前年の振り返りと今年の抱負
前年
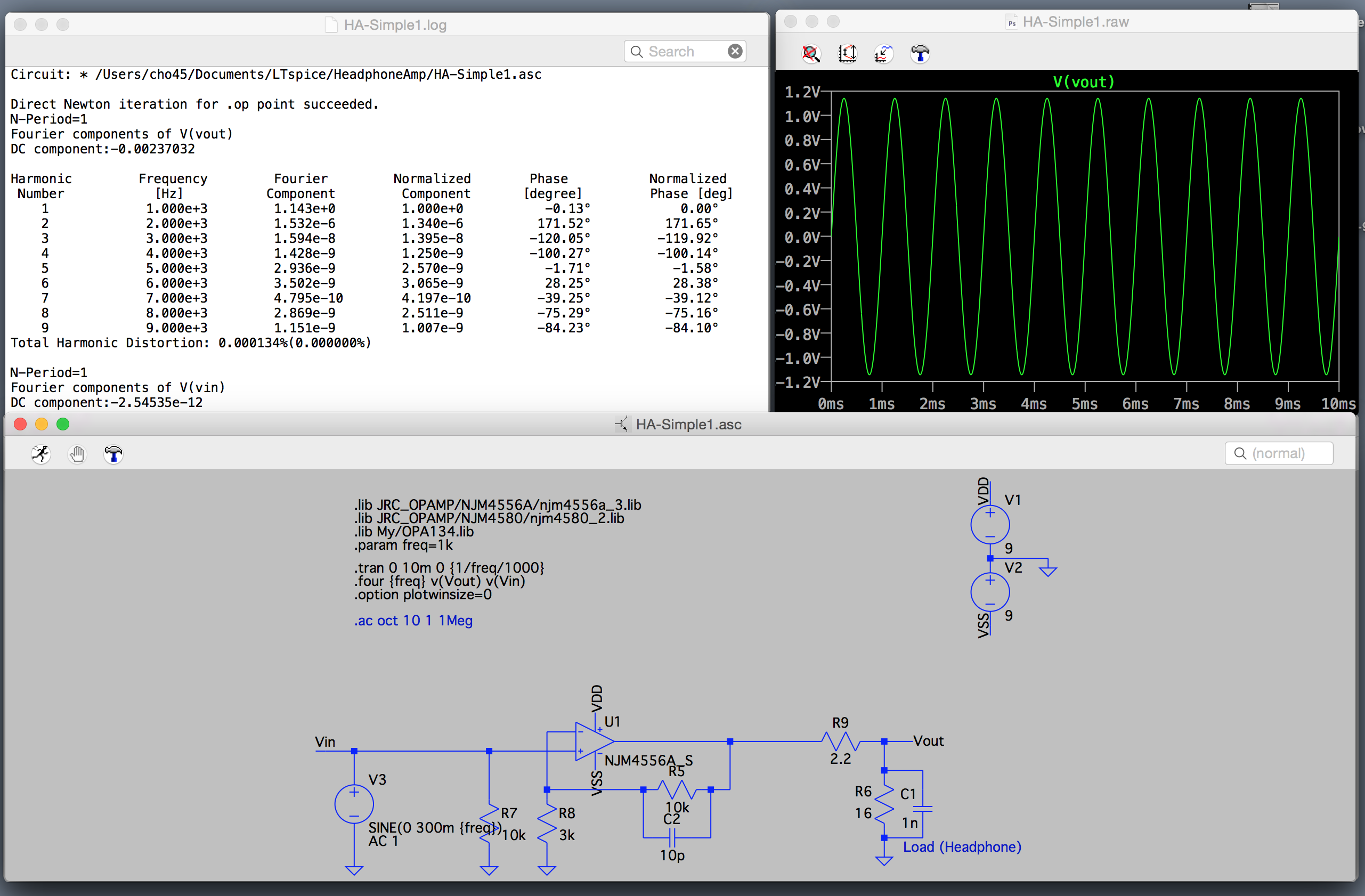
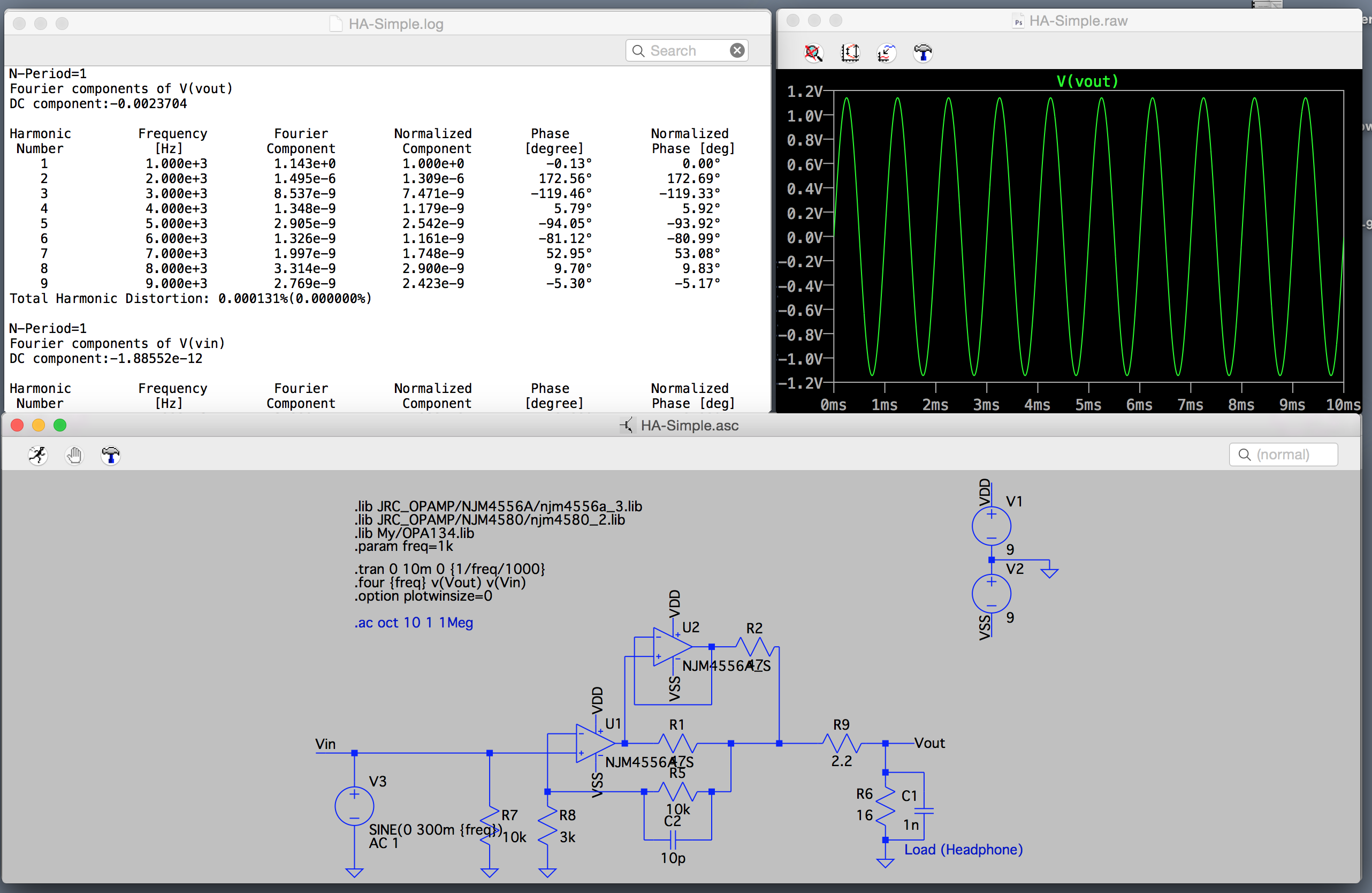
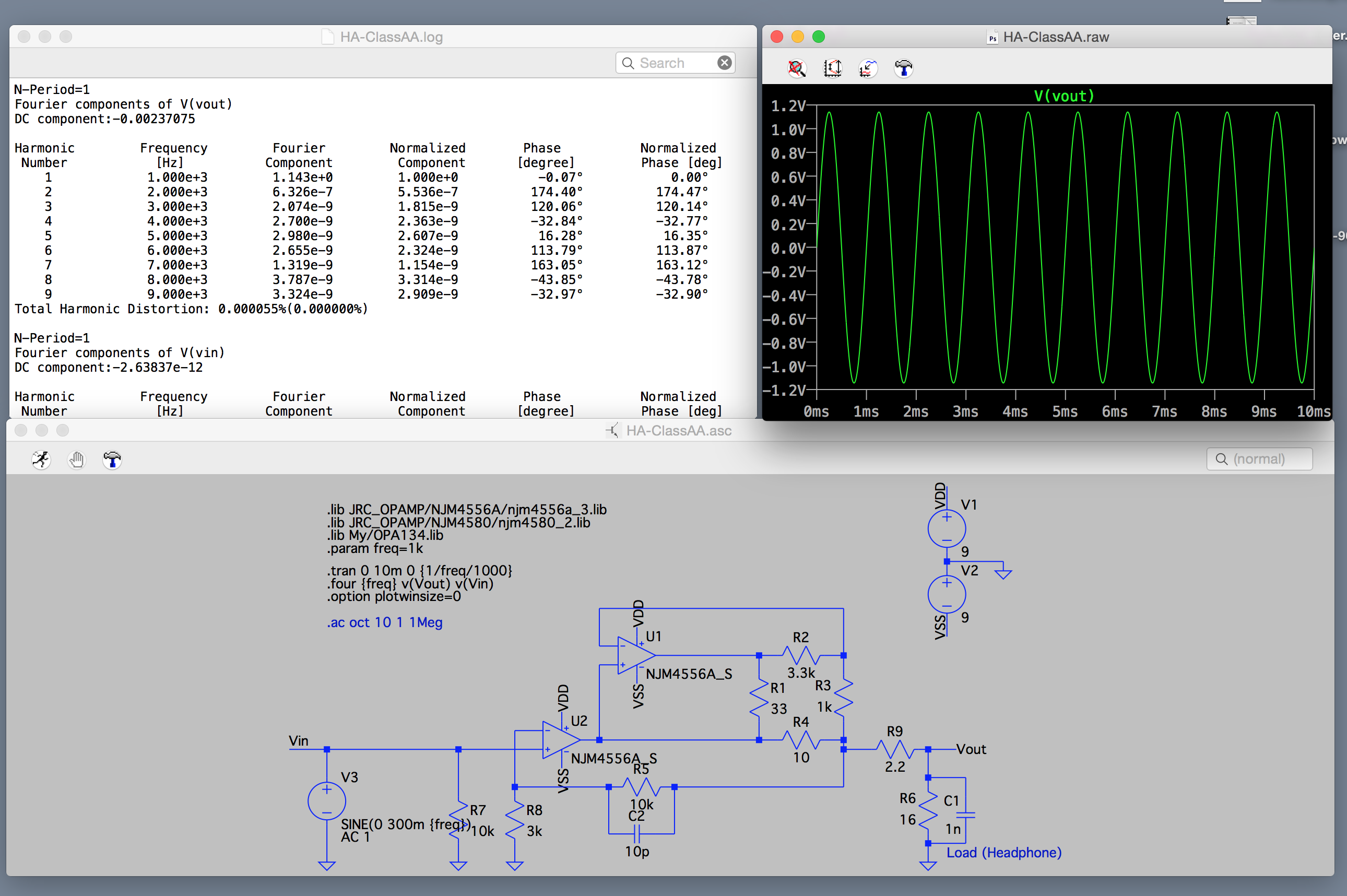
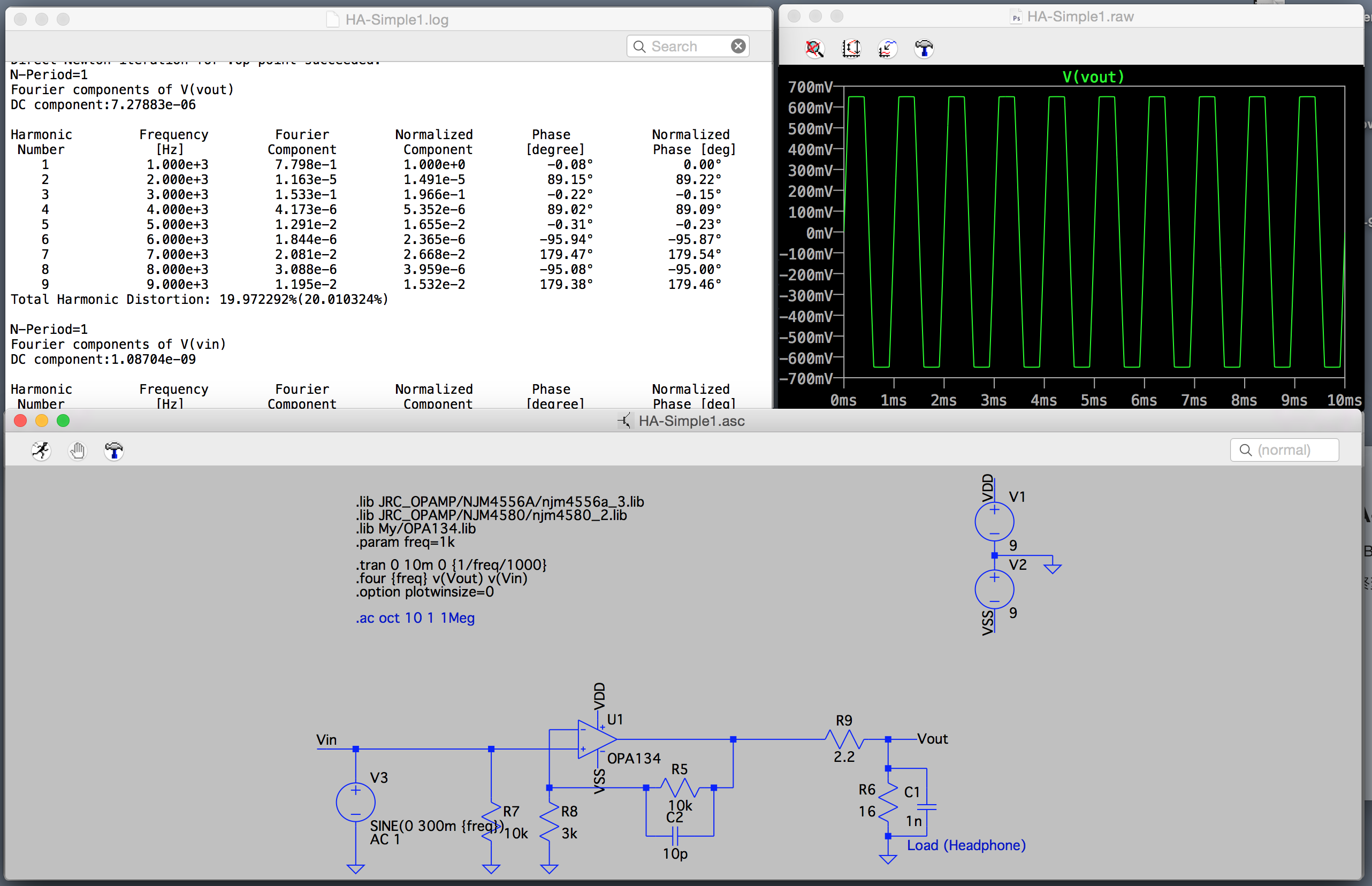
前年は技術的にはエレクトロニクス関係のスキルセットを多少上げることができたのが、自分の中では非常に大きかった。
ソフトウェア関係ではファームウェア書いてIOいじったりするのがアプリケーションレベルではできるようになったが、アルゴリズム関係が根本的に苦手なので、ファームウェアはあまり得意になれそうな気はしてない。
go 言語で自分的には実用的なアプリケーションを書いて毎日使っているので、そういうのは良かった。
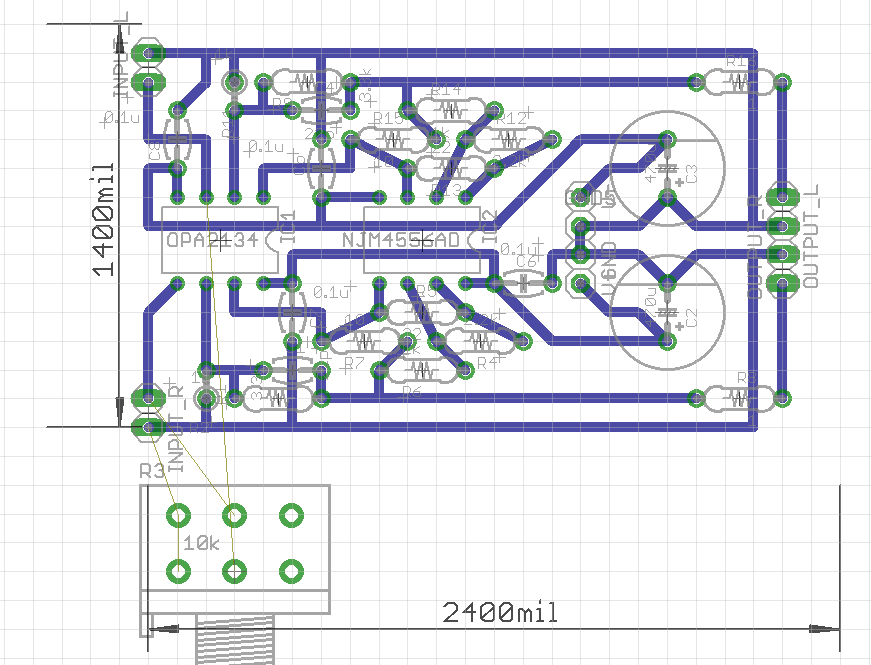
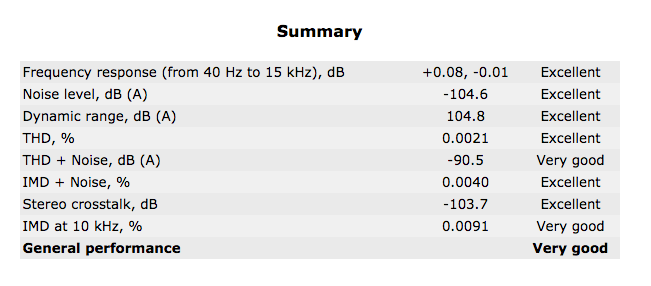
これら、残念ながら本業のウェブ開発には一切生かせていないし、ウェブ開発まわりで自分の中で技術的に進歩があったかなというのは Web Audio まわりの信号処理だけで、これまた一切仕事に生かせなさそう。
今年
抱負とか考えても、実際のところ3日も経てば忘れてしまうが思っていることだけ書いておく。
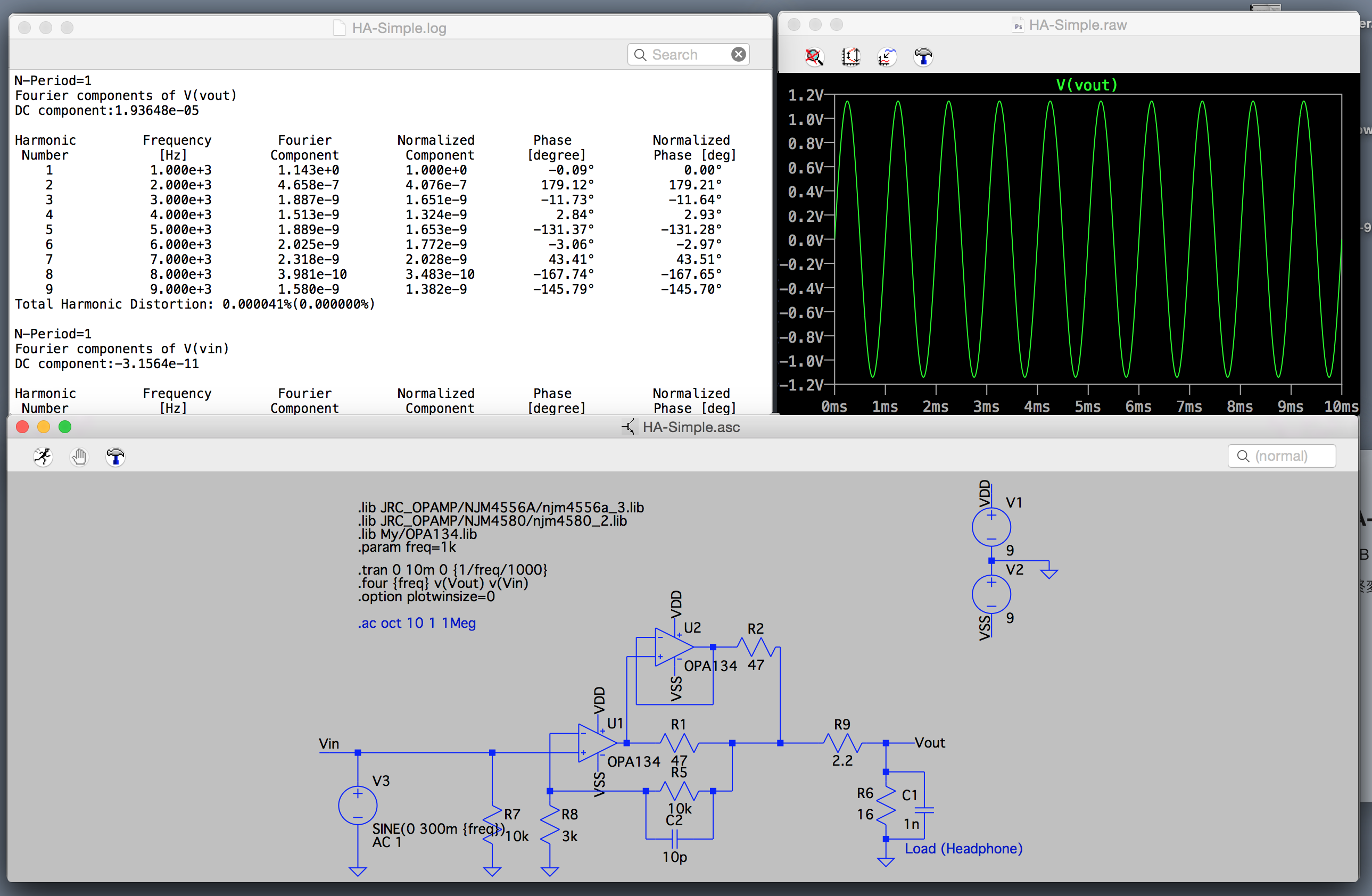
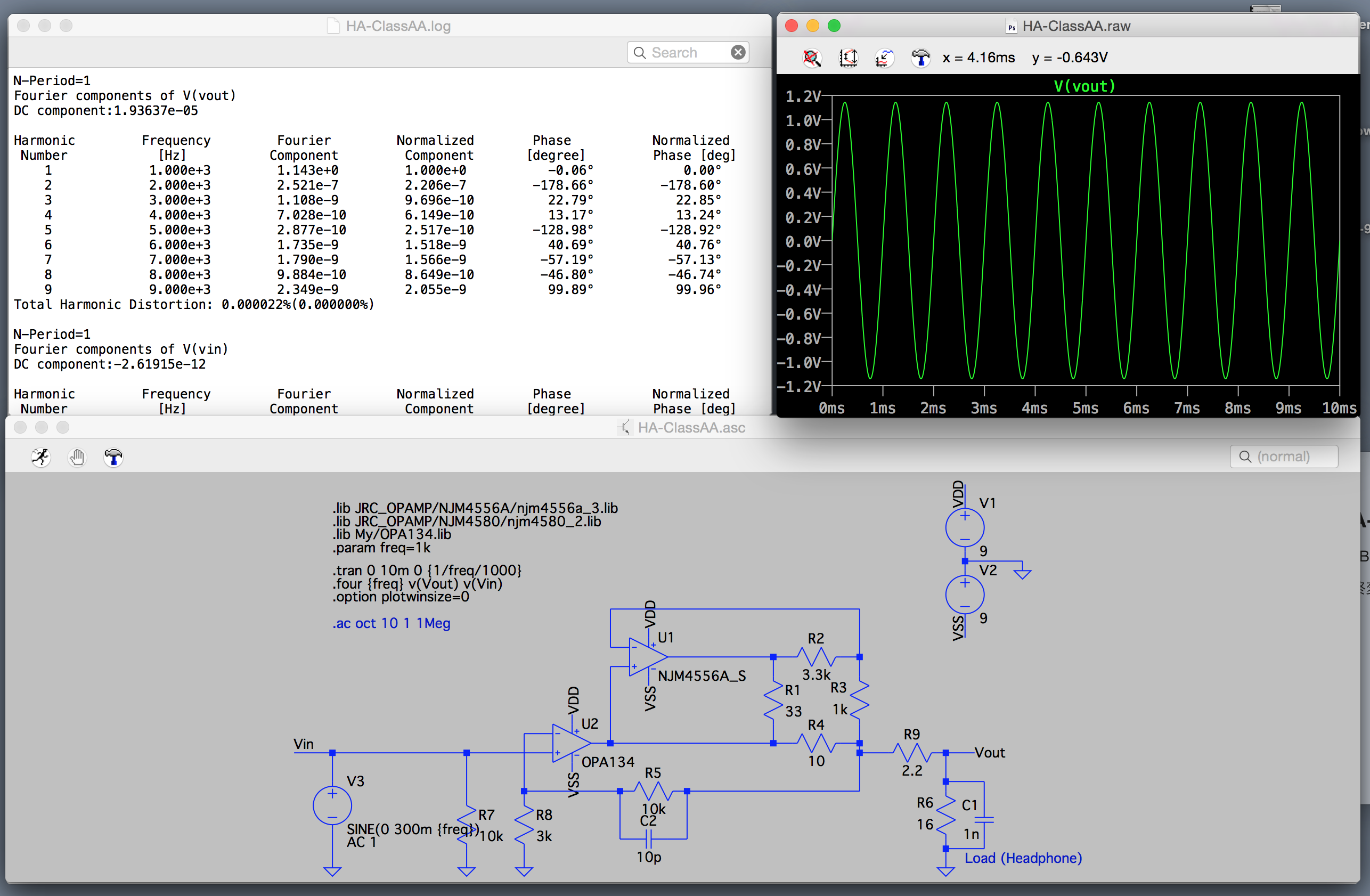
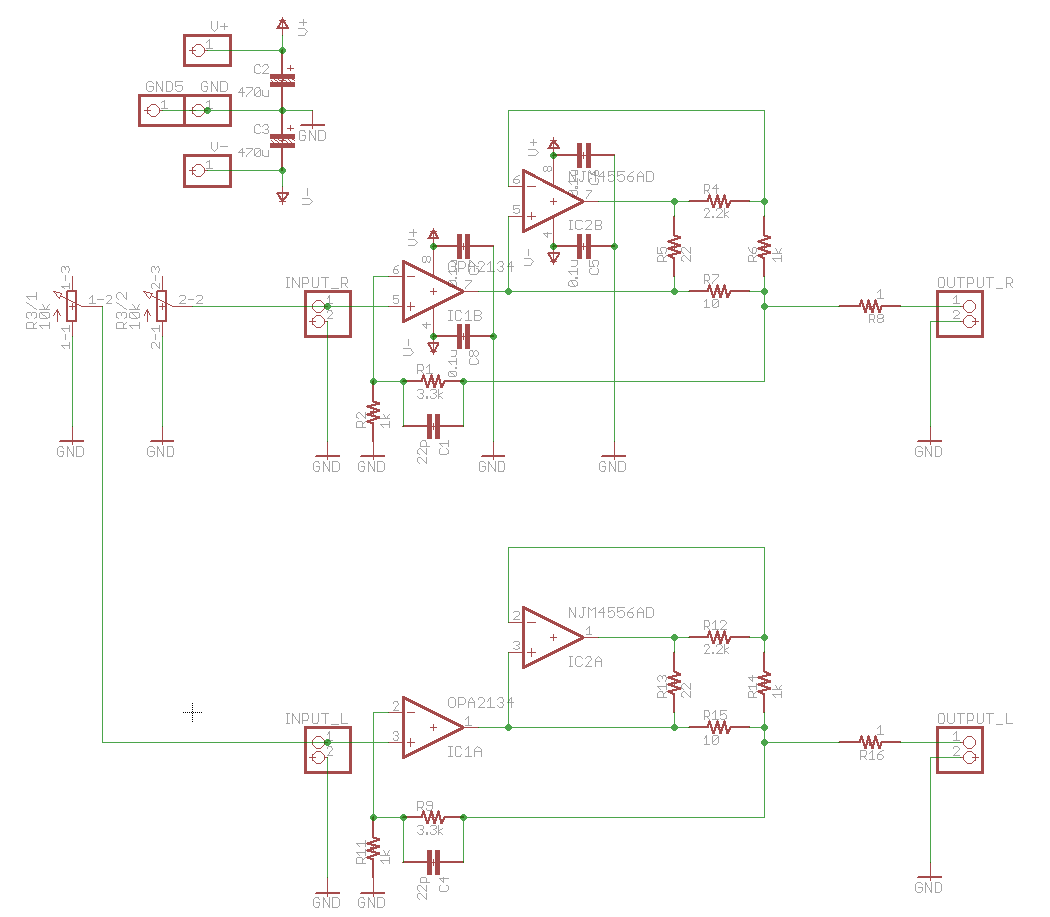
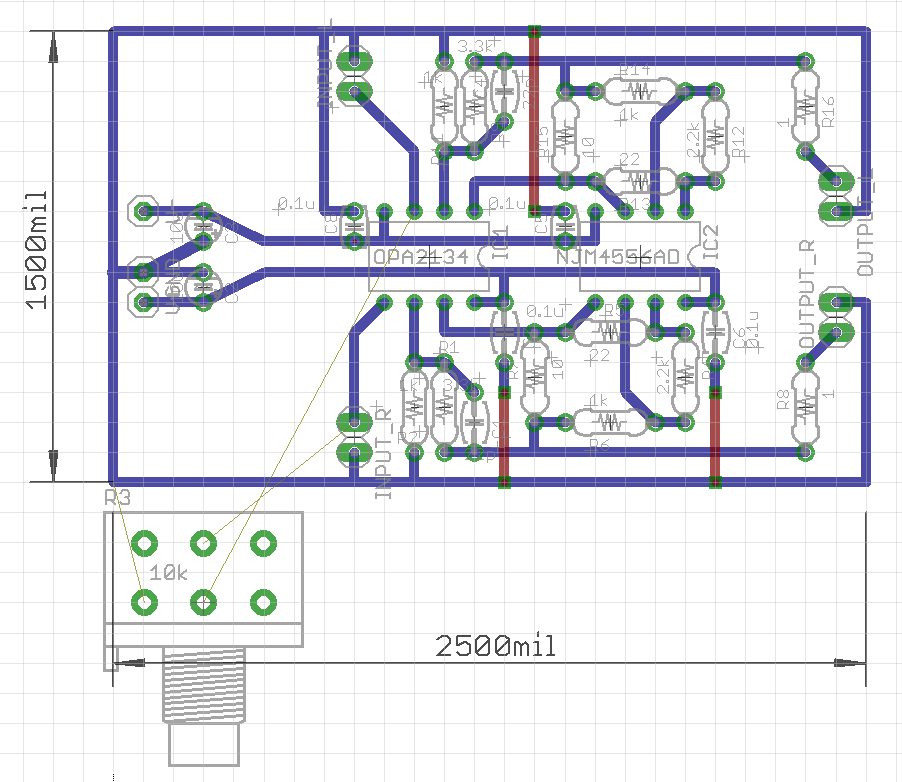
とりあえず、引き続きエレクトロニクス関係でできることを増やしたい。具体的にはアナログ回路まわりの設計を多少でもできるようになりたい。
単純に「おもしろい」という感じのことをしたい。エレクトロニクスに絡むともっと面白い気がしてるけど、それに限らずに、とにかくおもしろいことをして、おもしろいことを共有したい。
関連エントリー
- S-A-A-2 (NanoVNA V2) を手に入れてみた NanoVNA V2 という名前で開発されているが、ややこしいので開発コードである S-A-A-2 (Simple Antenna Anal...
- 自作アンテナアナライザーのBluetooth化とアプリケーション 簡単かつ安く高精度なアンテナアナライザーを自作したい | tech - 氾濫原 簡単かつ安く高精度なアンテナアナライザーを自作したい (2)...
- 中華 NanoVNA ってなんなのか? またはファームの歩きかた NanoVNA という非常に小型で低コストのスタンドアロン VNA (ベクターネットワークアナライザ) がにわかにグローバルで流行している。...
- YAPC::Asia 2013 まずやはり終わって思うのは、LTとしてすら発表しなかったのが反省だな〜 と思った。「今年 Perl 関係でおもしろいことしてないし……」と思...
- 去年のもろもろ あんまりたいしたことはできなかったなという記憶がある。特にソフトウェア方面がとても薄い。 雑感 写真とった枚数が断トツで多い年だった。そうい...