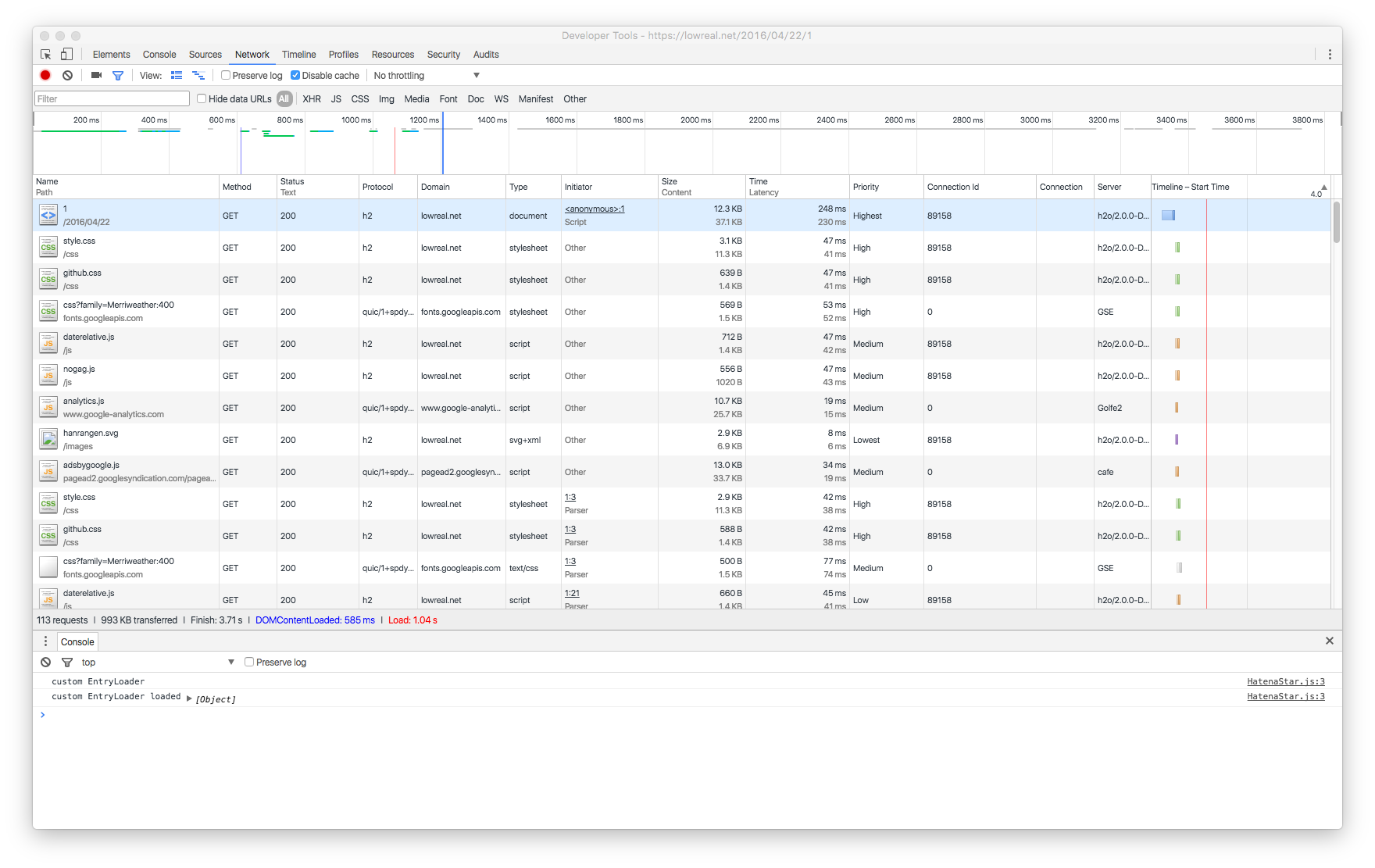
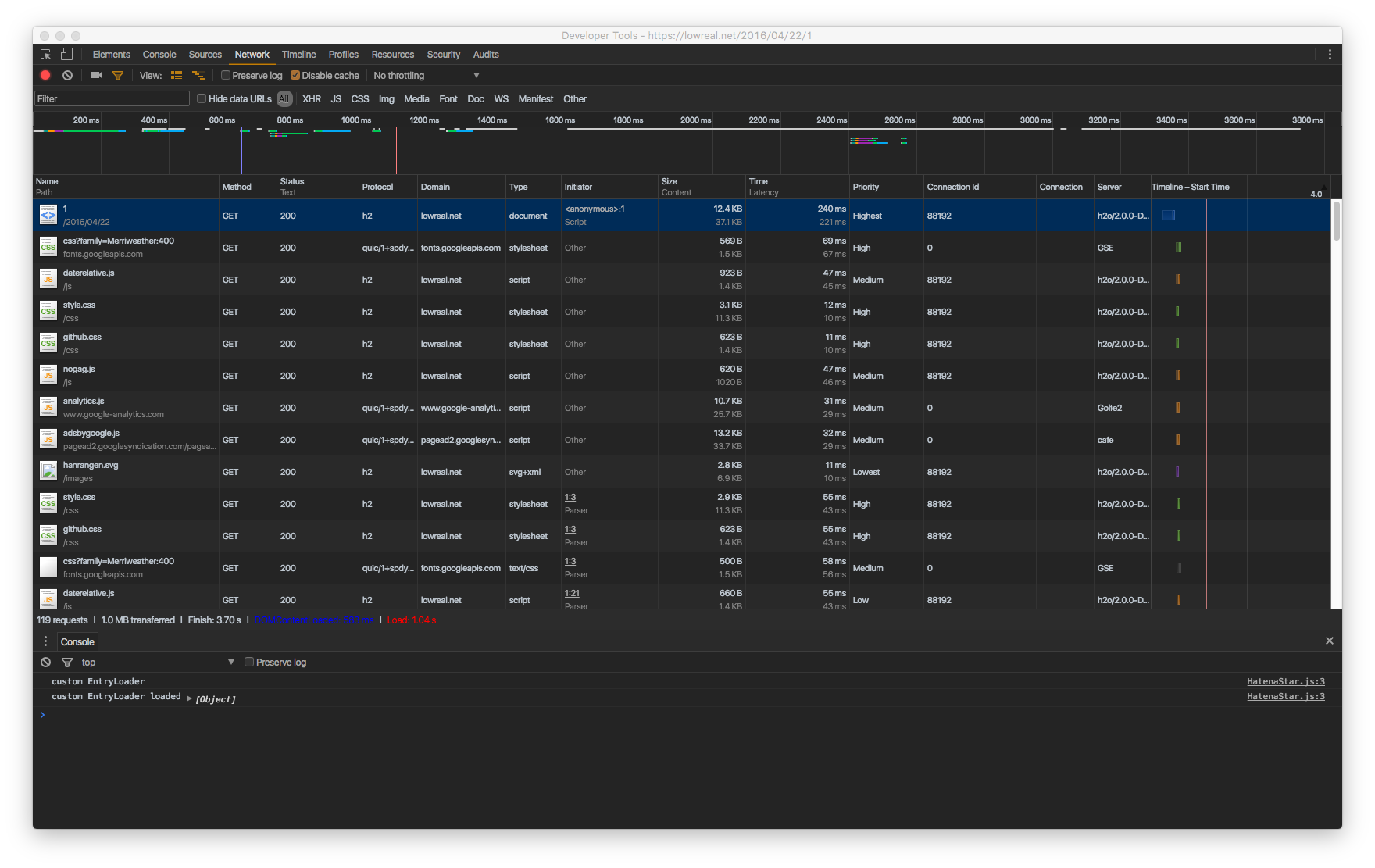
エントリ保存時には、minify もそうですが、ほかにも修正を加えたいことが多々あります。例えば画像を強制的に https 化して mixed content を防ぎたいとか、コードハイライトを行いたいとかです。
コードハイライトは今まで highlight.js を使い、クライアントサイドでやっていました。これも本来ダイナミックにやる必要はなくポストプロセスでできることなので、そのように変えることにしました。highlight.js をサーバサイドで行うと、付与されるマークアップ分 HTML の転送量が増えますが、highlight.js 自体が結構大きいので、かなり長いコードをハイライトしない限り、サーバサイドでやったほうが得そうです。
これにより、クライアントサイドでやってたことをそのままサーバサイドできるようになりました。すなわち、hightlight.js をそのままサーバサイドでも動かしていますし、jsdom を使って細かいHTMLの書きかえを querySelector など標準の DOM 操作でできるようにしています。
ポストプロセス用のデーモン
前述のように node.js で動くデーモンで、ブログシステム(Perl)とは別のプロセスで動き、APIサーバになっています。
全体的には以下のようなコードです。なお書き換え部分は変な挙動をするとやっかいなので、テストを書けるようにしてあります。
#!/usr/bin/env node
const jsdom = require("jsdom").jsdom;
const mjAPI = require("mathjax-node/lib/mj-page.js");
const hljs = require('highlight.js');
const minify = require('html-minifier').minify;
const http = require('http');
const https = require('https');
const url = require('url');
const vm = require('vm');
const HTTPS = {
GET : function (url) {
var body = '';
return new Promise( (resolve, reject) => {
https.get(
url,
(res) => {
res.on('data', function (chunk) {
body += chunk;
});
res.on('end', function() {
res.body = body;
resolve(res);
})
}
).on('error', reject);
});
}
};
mjAPI.start();
mjAPI.config({
tex2jax: {
inlineMath: [["\\(","\\)"]],
displayMath: [ ["$$", "$$"] ]
},
extensions: ["tex2jax.js"]
});
function processWithString (html) {
console.log('processWithString');
return Promise.resolve(html).
then(processMathJax).
then(processMinify);
}
function processWithDOM (html) {
console.log('processWithDOM');
var document = jsdom(undefined, {
features: {
FetchExternalResources: false,
ProcessExternalResources: false,
SkipExternalResources: /./
}
});
document.body.innerHTML = html;
var dom = document.body;
return Promise.resolve(dom).
then(processHighlight).
then(processImages).
then(processWidgets).
then( (dom) => dom.innerHTML );
}
function processHighlight (node) {
console.log('processHighlight');
var codes = node.querySelectorAll('pre.code');
for (var i = 0, it; (it = codes[i]); i++) {
if (/lang-(\S+)/.test(it.className)) {
console.log('highlightBlock', it);
hljs.highlightBlock(it);
}
}
return Promise.resolve(node);
}
function processImages (node) {
console.log('processImages');
{
var imgs = node.querySelectorAll('img[src*="googleusercontent"], img[src*="ggpht"]');
for (var i = 0, img; (img = imgs[i]); i++) {
img.src = img.src.
replace(/^http:/, 'https:').
replace(/\/s\d+\//g, '/s2048/');
}
}
{
var imgs = node.querySelectorAll('img[src*="cdn-ak.f.st-hatena.com"]');
for (var i = 0, img; (img = imgs[i]); i++) {
img.src = img.src.
replace(/^http:/, 'https:');
}
}
{
var imgs = node.querySelectorAll('img[src*="ecx.images-amazon.com"]');
for (var i = 0, img; (img = imgs[i]); i++) {
img.src = img.src.
replace(/^http:\/\/ecx\.images-amazon\.com/, 'https://images-na.ssl-images-amazon.com');
}
}
return Promise.resolve(node);
}
function processWidgets (node) {
var promises = [];
console.log('processWidgets');
var iframes = node.querySelectorAll('iframe[src*="www.youtube.com"]');
for (var i = 0, iframe; (iframe = iframes[i]); i++) {
iframe.src = iframe.src.replace(/^http:/, 'https:');
}
var scripts = node.getElementsByTagName('script');
for (var i = 0, it; (it = scripts[i]); i++) (function (it) {
if (!it.src) return;
if (it.src.match(new RegExp('https://gist.github.com/[^.]+?.js'))) {
var promise = HTTPS.GET(it.src).
then( (res) => {
var written = '';
vm.runInNewContext(res.body, {
document : {
write : function (str) {
written += str;
}
}
});
var div = node.ownerDocument.createElement('div');
div.innerHTML = written;
div.className = 'gist-github-com-js';
it.parentNode.replaceChild(div, it);
}).
catch( (e) => {
console.log(e);
});
promises.push(promise);
}
})(it);
return Promise.all(promises).then( () => {
return node;
});
}
function processMathJax (html) {
console.log('processMathJax');
if (!html.match(/\\\(|\$\$/)) {
return Promise.resolve(html);
}
return new Promise( (resolve, reject) => {
mjAPI.typeset({
html: html,
renderer: "SVG",
inputs: ["TeX"],
ex: 6,
width: 40
}, function (result) {
console.log('typeset done');
console.log(result);
resolve(result.html);
});
});
}
function processMinify (html) {
return Promise.resolve(minify(html, {
html5: true,
customAttrSurround: [
[/\[%\s*(?:IF|UNLESS)\s+.+?\s*%\]/, /\[%\s*END\s*%\]/]
],
decodeEntities: true,
collapseBooleanAttributes: true,
collapseInlineTagWhitespace: true,
collapseWhitespace: true,
conservativeCollapse: true,
preserveLineBreaks: false,
minifyCSS: true,
minifyJS: true,
removeAttributeQuotes: true,
removeOptionalTags: true,
removeRedundantAttributes: true,
removeScriptTypeAttributes: true,
removeStyleLinkTypeAttributes: true,
processConditionalComments: true,
removeComments: true,
sortAttributes: true,
sortClassName: false,
useShortDoctype: true
}));
}
const port = process.env['PORT'] || 13370
http.createServer(function (req, res) {
var html = '';
var location = url.parse(req.url, true);
req.on('readable', function () {
var chunk = req.read();
console.log('readable');
if (chunk) html += chunk.toString('utf8');
});
req.on('end', function() {
console.log('end');
if (location.query.minifyOnly) {
Promise.resolve(html).
then(processMinify).
then( (html) => {
console.log('done');
res.writeHead(200, {'Content-Type': 'text/plain; charset=utf-8'});
res.end(html);
}).
catch( (e) => {
console.log(e);
console.log(e.stack);
res.writeHead(500, {'Content-Type': 'text/plain; charset=utf-8'});
res.end(html);
});
} else {
Promise.resolve(html).
then(processWithDOM).
then(processWithString).
then( (html) => {
console.log('done');
res.writeHead(200, {'Content-Type': 'text/plain; charset=utf-8'});
res.end(html);
}).
catch( (e) => {
console.log(e);
console.log(e.stack);
res.writeHead(500, {'Content-Type': 'text/plain; charset=utf-8'});
res.end(html);
});
}
});
}).listen(port, '127.0.0.1');
console.log('Server running at http://127.0.0.1:' + port); 



![ガールズ&パンツァー 劇場版 [Blu-ray] - 渕上舞](https://m.media-amazon.com/images/I/61QuPEjbaOL._SL500_.jpg)