX, USBRX);
int main() {
for (;;) {
led = 1;
wait(0.5);
led = 0;
wait(0.5);
}
} PC_13 はボード上のLEDに繋がっています。nucleo_f103rb だと LED1 は PA_5 のようなので、ジェネリック名ではなくピン名で直接指定しています。

書きこみはこれまた ebay で購入した st-link2 を使いました (約400円)。Mac の USB ポートに繋ぐと特に何もしなくても認識するようでした。
ボードと st-link を接続して、USB 接続すると、基板上にも電源供給されます (別途電源供給はいらないようです)
書きこむためまず st-util を起動します。platformio で ststm32 環境をセットアップしておくと st-util もインストール済みのため楽です。
$ ~/.platformio/packages/tool-stlink/st-util 2016-04-14T00:48:41 INFO src/stlink-common.c: Loading device parameters.... 2016-04-14T00:48:41 INFO src/stlink-common.c: Device connected is: F1 Medium-density device, id 0x20036410 2016-04-14T00:48:41 INFO src/stlink-common.c: SRAM size: 0x5000 bytes (20 KiB), Flash: 0x10000 bytes (64 KiB) in pages of 1024 bytes 2016-04-14T00:48:41 INFO gdbserver/gdb-server.c: Chip ID is 00000410, Core ID is 1ba01477. 2016-04-14T00:48:41 INFO gdbserver/gdb-server.c: Target voltage is 3254 mV. 2016-04-14T00:48:41 INFO gdbserver/gdb-server.c: Listening at *:4242...
こんな感じで gdb server として立ちあがります。
別のターミナルから gdb server に接続してバイナリを送りこみます。
$ ~/.platformio/packages/toolchain-gccarmnoneeabi/bin/arm-none-eabi-gdb .pioenvs/stm32f103c8t6/firmware.elf > target extended-remote localhost:4242 > load > cont
これでLチカできました。
![]()
![]()
![]()
あいかわらず断続的に体調不良。一日会社を休んで寝てたら回復した気がしたが、また腹痛になった。吐き気はしないのでまだマシ。
ここ最近、夜中に子供がうんちしていることがあって、いざ寝ようと思うと寝室がめっちゃ臭い。子供もおそらく胃腸炎を完治してない気がする。食欲はかなりあるみたいだけど、本調子ではないのだろう。
基本的にストレスが多いのだけど、ストレスが多くなると些細なことにイライラしてさらにストレスを増やしてしまう。一方で捌け口が自分の場合ほとんどないので、どうしようもない。
直近で気が重かった仕事が一旦出て、それは良かったのだけど、出たは出たで次は何をするのかと考えると気が重いので、無限に気が重い。
「スケジュール」について考えると気がとても重くなるのだけど、実際に全体のスケジュールを決めてる人は不思議と前工程のスケジュールをさっぱり守らないので、自分が気を揉むようなことではないはずだと思う。一方スケジュールのことを無視して言われたベースでやってると「やってないんですか」みたいなことになって鬱陶しいし、なんかとにかく何をどうしても嫌な気持ちになるしかない感じがする。
保育園のナニカみたいなのが一年たってだいたい終わったんだけど、自分の役職だけまだ仕事があって、とてもだるい。なんか数秒喋るだけのために1時間か2時間拘束されるハメになる。これが終われば終わりだから我慢しよう。それにしても保育園関係のナニカは本当に不愉快だった…… これは本来「無償ボランティア」の範疇にあることだが、それは名ばかりで強制力がある。責任()というやつです。直接子供のためになるならまだしも、クソどうでもいいこと (進級時に先生にお礼をしましょう、みたいなの。個人的には心底どうでもいい) が実際殆どであった。「無償ボランティア」なうえ特にモチベーションもないので、必然的に優先順位は最下位なのだが、やたらごちゃごちゃ言われて本当に辛かった。得るものがほぼないのに時間がとられる、死にたくなるほど割に合わない。保育園のナニカと比べれば普段の仕事は大変良くて、周りの人は会話が通じるし、効率的なやりかたをしようという前提が共有されている。
![]()
![]()
![]()
![]()
![]()
![]()
JS しか書いてないんだなって人は筋悪いものをありがたがっていたりする印象はある。しかし筋悪いものをありがたがるみたいなのはどこにでもいるので、JSがどうとかは直接は関係がないはずではあると思う。JSしか書いてない人とPHPしか書いてない人は似たようなもんで、単に広範囲の知識に興味がないだけな気がする。
それはともかく「これは筋悪そうだな」っていう感覚がどこからくるのかよくわかってないので、現時点で思いつく限り雑にメモしておく。
「これは何の問題を解決してるんだろう」と思ってドキュメント読んだりソース読んだりした結果、大したことを解決してなくて、その割に実装量が多いとか学習コストが高いと、筋悪いなあと思う。
フットプリントや学習コストに対して提供されるモノが「割に合わない」のは筋が悪く感じる。
「あ、これはただの流行だな」みたいな、5年後には消滅してるなというものは筋が悪い。
標準にそういう機能入るよ、みたいなのを全然違うインターフェイスで実装してたりするのとかがあてはまる。標準で議論されている機能なら、ポリフィルにするのが最も将来無駄にならない。
HTTP2 に向けてキャッシュフレンドリーなリソース構成にしていこうな、という昨今で、何でもかんでもパックや!みたいなのも、今はぎりぎりいいかもしれないけど、既に筋悪い感じがする。
たとえば Promise はコールバックのちょっとしたラッパーぐらいの機能しかないが、プログラムの見方を変えるという重要な役割を持っているので、意味がある。
しかし単にシンタックスシュガー的なものしか提供していないとかで、何もプログラムの見方が変わっていないのにラッパーがかぶさっているのは、ライブラリとしての意味がない。
「プログラムの理解を助ける」という役割はとても重要だけど、そういう視点で作られているライブラリかどうか、それが割に合うかは難しい。
しかし最悪なのは書き手にとってしかメリットがないというもの。特に実装を全て読まないと使えない系は要注意で、そういう書き手のオナニーで変なラッパーが挟まってるみたいなのは読み手がとても苦労する。これはメリットがないというよりも明確に将来にわたって害となる。
ただし実装を全て読まないといけないものが全てだめかというとそういうわけでもない。実装は読まないと危険だけど可読性はあがるので割に合うこともある。
フレームワークのレールから外れた瞬間アホみたいなマジカルコードを書くことになる。レールから脱線すると必ずハマる。そしてフレームワークの枠組み内で収まるようなアプリケーションはない 。
もし使う場合コピペで実装できる以外のことをしないことがポイントで、「ここはこう書きたいんだ!」という自我を捨ててコピペする機械として生きなければならない。
実際のフルスタックというのは検索して出てきたstackoverflowのコピペで全部やりますよという意味で、なんでもできるという意味ではない。
![]()
![]()
![]()
意外と何をプッシュすべきか悩んだのでひとまず現時点での自分の結論をまとめました。
サイトの構成によりますが、ページの表示に必要なものは全てプッシュするべきのようです。
まずサーバプッシュの目的を改めて確認しておくと、これはクリティカルレンダリングパスを削減するためです。
クリティカルレンダリングパスについては クリティカル レンダリング パスのパフォーマンスを分析する | Web Fundamentals - Google Developers がわかりやすいです。
サーバープッシュなしの場合 HTML+CSS 構成のページはクリティカルレンダリングパスが必ず2以上になります。つまり最低でもRTTの2倍の時間がページ表示に加算されます。
これをサーバプッシュで行う場合、HTML+CSSを一度に送り返すので、クリティカルレンダリングパスは1になります。
イメージとしてはHTML内の外部CSSが全てインライン style 要素にしてある場合に似ています。ただしサーバプッシュの場合、適切なキャッシュを効かせることができるケースがあるので、インライン style 要素よりも効率的です。
これは場合によると思っています。JSがないとページの表示に致命的な不具合がある場合、サーバープッシュしないと意味がありません。
一方、JS がページのインターフェイスの向上のために使わていて、とりあえずの表示に関係がない場合、JS をプッシュした分、ファーストペイントが遅れます。
そういうわけでなので、JS をプッシュすべきかどうかは場合によるので簡単に決められない気がしています。
理想のサーバープッシュを考えるにあたって、ロードされるリソースの分類をしてみます。
ファーストペイントのために必要なリソース
DOMContentLoaded までに必要なリソース
onload までに必要なリソース
最終的に必ずロードされるリソースなら、プッシュしてしまっていいはずです (初回ロードの場合)。
の順に全てプッシュするのが理想そうです。ただ、現時点で任意の順番に優先順位を明確に決めて送信することはできないような気がしてます。
![]()
![]()
![]()
たとえ明かなバグ修正、すなわちマージされる公算が大きくても、些細なことでケチがついたりする。これがさらに機能追加みたいな「マージしてもしなくても本流には関係ないね」みたいなのは、マージされる公算がさらに低くてさらに気が重い。
まずプルリクエストを送るケースってのは、別にプルリクエストを送りたくてやってるわけではなく、そのプルリクエストに含まれるコードが自分に必要だからやってるに過ぎない。つまり最悪自分のレポジトリに置いておけばいいのだが、本流に取り込まれていれば今後のバージョンアップで機能が壊れることが減る (ついでに他に困ってる人がいたら助かるかもしれないね)。そういう保守的なモチベーションで動いていることであって、元気良くプルリクを送っているわけではない。
そういうわけで、大抵の場合プルリクエストを投げた時点で「XX だ! とか言われてDISられそうだ」とか「コードスタイルがあってない!!とか言われてリジェクトされないか」とか「オレのところだとテストが通らん!とか言われないか」とか気が滅入る妄想に支配され、燃えつきており、あとはもう勝手にしてくれ (コミュニケーションはしたくないぞ) という気分になっている。
最近良くあるのが、プルリクエスト送る前にコミュニケーションしろ!みたいなルールを強いているプロジェクトで、こういうのはほんとどうしようもない。死ぬほど困っているとか、仕事でやるとかじゃないならプルリク送る気がしない。コミュニケーションしたくないからコード書いてプルリクしてんのに、コミュニケーションを強要してくるのはどういうことなのか。かつて github に感じた居心地の良さはここにはない。
![]()
![]()
![]()
サボさんいい
「ワンワンパッコロ!キャラともワールド」でワンワンとサボさんが共演する夢の回があって、サボさんがダンソン(バンビーノ)をやっていた。この番組、全体的に子供には難しいネタが多い。改めて見るとお笑いって常識(お約束)を裏切る形のパターンがよくあって、そもそも常識のない子供はいつから笑えるようになるのだろうと思った。
![]()
![]()
![]()
殆どアクセスがないサイトは、ファーストアクセスでキャッシュを作るようなサーバサイドキャッシュの戦略が全く意味がないので、バッチで予めキャッシュを作っておくみたいなことが必要そうだなと思い、そういうスクリプトを書いて流せるようにしました。
特にサイトのHTML頻繁に変えたりしているとしょっちゅうキャッシュの意味がなくなります。要はこれ、blosxom における静的なページ生成とか、MT におけるリビルドみたいなもんです。
![]()
![]()
![]()

